 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextRefine-CLIP for EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2025
Jun 12, 2025This report presents ContextRefine-CLIP (CR-CLIP), an efficient model for visual-textual multi-instance retrieval tasks. The approach is based on the dual-encoder AVION, on which we introduce a cross-modal attention flow module to achieve bidirectional dynamic interaction and refinement between visual and textual features to generate more context-aware joint representations. For soft-label relevance matrices provided in tasks such as EPIC-KITCHENS-100, CR-CLIP can work with Symmetric Multi-Similarity Loss to achieve more accurate semantic alignment and optimization using the refined features. Without using ensemble learning, the CR-CLIP model achieves 66.78mAP and 82.08nDCG on the EPIC-KITCHENS-100 public leaderboard, which significantly outperforms the baseline model and fully validates its effectiveness in cross-modal retrieval. The code will be released open-source on https://github.com/delCayr/ContextRefine-Clip
Logits DeConfusion with CLIP for Few-Shot Learning
Apr 16, 2025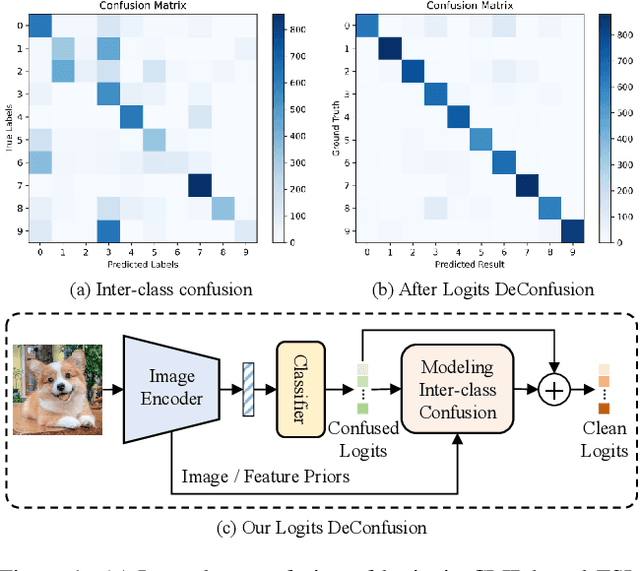
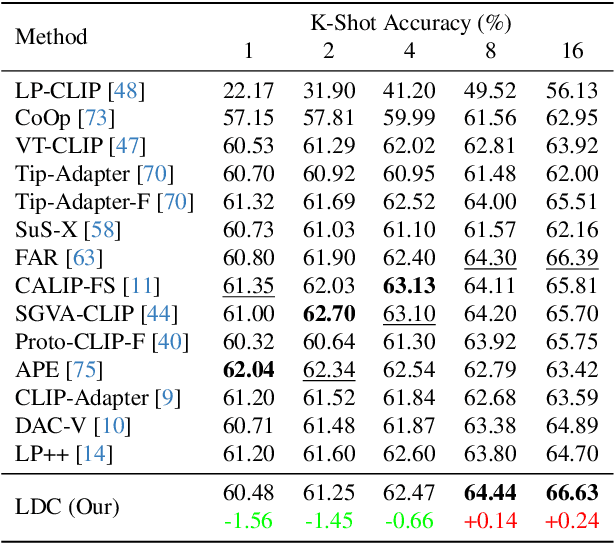
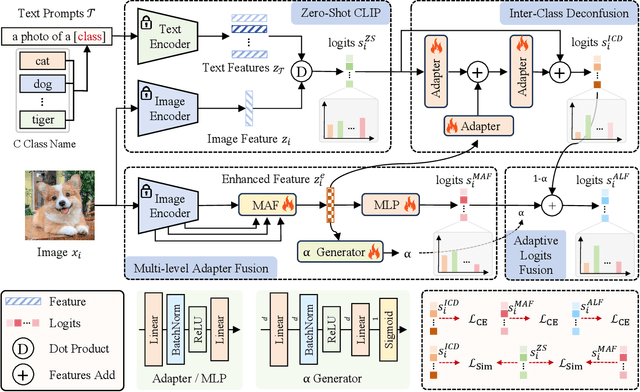
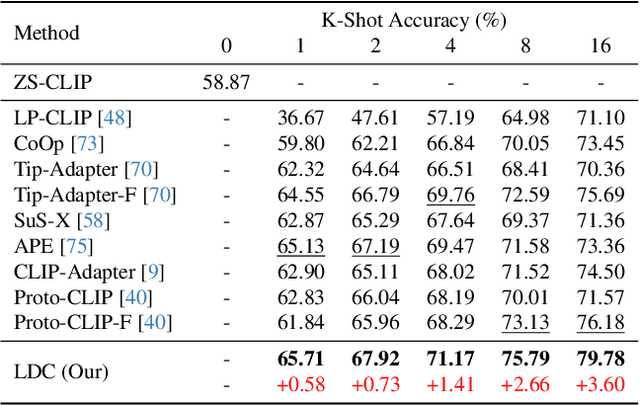
With its powerful visual-language alignment capability, CLIP performs well in zero-shot and few-shot learning tasks. However, we found in experiments that CLIP's logits suffer from serious inter-class confusion problems in downstream tasks, and the ambiguity between categories seriously affects the accuracy. To address this challenge, we propose a novel method called Logits DeConfusion, which effectively learns and eliminates inter-class confusion in logits by combining our Multi-level Adapter Fusion (MAF) module with our Inter-Class Deconfusion (ICD) module. Our MAF extracts features from different levels and fuses them uniformly to enhance feature representation. Our ICD learnably eliminates inter-class confusion in logits with a residual structure. Experimental results show that our method can significantly improve the classification performance and alleviate the inter-class confusion problem. The code is available at https://github.com/LiShuo1001/LDC.
MASSeg : 2nd Technical Report for 4th PVUW MOSE Track
