 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Hash Codes via Hamming Distance Targets
Oct 01, 2018
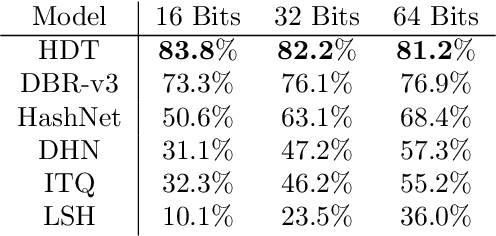
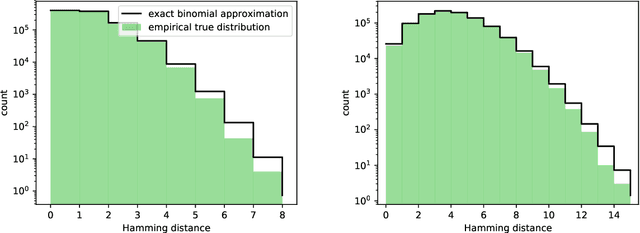
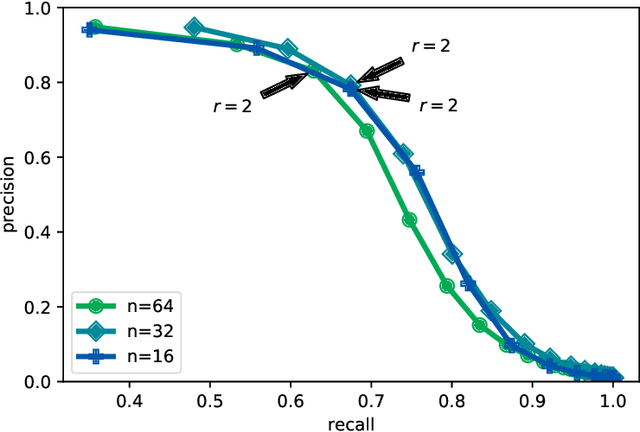
We present a powerful new loss function and training scheme for learning binary hash codes with any differentiable model and similarity function. Our loss function improves over prior methods by using log likelihood loss on top of an accurate approximation for the probability that two inputs fall within a Hamming distance target. Our novel training scheme obtains a good estimate of the true gradient by better sampling inputs and evaluating loss terms between all pairs of inputs in each minibatch. To fully leverage the resulting hashes, we use multi-indexing. We demonstrate that these techniques provide large improvements to a similarity search tasks. We report the best results to date on competitive information retrieval tasks for ImageNet and SIFT 1M, improving MAP from 73% to 84% and reducing query cost by a factor of 2-8, respectively.
Convolutional Hashing for Automated Scene Matching
Feb 09, 2018

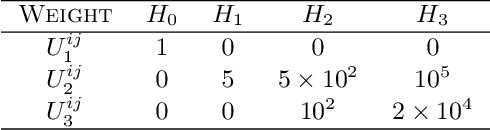
We present a powerful new loss function and training scheme for learning binary hash functions. In particular, we demonstrate our method by creating for the first time a neural network that outperforms state-of-the-art Haar wavelets and color layout descriptors at the task of automated scene matching. By accurately relating distance on the manifold of network outputs to distance in Hamming space, we achieve a 100-fold reduction in nontrivial false positive rate and significantly higher true positive rate. We expect our insights to provide large wins for hashing models applied to other information retrieval hashing tasks as well.