 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisionPulse: Dynamic Visual Sparsity for Efficient Multimodal Reasoning
May 29, 2026With the rapid advancement of large multimodal models (LMMs), inference-time overhead has become a key bottleneck for real-world deployment. Existing methods typically prune visual tokens at prefill, assuming the required visual evidence remains static during reasoning. However, we empirically show that visual evidence is strongly step-dependent: only a sparse subset of visual tokens is critical at each decoding step, and the critical set evolves across reasoning. Furthermore, we identify a coupled bottleneck where redundant visual context can steer the model toward query-irrelevant regions, lengthening the reasoning trace. Guided by these insights, we propose VisionPulse, a step-wise visual token pruning framework during reasoning. VisionPulse computes a lightweight visual attention mass to estimate the step-wise retention budget by exploiting its strong positive correlation with LMMs' effective visual token usage and retain only the most critical tokens under this budget. By enforcing visual sparsity during reasoning, VisionPulse filters redundant visual context while preserving relevant visual evidence, shortening reasoning traces naturally. Extensive experiments show that VisionPulse only retains 5% of visual tokens per step with reasoning traces shortened by 11.2%, while keeping accuracy almost unchanged.
SVSR: A Self-Verification and Self-Rectification Paradigm for Multimodal Reasoning
Apr 11, 2026Current multimodal models often suffer from shallow reasoning, leading to errors caused by incomplete or inconsistent thought processes. To address this limitation, we propose Self-Verification and Self-Rectification (SVSR), a unified framework that explicitly integrates self-verification and self-rectification into the model's reasoning pipeline, substantially improving robustness and reliability in complex visual understanding and multimodal reasoning tasks. SVSR is built on a novel three-stage training paradigm. First, we construct a high-quality unified preference dataset by refining reasoning traces from pre-trained vision-language models, incorporating both forward and backward reasoning to embed self-reflective signals. Second, we perform cold-start supervised fine-tuning on this dataset to learn structured, multi-step reasoning behaviors. Third, we apply a Semi-online Direct Preference Optimization (Semi-online DPO) process, continuously augmenting the training corpus with high-quality, model-generated reasoning traces filtered by a powerful teacher VLM. This pipeline enables the model to learn, elicit, and refine its ability to self-verify and self-rectify. Extensive experiments across diverse benchmarks demonstrate that SVSR improves reasoning accuracy and enables stronger generalization to unseen tasks and question types. Notably, once trained with explicit self-reflective reasoning, the model also exhibits improved implicit reasoning ability, outperforming strong baselines even when no explicit reasoning traces are provided. These results highlight the potential of SVSR for building more dependable, introspective, and cognitively aligned multimodal systems.
Cognitive Pivot Points and Visual Anchoring: Unveiling and Rectifying Hallucinations in Multimodal Reasoning Models
Apr 11, 2026Multimodal Large Reasoning Models (MLRMs) have achieved remarkable strides in visual reasoning through test time compute scaling, yet long chain reasoning remains prone to hallucinations. We identify a concerning phenomenon termed the Reasoning Vision Truth Disconnect (RVTD): hallucinations are strongly correlated with cognitive bifurcation points that often exhibit high entropy states. We attribute this vulnerability to a breakdown in visual semantic anchoring, localized within the network's intermediate layers; specifically, during these high uncertainty transitions, the model fails to query visual evidence, reverting instead to language priors. Consequently, we advocate a shift from solely outcome level supervision to augmenting it with fine grained internal attention guidance. To this end, we propose V-STAR (Visual Structural Training with Attention Reinforcement), a lightweight, holistic training paradigm designed to internalize visually aware reasoning capabilities. Central to our approach is the Hierarchical Visual Attention Reward (HVAR), integrated within the GRPO framework. Upon detecting high entropy states, this mechanism dynamically incentivizes visual attention across critical intermediate layers, thereby anchoring the reasoning process back to the visual input. Furthermore, we introduce the Forced Reflection Mechanism (FRM), a trajectory editing strategy that disrupts cognitive inertia by triggering reflection around high entropy cognitive bifurcation points and encouraging verification of subsequent steps against the visual input, thereby translating external debiasing interventions into an intrinsic capability for hallucination mitigation.