Apr 14, 2025Complex video object segmentation continues to face significant challenges in small object recognition, occlusion handling, and dynamic scene modeling. This report presents our solution, which ranked second in the MOSE track of CVPR 2025 PVUW Challenge. Based on an existing segmentation framework, we propose an improved model named MASSeg for complex video object segmentation, and construct an enhanced dataset, MOSE+, which includes typical scenarios with occlusions, cluttered backgrounds, and small target instances. During training, we incorporate a combination of inter-frame consistent and inconsistent data augmentation strategies to improve robustness and generalization. During inference, we design a mask output scaling strategy to better adapt to varying object sizes and occlusion levels. As a result, MASSeg achieves a J score of 0.8250, F score of 0.9007, and a J&F score of 0.8628 on the MOSE test set.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
Multiplane Prior Guided Few-Shot Aerial Scene Rendering
Jun 07, 2024



Neural Radiance Fields (NeRF) have been successfully applied in various aerial scenes, yet they face challenges with sparse views due to limited supervision. The acquisition of dense aerial views is often prohibitive, as unmanned aerial vehicles (UAVs) may encounter constraints in perspective range and energy constraints. In this work, we introduce Multiplane Prior guided NeRF (MPNeRF), a novel approach tailored for few-shot aerial scene rendering-marking a pioneering effort in this domain. Our key insight is that the intrinsic geometric regularities specific to aerial imagery could be leveraged to enhance NeRF in sparse aerial scenes. By investigating NeRF's and Multiplane Image (MPI)'s behavior, we propose to guide the training process of NeRF with a Multiplane Prior. The proposed Multiplane Prior draws upon MPI's benefits and incorporates advanced image comprehension through a SwinV2 Transformer, pre-trained via SimMIM. Our extensive experiments demonstrate that MPNeRF outperforms existing state-of-the-art methods applied in non-aerial contexts, by tripling the performance in SSIM and LPIPS even with three views available. We hope our work offers insights into the development of NeRF-based applications in aerial scenes with limited data.
