 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIKED++: A Multimodal Dataset of 1.4 Million Bicycle Image and Parametric CAD Designs
Feb 09, 2024This paper introduces a public dataset of 1.4 million procedurally-generated bicycle designs represented parametrically, as JSON files, and as rasterized images. The dataset is created through the use of a rendering engine which harnesses the BikeCAD software to generate vector graphics from parametric designs. This rendering engine is discussed in the paper and also released publicly alongside the dataset. Though this dataset has numerous applications, a principal motivation is the need to train cross-modal predictive models between parametric and image-based design representations. For example, we demonstrate that a predictive model can be trained to accurately estimate Contrastive Language-Image Pretraining (CLIP) embeddings from a parametric representation directly. This allows similarity relations to be established between parametric bicycle designs and text strings or reference images. Trained predictive models are also made public. The dataset joins the BIKED dataset family which includes thousands of mixed-representation human-designed bicycle models and several datasets quantifying design performance. The code and dataset can be found at: https://github.com/Lyleregenwetter/BIKED_multimodal/tree/main
NITO: Neural Implicit Fields for Resolution-free Topology Optimization
Feb 07, 2024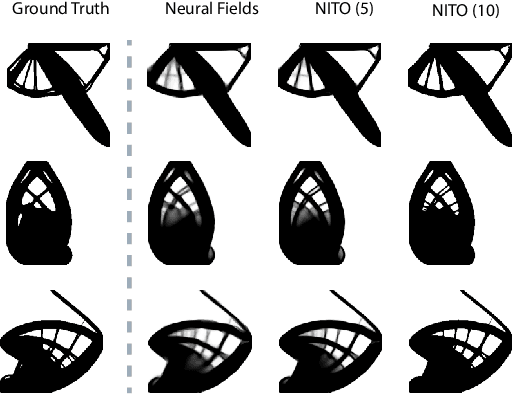

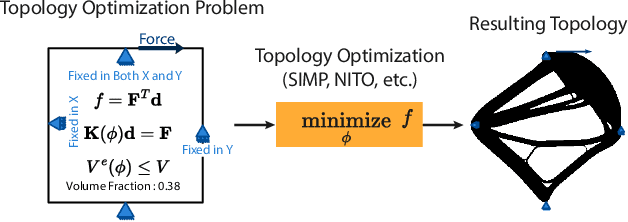
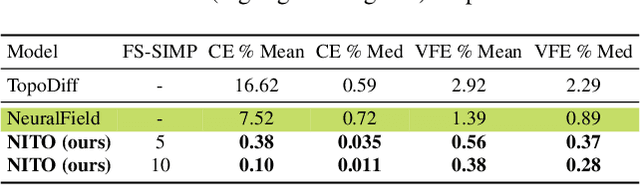
Topology optimization is a critical task in engineering design, where the goal is to optimally distribute material in a given space for maximum performance. We introduce Neural Implicit Topology Optimization (NITO), a novel approach to accelerate topology optimization problems using deep learning. NITO stands out as one of the first frameworks to offer a resolution-free and domain-agnostic solution in deep learning-based topology optimization. NITO synthesizes structures with up to seven times better structural efficiency compared to SOTA diffusion models and does so in a tenth of the time. In the NITO framework, we introduce a novel method, the Boundary Point Order-Invariant MLP (BPOM), to represent boundary conditions in a sparse and domain-agnostic manner, moving away from expensive simulation-based approaches. Crucially, NITO circumvents the domain and resolution limitations that restrict Convolutional Neural Network (CNN) models to a structured domain of fixed size -- limitations that hinder the widespread adoption of CNNs in engineering applications. This generalizability allows a single NITO model to train and generate solutions in countless domains, eliminating the need for numerous domain-specific CNNs and their extensive datasets. Despite its generalizability, NITO outperforms SOTA models even in specialized tasks, is an order of magnitude smaller, and is practically trainable at high resolutions that would be restrictive for CNNs. This combination of versatility, efficiency, and performance underlines NITO's potential to transform the landscape of engineering design optimization problems through implicit fields.
Learning from Invalid Data: On Constraint Satisfaction in Generative Models
Jun 27, 2023Generative models have demonstrated impressive results in vision, language, and speech. However, even with massive datasets, they struggle with precision, generating physically invalid or factually incorrect data. This is particularly problematic when the generated data must satisfy constraints, for example, to meet product specifications in engineering design or to adhere to the laws of physics in a natural scene. To improve precision while preserving diversity and fidelity, we propose a novel training mechanism that leverages datasets of constraint-violating data points, which we consider invalid. Our approach minimizes the divergence between the generative distribution and the valid prior while maximizing the divergence with the invalid distribution. We demonstrate how generative models like GANs and DDPMs that we augment to train with invalid data vastly outperform their standard counterparts which solely train on valid data points. For example, our training procedure generates up to 98 % fewer invalid samples on 2D densities, improves connectivity and stability four-fold on a stacking block problem, and improves constraint satisfaction by 15 % on a structural topology optimization benchmark in engineering design. We also analyze how the quality of the invalid data affects the learning procedure and the generalization properties of models. Finally, we demonstrate significant improvements in sample efficiency, showing that a tenfold increase in valid samples leads to a negligible difference in constraint satisfaction, while less than 10 % invalid samples lead to a tenfold improvement. Our proposed mechanism offers a promising solution for improving precision in generative models while preserving diversity and fidelity, particularly in domains where constraint satisfaction is critical and data is limited, such as engineering design, robotics, and medicine.
Counterfactuals for Design: A Model-Agnostic Method For Design Recommendations
May 18, 2023



