 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Gaussian Similarity Modeling for Differential Graph Structure Learning
Dec 15, 2023



Graph Structure Learning (GSL) has demonstrated considerable potential in the analysis of graph-unknown non-Euclidean data across a wide range of domains. However, constructing an end-to-end graph structure learning model poses a challenge due to the impediment of gradient flow caused by the nearest neighbor sampling strategy. In this paper, we construct a differential graph structure learning model by replacing the non-differentiable nearest neighbor sampling with a differentiable sampling using the reparameterization trick. Under this framework, we argue that the act of sampling \mbox{nearest} neighbors may not invariably be essential, particularly in instances where node features exhibit a significant degree of similarity. To alleviate this issue, the bell-shaped Gaussian Similarity (GauSim) modeling is proposed to sample non-nearest neighbors. To adaptively model the similarity, we further propose Neural Gaussian Similarity (NeuralGauSim) with learnable parameters featuring flexible sampling behaviors. In addition, we develop a scalable method by transferring the large-scale graph to the transition graph to significantly reduce the complexity. Experimental results demonstrate the effectiveness of the proposed methods.
PCRDiffusion: Diffusion Probabilistic Models for Point Cloud Registration
Dec 11, 2023We propose a new framework that formulates point cloud registration as a denoising diffusion process from noisy transformation to object transformation. During training stage, object transformation diffuses from ground-truth transformation to random distribution, and the model learns to reverse this noising process. In sampling stage, the model refines randomly generated transformation to the output result in a progressive way. We derive the variational bound in closed form for training and provide implementations of the model. Our work provides the following crucial findings: (i) In contrast to most existing methods, our framework, Diffusion Probabilistic Models for Point Cloud Registration (PCRDiffusion) does not require repeatedly update source point cloud to refine the predicted transformation. (ii) Point cloud registration, one of the representative discriminative tasks, can be solved by a generative way and the unified probabilistic formulation. Finally, we discuss and provide an outlook on the application of diffusion model in different scenarios for point cloud registration. Experimental results demonstrate that our model achieves competitive performance in point cloud registration. In correspondence-free and correspondence-based scenarios, PCRDifussion can both achieve exceeding 50\% performance improvements.
Towards Consistency and Complementarity: A Multiview Graph Information Bottleneck Approach
Oct 11, 2022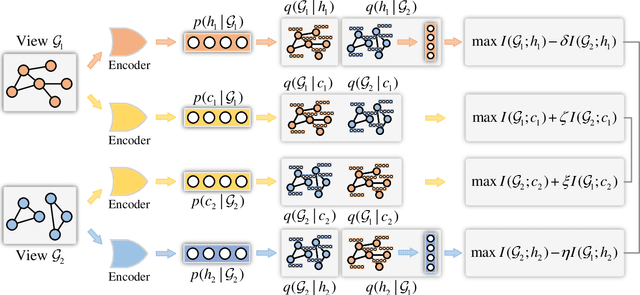
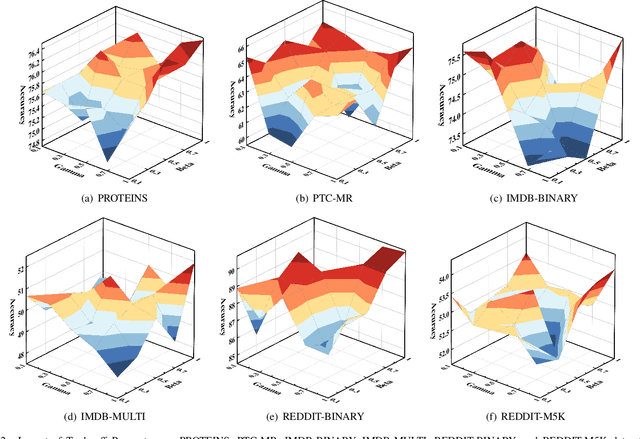
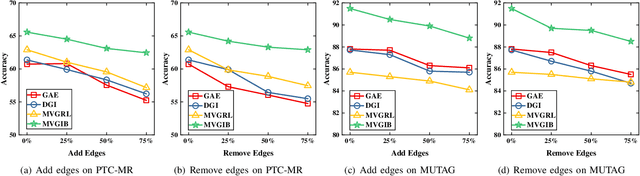
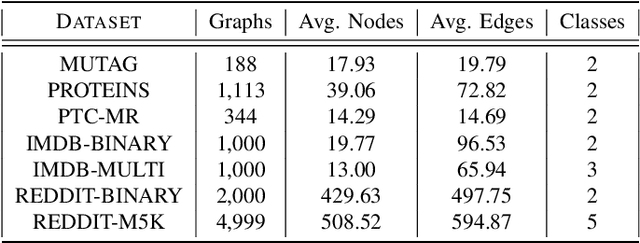
The empirical studies of Graph Neural Networks (GNNs) broadly take the original node feature and adjacency relationship as singleview input, ignoring the rich information of multiple graph views. To circumvent this issue, the multiview graph analysis framework has been developed to fuse graph information across views. How to model and integrate shared (i.e. consistency) and view-specific (i.e. complementarity) information is a key issue in multiview graph analysis. In this paper, we propose a novel Multiview Variational Graph Information Bottleneck (MVGIB) principle to maximize the agreement for common representations and the disagreement for view-specific representations. Under this principle, we formulate the common and view-specific information bottleneck objectives across multiviews by using constraints from mutual information. However, these objectives are hard to directly optimize since the mutual information is computationally intractable. To tackle this challenge, we derive variational lower and upper bounds of mutual information terms, and then instead optimize variational bounds to find the approximate solutions for the information objectives. Extensive experiments on graph benchmark datasets demonstrate the superior effectiveness of the proposed method.