ScDiVa: Masked Discrete Diffusion for Joint Modeling of Single-Cell Identity and Expression
Feb 03, 2026Single-cell RNA-seq profiles are high-dimensional, sparse, and unordered, causing autoregressive generation to impose an artificial ordering bias and suffer from error accumulation. To address this, we propose scDiVa, a masked discrete diffusion foundation model that aligns generation with the dropout-like corruption process by defining a continuous-time forward masking mechanism in token space. ScDiVa features a bidirectional denoiser that jointly models discrete gene identities and continuous values, utilizing entropy-normalized serialization and a latent anchor token to maximize information efficiency and preserve global cell identity. The model is trained via depth-invariant time sampling and a dual denoising objective to simulate varying sparsity levels while ensuring precise recovery of both identity and magnitude. Pre-trained on 59 million cells, scDiVa achieves strong transfer performance across major benchmarks, including batch integration, cell type annotation, and perturbation response prediction. These results suggest that masked discrete diffusion serves as a biologically coherent and effective alternative to autoregression.
MathDoc: Benchmarking Structured Extraction and Active Refusal on Noisy Mathematics Exam Papers
Jan 15, 2026The automated extraction of structured questions from paper-based mathematics exams is fundamental to intelligent education, yet remains challenging in real-world settings due to severe visual noise. Existing benchmarks mainly focus on clean documents or generic layout analysis, overlooking both the structural integrity of mathematical problems and the ability of models to actively reject incomplete inputs. We introduce MathDoc, the first benchmark for document-level information extraction from authentic high school mathematics exam papers. MathDoc contains \textbf{3,609} carefully curated questions with real-world artifacts and explicitly includes unrecognizable samples to evaluate active refusal behavior. We propose a multi-dimensional evaluation framework covering stem accuracy, visual similarity, and refusal capability. Experiments on SOTA MLLMs, including Qwen3-VL and Gemini-2.5-Pro, show that although end-to-end models achieve strong extraction performance, they consistently fail to refuse illegible inputs, instead producing confident but invalid outputs. These results highlight a critical gap in current MLLMs and establish MathDoc as a benchmark for assessing model reliability under degraded document conditions. Our project repository is available at \href{https://github.com/winnk123/papers/tree/master}{GitHub repository}
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
ReViSE: Towards Reason-Informed Video Editing in Unified Models with Self-Reflective Learning
Dec 11, 2025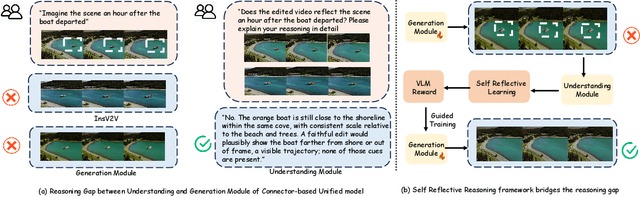
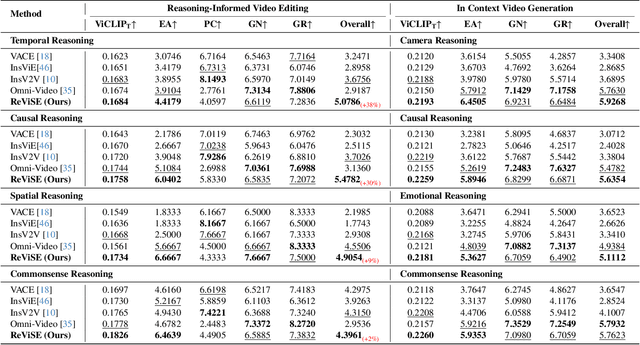

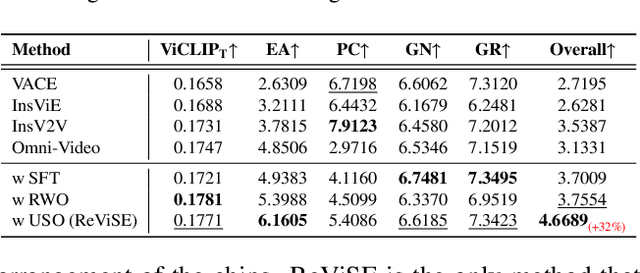
Video unified models exhibit strong capabilities in understanding and generation, yet they struggle with reason-informed visual editing even when equipped with powerful internal vision-language models (VLMs). We attribute this gap to two factors: 1) existing datasets are inadequate for training and evaluating reasoning-aware video editing, and 2) an inherent disconnect between the models' reasoning and editing capabilities, which prevents the rich understanding from effectively instructing the editing process. Bridging this gap requires an integrated framework that connects reasoning with visual transformation. To address this gap, we introduce the Reason-Informed Video Editing (RVE) task, which requires reasoning about physical plausibility and causal dynamics during editing. To support systematic evaluation, we construct RVE-Bench, a comprehensive benchmark with two complementary subsets: Reasoning-Informed Video Editing and In-Context Video Generation. These subsets cover diverse reasoning dimensions and real-world editing scenarios. Building upon this foundation, we propose the ReViSE, a Self-Reflective Reasoning (SRF) framework that unifies generation and evaluation within a single architecture. The model's internal VLM provides intrinsic feedback by assessing whether the edited video logically satisfies the given instruction. The differential feedback that refines the generator's reasoning behavior during training. Extensive experiments on RVE-Bench demonstrate that ReViSE significantly enhances editing accuracy and visual fidelity, achieving a 32% improvement of the Overall score in the reasoning-informed video editing subset over state-of-the-art methods.