We introduce Multi-Objective Counterfactuals for Design (MCD), a novel method for counterfactual optimization in design problems. Counterfactuals are hypothetical situations that can lead to a different decision or choice. In this paper, the authors frame the counterfactual search problem as a design recommendation tool that can help identify modifications to a design, leading to better functional performance. MCD improves upon existing counterfactual search methods by supporting multi-objective queries, which are crucial in design problems, and by decoupling the counterfactual search and sampling processes, thus enhancing efficiency and facilitating objective tradeoff visualization. The paper demonstrates MCD's core functionality using a two-dimensional test case, followed by three case studies of bicycle design that showcase MCD's effectiveness in real-world design problems. In the first case study, MCD excels at recommending modifications to query designs that can significantly enhance functional performance, such as weight savings and improvements to the structural safety factor. The second case study demonstrates that MCD can work with a pre-trained language model to suggest design changes based on a subjective text prompt effectively. Lastly, the authors task MCD with increasing a query design's similarity to a target image and text prompt while simultaneously reducing weight and improving structural performance, demonstrating MCD's performance on a complex multimodal query. Overall, MCD has the potential to provide valuable recommendations for practitioners and design automation researchers looking for answers to their ``What if'' questions by exploring hypothetical design modifications and their impact on multiple design objectives. The code, test problems, and datasets used in the paper are available to the public at decode.mit.edu/projects/counterfactuals/.
Beyond Statistical Similarity: Rethinking Metrics for Deep Generative Models in Engineering Design
Feb 11, 2023



Deep generative models, such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), Diffusion Models, and Transformers, have shown great promise in a variety of applications, including image and speech synthesis, natural language processing, and drug discovery. However, when applied to engineering design problems, evaluating the performance of these models can be challenging, as traditional statistical metrics based on likelihood may not fully capture the requirements of engineering applications. This paper doubles as a review and a practical guide to evaluation metrics for deep generative models (DGMs) in engineering design. We first summarize well-accepted `classic' evaluation metrics for deep generative models grounded in machine learning theory and typical computer science applications. Using case studies, we then highlight why these metrics seldom translate well to design problems but see frequent use due to the lack of established alternatives. Next, we curate a set of design-specific metrics which have been proposed across different research communities and can be used for evaluating deep generative models. These metrics focus on unique requirements in design and engineering, such as constraint satisfaction, functional performance, novelty, and conditioning. We structure our review and discussion as a set of practical selection criteria and usage guidelines. Throughout our discussion, we apply the metrics to models trained on simple 2-dimensional example problems. Finally, to illustrate the selection process and classic usage of the presented metrics, we evaluate three deep generative models on a multifaceted bicycle frame design problem considering performance target achievement, design novelty, and geometric constraints. We publicly release the code for the datasets, models, and metrics used throughout the paper at decode.mit.edu/projects/metrics/.
Towards Goal, Feasibility, and Diversity-Oriented Deep Generative Models in Design
Jun 14, 2022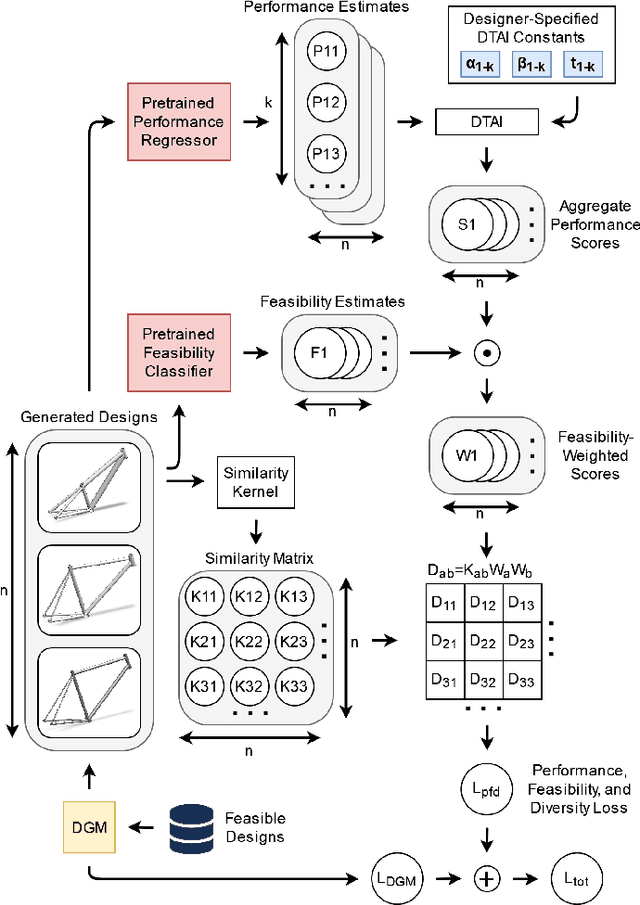



