 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Gaussian Similarity Modeling for Differential Graph Structure Learning
Dec 15, 2023



Graph Structure Learning (GSL) has demonstrated considerable potential in the analysis of graph-unknown non-Euclidean data across a wide range of domains. However, constructing an end-to-end graph structure learning model poses a challenge due to the impediment of gradient flow caused by the nearest neighbor sampling strategy. In this paper, we construct a differential graph structure learning model by replacing the non-differentiable nearest neighbor sampling with a differentiable sampling using the reparameterization trick. Under this framework, we argue that the act of sampling \mbox{nearest} neighbors may not invariably be essential, particularly in instances where node features exhibit a significant degree of similarity. To alleviate this issue, the bell-shaped Gaussian Similarity (GauSim) modeling is proposed to sample non-nearest neighbors. To adaptively model the similarity, we further propose Neural Gaussian Similarity (NeuralGauSim) with learnable parameters featuring flexible sampling behaviors. In addition, we develop a scalable method by transferring the large-scale graph to the transition graph to significantly reduce the complexity. Experimental results demonstrate the effectiveness of the proposed methods.
Evolutionary Multitasking with Solution Space Cutting for Point Cloud Registration
Dec 12, 2022



Point cloud registration (PCR) is a popular research topic in computer vision. Recently, the registration method in an evolutionary way has received continuous attention because of its robustness to the initial pose and flexibility in objective function design. However, most evolving registration methods cannot tackle the local optimum well and they have rarely investigated the success ratio, which implies the probability of not falling into local optima and is closely related to the practicality of the algorithm. Evolutionary multi-task optimization (EMTO) is a widely used paradigm, which can boost exploration capability through knowledge transfer among related tasks. Inspired by this concept, this study proposes a novel evolving registration algorithm via EMTO, where the multi-task configuration is based on the idea of solution space cutting. Concretely, one task searching in cut space assists another task with complex function landscape in escaping from local optima and enhancing successful registration ratio. To reduce unnecessary computational cost, a sparse-to-dense strategy is proposed. In addition, a novel fitness function robust to various overlap rates as well as a problem-specific metric of computational cost is introduced. Compared with 7 evolving registration approaches and 4 traditional registration approaches on the object-scale and scene-scale registration datasets, experimental results demonstrate that the proposed method has superior performances in terms of precision and tackling local optima.