Geometric Prior-Guided Federated Prompt Calibration
Dec 08, 2025Federated Prompt Learning (FPL) offers a parameter-efficient solution for collaboratively training large models, but its performance is severely hindered by data heterogeneity, which causes locally trained prompts to become biased. Existing methods, focusing on aggregation or regularization, fail to address this root cause of local training bias. To this end, we propose Geometry-Guided Text Prompt Calibration (GGTPC), a novel framework that directly corrects this bias by providing clients with a global geometric prior. This prior, representing the shape of the global data distribution derived from the covariance matrix, is reconstructed on the server in a privacy-preserving manner. Clients then use a novel Geometry-Prior Calibration Layer (GPCL) to align their local feature distributions with this global prior during training. Extensive experiments show GGTPC's effectiveness. On the label-skewed CIFAR-100 dataset ($β$=0.1), it outperforms the state-of-the-art by 2.15\%. Under extreme skew ($β$=0.01), it improves upon the baseline by 9.17\%. Furthermore, as a plug-and-play module on the domain-skewed Office-Home dataset, it boosts FedAvg's performance by 4.60\%. These results demonstrate that GGTPC effectively mitigates data heterogeneity by correcting the fundamental local training bias, serving as a versatile module to enhance various FL algorithms.
RoboAfford++: A Generative AI-Enhanced Dataset for Multimodal Affordance Learning in Robotic Manipulation and Navigation
Nov 16, 2025Robotic manipulation and navigation are fundamental capabilities of embodied intelligence, enabling effective robot interactions with the physical world. Achieving these capabilities requires a cohesive understanding of the environment, including object recognition to localize target objects, object affordances to identify potential interaction areas and spatial affordances to discern optimal areas for both object placement and robot movement. While Vision-Language Models (VLMs) excel at high-level task planning and scene understanding, they often struggle to infer actionable positions for physical interaction, such as functional grasping points and permissible placement regions. This limitation stems from the lack of fine-grained annotations for object and spatial affordances in their training datasets. To tackle this challenge, we introduce RoboAfford++, a generative AI-enhanced dataset for multimodal affordance learning for both robotic manipulation and navigation. Our dataset comprises 869,987 images paired with 2.0 million question answering (QA) annotations, covering three critical tasks: object affordance recognition to identify target objects based on attributes and spatial relationships, object affordance prediction to pinpoint functional parts for manipulation, and spatial affordance localization to identify free space for object placement and robot navigation. Complementing this dataset, we propose RoboAfford-Eval, a comprehensive benchmark for assessing affordance-aware prediction in real-world scenarios, featuring 338 meticulously annotated samples across the same three tasks. Extensive experimental results reveal the deficiencies of existing VLMs in affordance learning, while fine-tuning on the RoboAfford++ dataset significantly enhances their ability to reason about object and spatial affordances, validating the dataset's effectiveness.
Robust Graph Condensation via Classification Complexity Mitigation
Oct 30, 2025Graph condensation (GC) has gained significant attention for its ability to synthesize smaller yet informative graphs. However, existing studies often overlook the robustness of GC in scenarios where the original graph is corrupted. In such cases, we observe that the performance of GC deteriorates significantly, while existing robust graph learning technologies offer only limited effectiveness. Through both empirical investigation and theoretical analysis, we reveal that GC is inherently an intrinsic-dimension-reducing process, synthesizing a condensed graph with lower classification complexity. Although this property is critical for effective GC performance, it remains highly vulnerable to adversarial perturbations. To tackle this vulnerability and improve GC robustness, we adopt the geometry perspective of graph data manifold and propose a novel Manifold-constrained Robust Graph Condensation framework named MRGC. Specifically, we introduce three graph data manifold learning modules that guide the condensed graph to lie within a smooth, low-dimensional manifold with minimal class ambiguity, thereby preserving the classification complexity reduction capability of GC and ensuring robust performance under universal adversarial attacks. Extensive experiments demonstrate the robustness of \ModelName\ across diverse attack scenarios.