 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinite Photorealistic Worlds using Procedural Generation
Jun 26, 2023
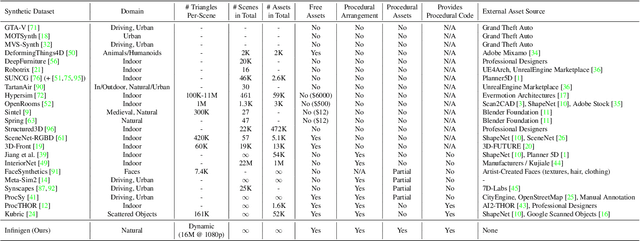


We introduce Infinigen, a procedural generator of photorealistic 3D scenes of the natural world. Infinigen is entirely procedural: every asset, from shape to texture, is generated from scratch via randomized mathematical rules, using no external source and allowing infinite variation and composition. Infinigen offers broad coverage of objects and scenes in the natural world including plants, animals, terrains, and natural phenomena such as fire, cloud, rain, and snow. Infinigen can be used to generate unlimited, diverse training data for a wide range of computer vision tasks including object detection, semantic segmentation, optical flow, and 3D reconstruction. We expect Infinigen to be a useful resource for computer vision research and beyond. Please visit https://infinigen.org for videos, code and pre-generated data.
Label-Free Synthetic Pretraining of Object Detectors
Aug 08, 2022


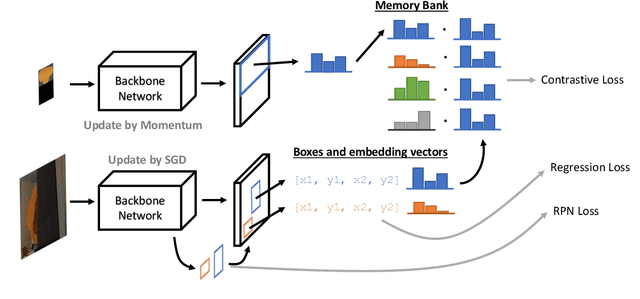
We propose a new approach, Synthetic Optimized Layout with Instance Detection (SOLID), to pretrain object detectors with synthetic images. Our "SOLID" approach consists of two main components: (1) generating synthetic images using a collection of unlabelled 3D models with optimized scene arrangement; (2) pretraining an object detector on "instance detection" task - given a query image depicting an object, detecting all instances of the exact same object in a target image. Our approach does not need any semantic labels for pretraining and allows the use of arbitrary, diverse 3D models. Experiments on COCO show that with optimized data generation and a proper pretraining task, synthetic data can be highly effective data for pretraining object detectors. In particular, pretraining on rendered images achieves performance competitive with pretraining on real images while using significantly less computing resources. Code is available at https://github.com/princeton-vl/SOLID.
Revisiting Point Cloud Shape Classification with a Simple and Effective Baseline
Jun 09, 2021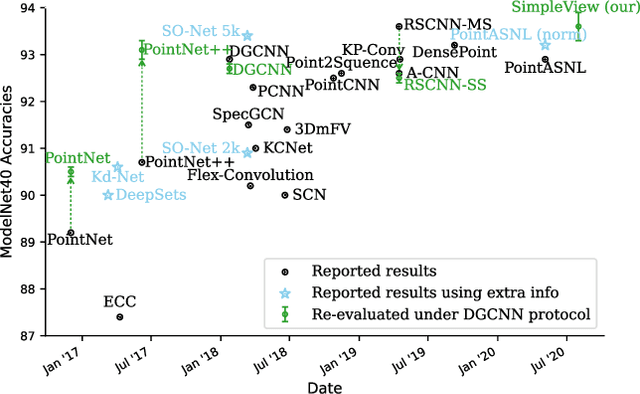

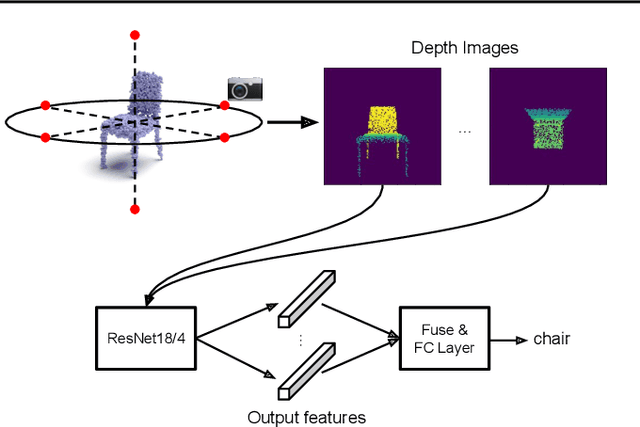
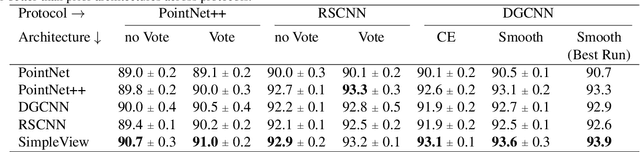
Processing point cloud data is an important component of many real-world systems. As such, a wide variety of point-based approaches have been proposed, reporting steady benchmark improvements over time. We study the key ingredients of this progress and uncover two critical results. First, we find that auxiliary factors like different evaluation schemes, data augmentation strategies, and loss functions, which are independent of the model architecture, make a large difference in performance. The differences are large enough that they obscure the effect of architecture. When these factors are controlled for, PointNet++, a relatively older network, performs competitively with recent methods. Second, a very simple projection-based method, which we refer to as SimpleView, performs surprisingly well. It achieves on par or better results than sophisticated state-of-the-art methods on ModelNet40 while being half the size of PointNet++. It also outperforms state-of-the-art methods on ScanObjectNN, a real-world point cloud benchmark, and demonstrates better cross-dataset generalization. Code is available at https://github.com/princeton-vl/SimpleView.
CornerNet-Lite: Efficient Keypoint Based Object Detection
Apr 18, 2019