* 17 pages, 8 figures, accepted at CVPR 2024
Unveiling and Mitigating Generalized Biases of DNNs through the Intrinsic Dimensions of Perceptual Manifolds
Apr 22, 2024



Building fair deep neural networks (DNNs) is a crucial step towards achieving trustworthy artificial intelligence. Delving into deeper factors that affect the fairness of DNNs is paramount and serves as the foundation for mitigating model biases. However, current methods are limited in accurately predicting DNN biases, relying solely on the number of training samples and lacking more precise measurement tools. Here, we establish a geometric perspective for analyzing the fairness of DNNs, comprehensively exploring how DNNs internally shape the intrinsic geometric characteristics of datasets-the intrinsic dimensions (IDs) of perceptual manifolds, and the impact of IDs on the fairness of DNNs. Based on multiple findings, we propose Intrinsic Dimension Regularization (IDR), which enhances the fairness and performance of models by promoting the learning of concise and ID-balanced class perceptual manifolds. In various image recognition benchmark tests, IDR significantly mitigates model bias while improving its performance.
Geometric Prior Guided Feature Representation Learning for Long-Tailed Classification
Jan 21, 2024Real-world data are long-tailed, the lack of tail samples leads to a significant limitation in the generalization ability of the model. Although numerous approaches of class re-balancing perform well for moderate class imbalance problems, additional knowledge needs to be introduced to help the tail class recover the underlying true distribution when the observed distribution from a few tail samples does not represent its true distribution properly, thus allowing the model to learn valuable information outside the observed domain. In this work, we propose to leverage the geometric information of the feature distribution of the well-represented head class to guide the model to learn the underlying distribution of the tail class. Specifically, we first systematically define the geometry of the feature distribution and the similarity measures between the geometries, and discover four phenomena regarding the relationship between the geometries of different feature distributions. Then, based on four phenomena, feature uncertainty representation is proposed to perturb the tail features by utilizing the geometry of the head class feature distribution. It aims to make the perturbed features cover the underlying distribution of the tail class as much as possible, thus improving the model's generalization performance in the test domain. Finally, we design a three-stage training scheme enabling feature uncertainty modeling to be successfully applied. Experiments on CIFAR-10/100-LT, ImageNet-LT, and iNaturalist2018 show that our proposed approach outperforms other similar methods on most metrics. In addition, the experimental phenomena we discovered are able to provide new perspectives and theoretical foundations for subsequent studies.
Data-Centric Long-Tailed Image Recognition
Nov 03, 2023In the context of the long-tail scenario, models exhibit a strong demand for high-quality data. Data-centric approaches aim to enhance both the quantity and quality of data to improve model performance. Among these approaches, information augmentation has been progressively introduced as a crucial category. It achieves a balance in model performance by augmenting the richness and quantity of samples in the tail classes. However, there is currently a lack of research into the underlying mechanisms explaining the effectiveness of information augmentation methods. Consequently, the utilization of information augmentation in long-tail recognition tasks relies heavily on empirical and intricate fine-tuning. This work makes two primary contributions. Firstly, we approach the problem from the perspectives of feature diversity and distribution shift, introducing the concept of Feature Diversity Gain (FDG) to elucidate why information augmentation is effective. We find that the performance of information augmentation can be explained by FDG, and its performance peaks when FDG achieves an appropriate balance. Experimental results demonstrate that by using FDG to select augmented data, we can further enhance model performance without the need for any modifications to the model's architecture. Thus, data-centric approaches hold significant potential in the field of long-tail recognition, beyond the development of new model structures. Furthermore, we systematically introduce the core components and fundamental tasks of a data-centric long-tail learning framework for the first time. These core components guide the implementation and deployment of the system, while the corresponding fundamental tasks refine and expand the research area.