Maximizing Mutual Information Across Feature and Topology Views for Learning Graph Representations
May 14, 2021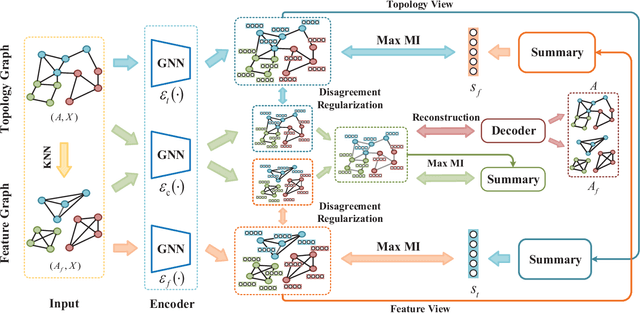
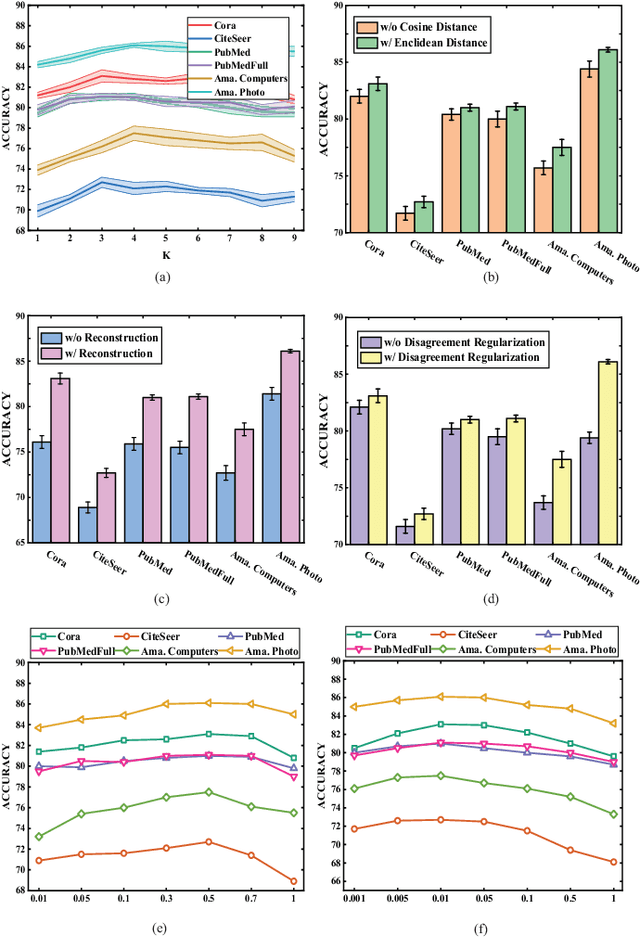

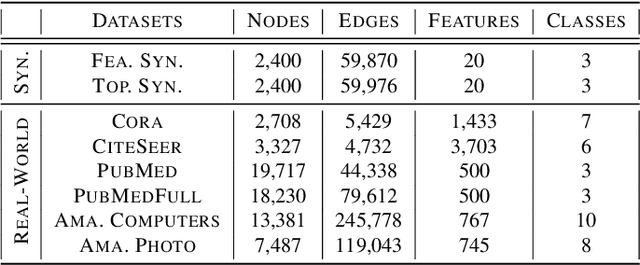
Recently, maximizing mutual information has emerged as a powerful method for unsupervised graph representation learning. The existing methods are typically effective to capture information from the topology view but ignore the feature view. To circumvent this issue, we propose a novel approach by exploiting mutual information maximization across feature and topology views. Specifically, we first utilize a multi-view representation learning module to better capture both local and global information content across feature and topology views on graphs. To model the information shared by the feature and topology spaces, we then develop a common representation learning module using mutual information maximization and reconstruction loss minimization. To explicitly encourage diversity between graph representations from the same view, we also introduce a disagreement regularization to enlarge the distance between representations from the same view. Experiments on synthetic and real-world datasets demonstrate the effectiveness of integrating feature and topology views. In particular, compared with the previous supervised methods, our proposed method can achieve comparable or even better performance under the unsupervised representation and linear evaluation protocol.