Multi-view Point Cloud Registration based on Evolutionary Multitasking with Bi-Channel Knowledge Sharing Mechanism
May 06, 2022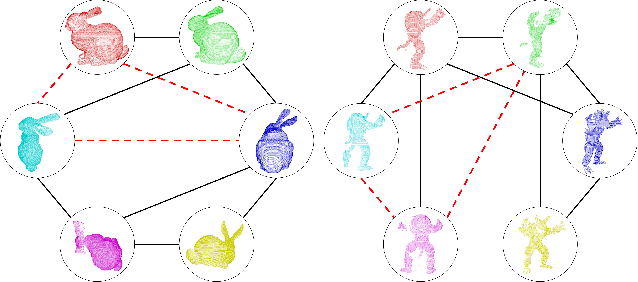
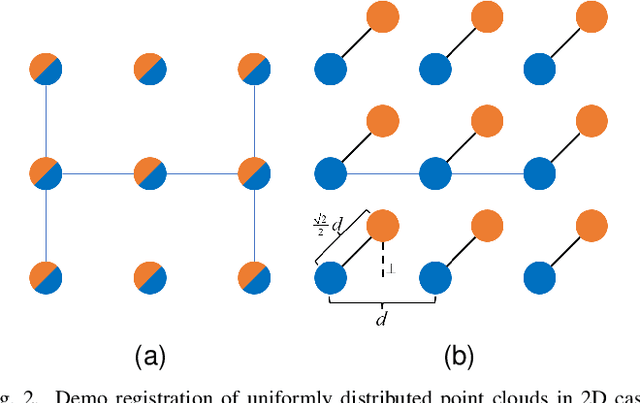
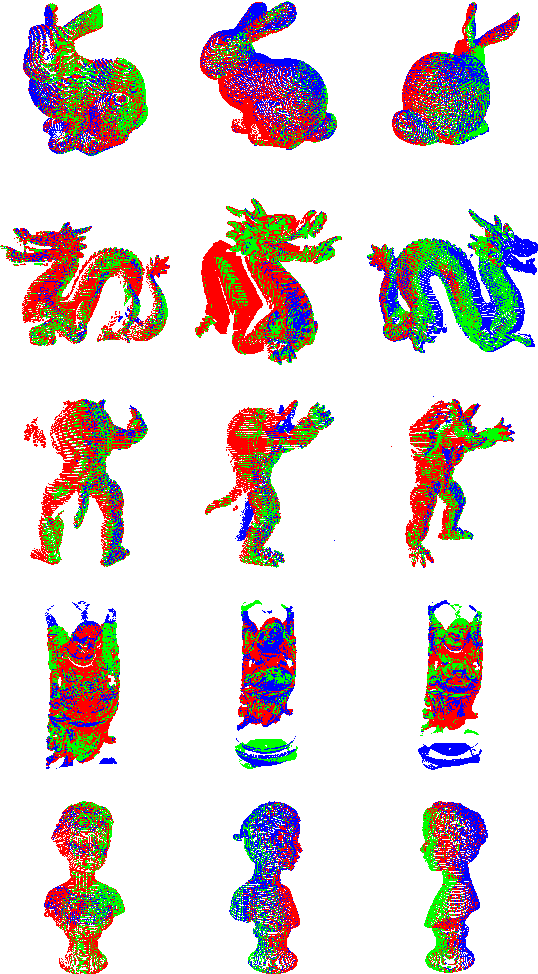

Registration of multi-view point clouds is fundamental in 3D reconstruction. Since there are close connections between point clouds captured from different viewpoints, registration performance can be enhanced if these connections be harnessed properly. Therefore, this paper models the registration problem as multi-task optimization, and proposes a novel bi-channel knowledge sharing mechanism for effective and efficient problem solving. The modeling of multi-view point cloud registration as multi-task optimization are twofold. By simultaneously considering the local accuracy of two point clouds as well as the global consistency posed by all the point clouds involved, a fitness function with an adaptive threshold is derived. Also a framework of the co-evolutionary search process is defined for the concurrent optimization of multiple fitness functions belonging to related tasks. To enhance solution quality and convergence speed, the proposed bi-channel knowledge sharing mechanism plays its role. The intra-task knowledge sharing introduces aiding tasks that are much simpler to solve, and useful information is shared within tasks, accelerating the search process. The inter-task knowledge sharing explores commonalities buried among tasks, aiming to prevent tasks from getting stuck to local optima. Comprehensive experiments conducted on model object as well as scene point clouds show the efficacy of the proposed method.
AsymptoticNG: A regularized natural gradient optimization algorithm with look-ahead strategy
Jan 16, 2021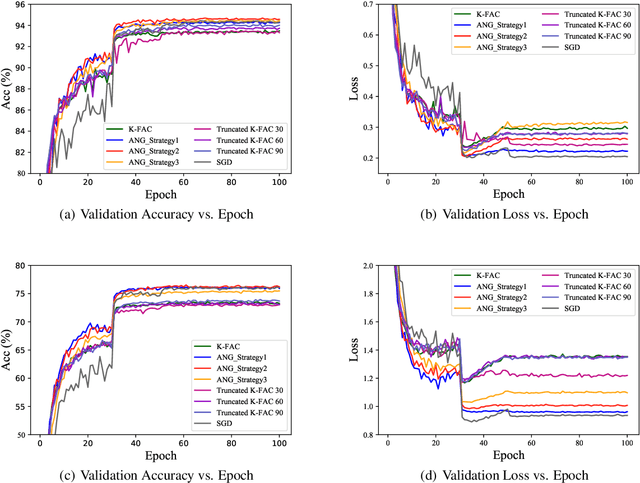

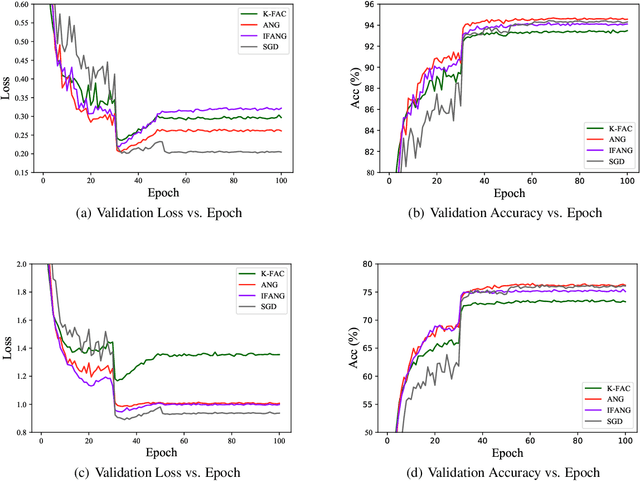
Optimizers that further adjust the scale of gradient, such as Adam, Natural Gradient (NG), etc., despite widely concerned and used by the community, are often found poor generalization performance, compared with Stochastic Gradient Descent (SGD). They tend to converge excellently at the beginning of training but are weak at the end. An immediate idea is to complement the strengths of these algorithms with SGD. However, a truncated replacement of optimizer often leads to a crash of the update pattern, and new algorithms often require many iterations to stabilize their search direction. Driven by this idea and to address this problem, we design and present a regularized natural gradient optimization algorithm with look-ahead strategy, named asymptotic natural gradient (ANG). According to the total iteration step, ANG dynamic assembles NG and Euclidean gradient, and updates parameters along the new direction using the intensity of NG. Validation experiments on CIFAR10 and CIFAR100 data sets show that ANG can update smoothly and stably at the second-order speed, and achieve better generalization performance.