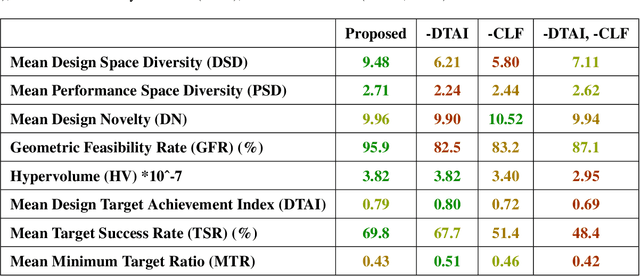
Deep Generative Machine Learning Models (DGMs) have been growing in popularity across the design community thanks to their ability to learn and mimic complex data distributions. DGMs are conventionally trained to minimize statistical divergence between the distribution over generated data and distribution over the dataset on which they are trained. While sufficient for the task of generating "realistic" fake data, this objective is typically insufficient for design synthesis tasks. Instead, design problems typically call for adherence to design requirements, such as performance targets and constraints. Advancing DGMs in engineering design requires new training objectives which promote engineering design objectives. In this paper, we present the first Deep Generative Model that simultaneously optimizes for performance, feasibility, diversity, and target achievement. We benchmark performance of the proposed method against several Deep Generative Models over eight evaluation metrics that focus on feasibility, diversity, and satisfaction of design performance targets. Methods are tested on a challenging multi-objective bicycle frame design problem with skewed, multimodal data of different datatypes. The proposed framework was found to outperform all Deep Generative Models in six of eight metrics.
Design Target Achievement Index: A Differentiable Metric to Enhance Deep Generative Models in Multi-Objective Inverse Design
May 06, 2022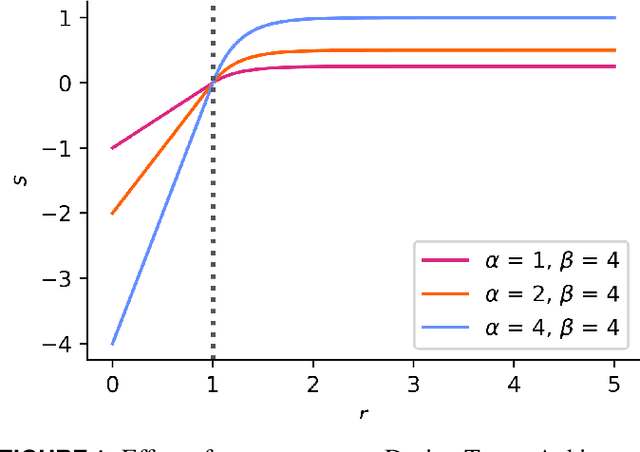


