 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
A Diff-Attention Aware State Space Fusion Model for Remote Sensing Classification
Apr 23, 2025Multispectral (MS) and panchromatic (PAN) images describe the same land surface, so these images not only have their own advantages, but also have a lot of similar information. In order to separate these similar information and their respective advantages, reduce the feature redundancy in the fusion stage. This paper introduces a diff-attention aware state space fusion model (DAS2F-Model) for multimodal remote sensing image classification. Based on the selective state space model, a cross-modal diff-attention module (CMDA-Module) is designed to extract and separate the common features and their respective dominant features of MS and PAN images. Among this, space preserving visual mamba (SPVM) retains image spatial features and captures local features by optimizing visual mamba's input reasonably. Considering that features in the fusion stage will have large semantic differences after feature separation and simple fusion operations struggle to effectively integrate these significantly different features, an attention-aware linear fusion module (AALF-Module) is proposed. It performs pixel-wise linear fusion by calculating influence coefficients. This mechanism can fuse features with large semantic differences while keeping the feature size unchanged. Empirical evaluations indicate that the presented method achieves better results than alternative approaches. The relevant code can be found at:https://github.com/AVKSKVL/DAS-F-Model
Logits DeConfusion with CLIP for Few-Shot Learning
Apr 16, 2025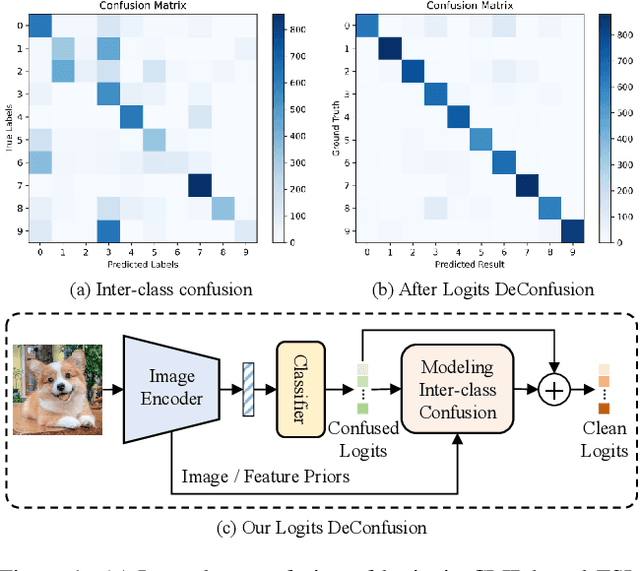
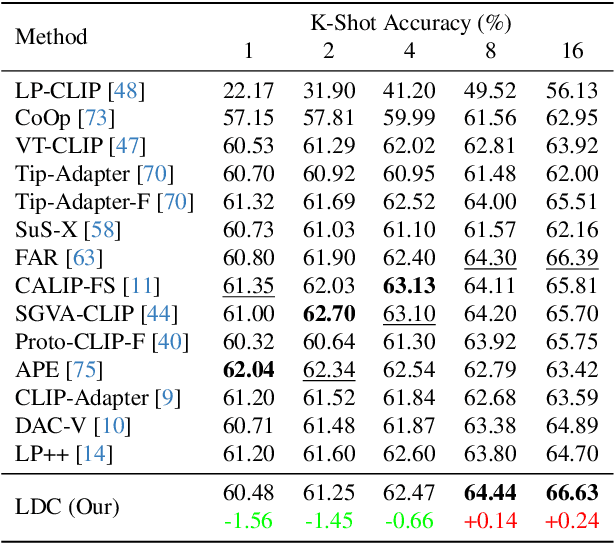
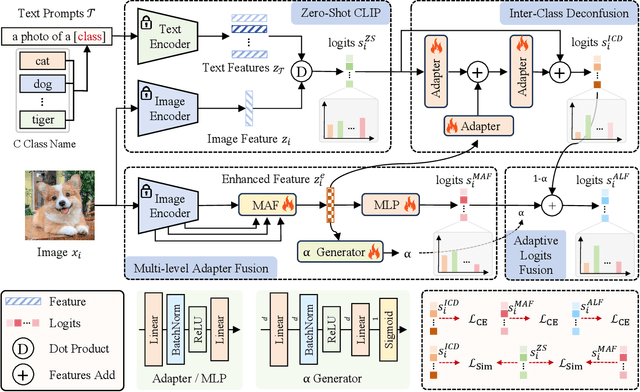
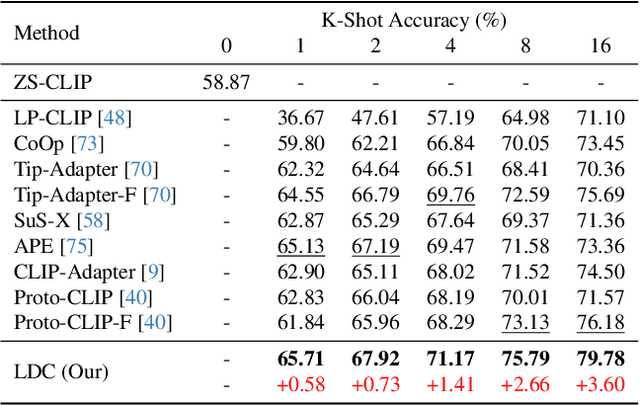
With its powerful visual-language alignment capability, CLIP performs well in zero-shot and few-shot learning tasks. However, we found in experiments that CLIP's logits suffer from serious inter-class confusion problems in downstream tasks, and the ambiguity between categories seriously affects the accuracy. To address this challenge, we propose a novel method called Logits DeConfusion, which effectively learns and eliminates inter-class confusion in logits by combining our Multi-level Adapter Fusion (MAF) module with our Inter-Class Deconfusion (ICD) module. Our MAF extracts features from different levels and fuses them uniformly to enhance feature representation. Our ICD learnably eliminates inter-class confusion in logits with a residual structure. Experimental results show that our method can significantly improve the classification performance and alleviate the inter-class confusion problem. The code is available at https://github.com/LiShuo1001/LDC.