Locality Preserving Dense Graph Convolutional Networks with Graph Context-Aware Node Representations
Oct 12, 2020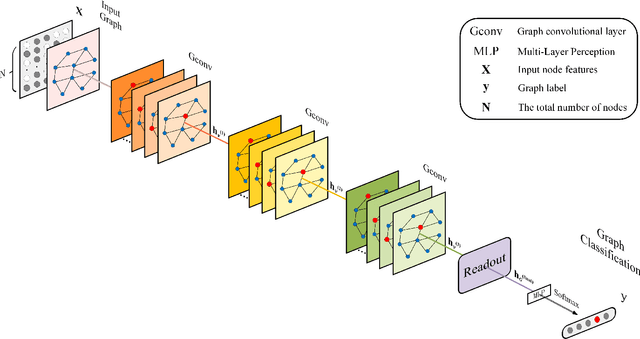
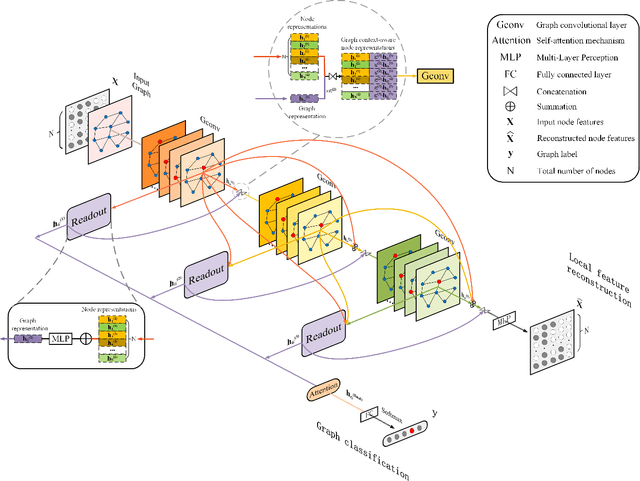
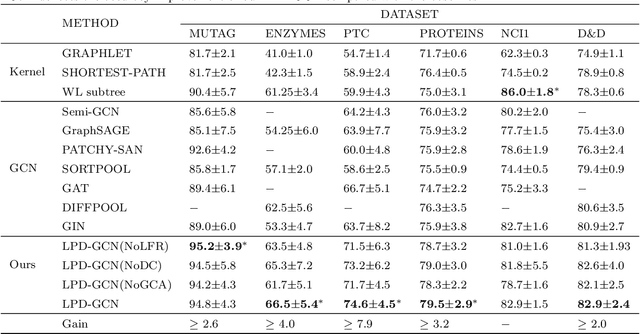
Graph convolutional networks (GCNs) have been widely used for representation learning on graph data, which can capture structural patterns on a graph via specifically designed convolution and readout operations. In many graph classification applications, GCN-based approaches have outperformed traditional methods. However, most of the existing GCNs are inefficient to preserve local information of graphs -- a limitation that is especially problematic for graph classification. In this work, we propose a locality-preserving dense GCN with graph context-aware node representations. Specifically, our proposed model incorporates a local node feature reconstruction module to preserve initial node features into node representations, which is realized via a simple but effective encoder-decoder mechanism. To capture local structural patterns in neighbourhoods representing different ranges of locality, dense connectivity is introduced to connect each convolutional layer and its corresponding readout with all previous convolutional layers. To enhance node representativeness, the output of each convolutional layer is concatenated with the output of the previous layer's readout to form a global context-aware node representation. In addition, a self-attention module is introduced to aggregate layer-wise representations to form the final representation. Experiments on benchmark datasets demonstrate the superiority of the proposed model over state-of-the-art methods in terms of classification accuracy.