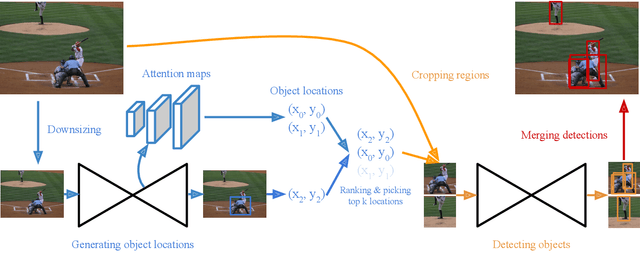

Keypoint-based methods are a relatively new paradigm in object detection, eliminating the need for anchor boxes and offering a simplified detection framework. Keypoint-based CornerNet achieves state of the art accuracy among single-stage detectors. However, this accuracy comes at high processing cost. In this work, we tackle the problem of efficient keypoint-based object detection and introduce CornerNet-Lite. CornerNet-Lite is a combination of two efficient variants of CornerNet: CornerNet-Saccade, which uses an attention mechanism to eliminate the need for exhaustively processing all pixels of the image, and CornerNet-Squeeze, which introduces a new compact backbone architecture. Together these two variants address the two critical use cases in efficient object detection: improving efficiency without sacrificing accuracy, and improving accuracy at real-time efficiency. CornerNet-Saccade is suitable for offline processing, improving the efficiency of CornerNet by 6.0x and the AP by 1.0% on COCO. CornerNet-Squeeze is suitable for real-time detection, improving both the efficiency and accuracy of the popular real-time detector YOLOv3 (34.4% AP at 34ms for CornerNet-Squeeze compared to 33.0% AP at 39ms for YOLOv3 on COCO). Together these contributions for the first time reveal the potential of keypoint-based detection to be useful for applications requiring processing efficiency.
CornerNet: Detecting Objects as Paired Keypoints
Aug 03, 2018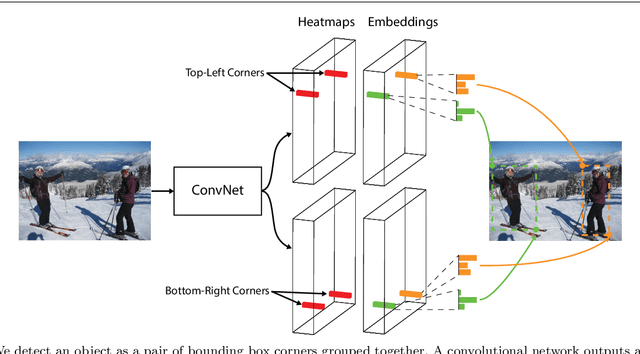



We propose CornerNet, a new approach to object detection where we detect an object bounding box as a pair of keypoints, the top-left corner and the bottom-right corner, using a single convolution neural network. By detecting objects as paired keypoints, we eliminate the need for designing a set of anchor boxes commonly used in prior single-stage detectors. In addition to our novel formulation, we introduce corner pooling, a new type of pooling layer that helps the network better localize corners. Experiments show that CornerNet achieves a 42.1% AP on MS COCO, outperforming all existing one-stage detectors.
1-HKUST: Object Detection in ILSVRC 2014
Oct 05, 2014



The Imagenet Large Scale Visual Recognition Challenge (ILSVRC) is the one of the most important big data challenges to date. We participated in the object detection track of ILSVRC 2014 and received the fourth place among the 38 teams. We introduce in our object detection system a number of novel techniques in localization and recognition. For localization, initial candidate proposals are generated using selective search, and a novel bounding boxes regression method is used for better object localization. For recognition, to represent a candidate proposal, we adopt three features, namely, RCNN feature, IFV feature, and DPM feature. Given these features, category-specific combination functions are learned to improve the object recognition rate. In addition, object context in the form of background priors and object interaction priors are learned and applied in our system. Our ILSVRC 2014 results are reported alongside with the results of other participating teams.