MASSeg : 2nd Technical Report for 4th PVUW MOSE Track
Apr 14, 2025Complex video object segmentation continues to face significant challenges in small object recognition, occlusion handling, and dynamic scene modeling. This report presents our solution, which ranked second in the MOSE track of CVPR 2025 PVUW Challenge. Based on an existing segmentation framework, we propose an improved model named MASSeg for complex video object segmentation, and construct an enhanced dataset, MOSE+, which includes typical scenarios with occlusions, cluttered backgrounds, and small target instances. During training, we incorporate a combination of inter-frame consistent and inconsistent data augmentation strategies to improve robustness and generalization. During inference, we design a mask output scaling strategy to better adapt to varying object sizes and occlusion levels. As a result, MASSeg achieves a J score of 0.8250, F score of 0.9007, and a J&F score of 0.8628 on the MOSE test set.
Triple Point Masking
Sep 26, 2024Existing 3D mask learning methods encounter performance bottlenecks under limited data, and our objective is to overcome this limitation. In this paper, we introduce a triple point masking scheme, named TPM, which serves as a scalable framework for pre-training of masked autoencoders to achieve multi-mask learning for 3D point clouds. Specifically, we augment the baselines with two additional mask choices (i.e., medium mask and low mask) as our core insight is that the recovery process of an object can manifest in diverse ways. Previous high-masking schemes focus on capturing the global representation but lack the fine-grained recovery capability, so that the generated pre-trained weights tend to play a limited role in the fine-tuning process. With the support of the proposed TPM, available methods can exhibit more flexible and accurate completion capabilities, enabling the potential autoencoder in the pre-training stage to consider multiple representations of a single 3D object. In addition, an SVM-guided weight selection module is proposed to fill the encoder parameters for downstream networks with the optimal weight during the fine-tuning stage, maximizing linear accuracy and facilitating the acquisition of intricate representations for new objects. Extensive experiments show that the four baselines equipped with the proposed TPM achieve comprehensive performance improvements on various downstream tasks.
Fast and Efficient: Mask Neural Fields for 3D Scene Segmentation
Jul 01, 2024



Understanding 3D scenes is a crucial challenge in computer vision research with applications spanning multiple domains. Recent advancements in distilling 2D vision-language foundation models into neural fields, like NeRF and 3DGS, enables open-vocabulary segmentation of 3D scenes from 2D multi-view images without the need for precise 3D annotations. While effective, however, the per-pixel distillation of high-dimensional CLIP features introduces ambiguity and necessitates complex regularization strategies, adding inefficiencies during training. This paper presents MaskField, which enables fast and efficient 3D open-vocabulary segmentation with neural fields under weak supervision. Unlike previous methods, MaskField distills masks rather than dense high-dimensional CLIP features. MaskFields employ neural fields as binary mask generators and supervise them with masks generated by SAM and classified by coarse CLIP features. MaskField overcomes the ambiguous object boundaries by naturally introducing SAM segmented object shapes without extra regularization during training. By circumventing the direct handling of high-dimensional CLIP features during training, MaskField is particularly compatible with explicit scene representations like 3DGS. Our extensive experiments show that MaskField not only surpasses prior state-of-the-art methods but also achieves remarkably fast convergence, outperforming previous methods with just 5 minutes of training. We hope that MaskField will inspire further exploration into how neural fields can be trained to comprehend 3D scenes from 2D models.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
Edit-Your-Motion: Space-Time Diffusion Decoupling Learning for Video Motion Editing
May 07, 2024



Existing diffusion-based video editing methods have achieved impressive results in motion editing. Most of the existing methods focus on the motion alignment between the edited video and the reference video. However, these methods do not constrain the background and object content of the video to remain unchanged, which makes it possible for users to generate unexpected videos. In this paper, we propose a one-shot video motion editing method called Edit-Your-Motion that requires only a single text-video pair for training. Specifically, we design the Detailed Prompt-Guided Learning Strategy (DPL) to decouple spatio-temporal features in space-time diffusion models. DPL separates learning object content and motion into two training stages. In the first training stage, we focus on learning the spatial features (the features of object content) and breaking down the temporal relationships in the video frames by shuffling them. We further propose Recurrent-Causal Attention (RC-Attn) to learn the consistent content features of the object from unordered video frames. In the second training stage, we restore the temporal relationship in video frames to learn the temporal feature (the features of the background and object's motion). We also adopt the Noise Constraint Loss to smooth out inter-frame differences. Finally, in the inference stage, we inject the content features of the source object into the editing branch through a two-branch structure (editing branch and reconstruction branch). With Edit-Your-Motion, users can edit the motion of objects in the source video to generate more exciting and diverse videos. Comprehensive qualitative experiments, quantitative experiments and user preference studies demonstrate that Edit-Your-Motion performs better than other methods.
Unveiling and Mitigating Generalized Biases of DNNs through the Intrinsic Dimensions of Perceptual Manifolds
Apr 22, 2024



Building fair deep neural networks (DNNs) is a crucial step towards achieving trustworthy artificial intelligence. Delving into deeper factors that affect the fairness of DNNs is paramount and serves as the foundation for mitigating model biases. However, current methods are limited in accurately predicting DNN biases, relying solely on the number of training samples and lacking more precise measurement tools. Here, we establish a geometric perspective for analyzing the fairness of DNNs, comprehensively exploring how DNNs internally shape the intrinsic geometric characteristics of datasets-the intrinsic dimensions (IDs) of perceptual manifolds, and the impact of IDs on the fairness of DNNs. Based on multiple findings, we propose Intrinsic Dimension Regularization (IDR), which enhances the fairness and performance of models by promoting the learning of concise and ID-balanced class perceptual manifolds. In various image recognition benchmark tests, IDR significantly mitigates model bias while improving its performance.
M3SOT: Multi-frame, Multi-field, Multi-space 3D Single Object Tracking
Dec 11, 2023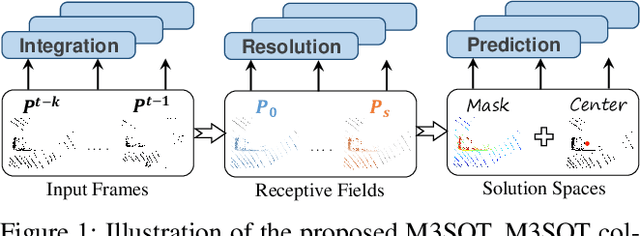



3D Single Object Tracking (SOT) stands a forefront task of computer vision, proving essential for applications like autonomous driving. Sparse and occluded data in scene point clouds introduce variations in the appearance of tracked objects, adding complexity to the task. In this research, we unveil M3SOT, a novel 3D SOT framework, which synergizes multiple input frames (template sets), multiple receptive fields (continuous contexts), and multiple solution spaces (distinct tasks) in ONE model. Remarkably, M3SOT pioneers in modeling temporality, contexts, and tasks directly from point clouds, revisiting a perspective on the key factors influencing SOT. To this end, we design a transformer-based network centered on point cloud targets in the search area, aggregating diverse contextual representations and propagating target cues by employing historical frames. As M3SOT spans varied processing perspectives, we've streamlined the network-trimming its depth and optimizing its structure-to ensure a lightweight and efficient deployment for SOT applications. We posit that, backed by practical construction, M3SOT sidesteps the need for complex frameworks and auxiliary components to deliver sterling results. Extensive experiments on benchmarks such as KITTI, nuScenes, and Waymo Open Dataset demonstrate that M3SOT achieves state-of-the-art performance at 38 FPS. Our code and models are available at https://github.com/ywu0912/TeamCode.git.
* 12 pages, 10 figures, 10 tables, AAAI 2024