Deep Generative Machine Learning Models have been growing in popularity across the design community thanks to their ability to learn and mimic complex data distributions. While early works are promising, further advancement will depend on addressing several critical considerations such as design quality, feasibility, novelty, and targeted inverse design. We propose the Design Target Achievement Index (DTAI), a differentiable, tunable metric that scores a design's ability to achieve designer-specified minimum performance targets. We demonstrate that DTAI can drastically improve the performance of generated designs when directly used as a training loss in Deep Generative Models. We apply the DTAI loss to a Performance-Augmented Diverse GAN (PaDGAN) and demonstrate superior generative performance compared to a set of baseline Deep Generative Models including a Multi-Objective PaDGAN and specialized tabular generation algorithms like the Conditional Tabular GAN (CTGAN). We further enhance PaDGAN with an auxiliary feasibility classifier to encourage feasible designs. To evaluate methods, we propose a comprehensive set of evaluation metrics for generative methods that focus on feasibility, diversity, and satisfaction of design performance targets. Methods are tested on a challenging benchmarking problem: the FRAMED bicycle frame design dataset featuring mixed-datatype parametric data, heavily skewed and multimodal distributions, and ten competing performance objectives.
FRAMED: Data-Driven Structural Performance Analysis of Community-Designed Bicycle Frames
Jan 25, 2022
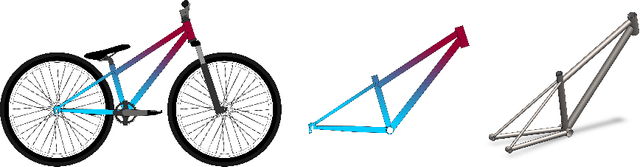


This paper presents a data-driven analysis of the structural performance of 4500 community-designed bicycle frames. We present FRAMED -- a parametric dataset of bicycle frames based on bicycles designed by bicycle practitioners from across the world. To support our data-driven approach, we also provide a dataset of structural performance values such as weight, displacements under load, and safety factors for all the bicycle frame designs. By exploring a diverse design space of frame design parameters and a set of ten competing design objectives, we present an automated way to analyze the structural performance of bicycle frames. Our structural simulations are validated against physical experimentation on bicycle frames. Through our analysis, we highlight overall trends in bicycle frame designs created by community members, study several bicycle frames under different loading conditions, identify non-dominated design candidates that perform well on multiple objectives, and explore correlations between structural objectives. Our analysis shows that over 75\% of bicycle frames created by community members are infeasible, motivating the need for AI agents to support humans in designing bicycles. This work aims to simultaneously serve researchers focusing on bicycle design as well as researchers focusing on the development of data-driven design algorithms, such as surrogate models and Deep Generative Methods. The dataset and code are provided at http://decode.mit.edu/projects/framed/.
Deep Generative Models in Engineering Design: A Review
Oct 21, 2021

Automated design synthesis has the potential to revolutionize the modern human design process and improve access to highly optimized and customized products across countless industries. Successfully adapting generative Machine Learning to design engineering may be the key to such automated design synthesis and is a research subject of great importance. We present a review and analysis of Deep Generative Learning models in engineering design. Deep Generative Models (DGMs) typically leverage deep networks to learn from an input dataset and learn to synthesize new designs. Recently, DGMs such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), feedforward Neural Networks (NNs) and certain Deep Reinforcement Learning (DRL) frameworks have shown promising results in design applications like structural optimization, materials design, and shape synthesis. The prevalence of DGMs in Engineering Design has skyrocketed since 2016. Anticipating continued growth, we conduct a review of recent advances with the hope of benefitting researchers interested in DGMs for design. We structure our review as an exposition of the algorithms, datasets, representation methods, and applications commonly used in the current literature. In particular, we discuss key works that have introduced new techniques and methods in DGMs, successfully applied DGMs to a design-related domain, or directly supported development of DGMs through datasets or auxiliary methods. We further identify key challenges and limitations currently seen in DGMs across design fields, such as design creativity, handling complex constraints and objectives, and modeling both form and functional performance simultaneously. In our discussion we identify possible solution pathways as key areas on which to target future work.
BIKED: A Dataset and Machine Learning Benchmarks for Data-Driven Bicycle Design
Mar 10, 2021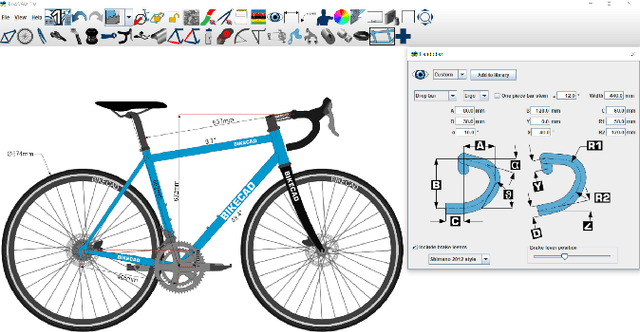
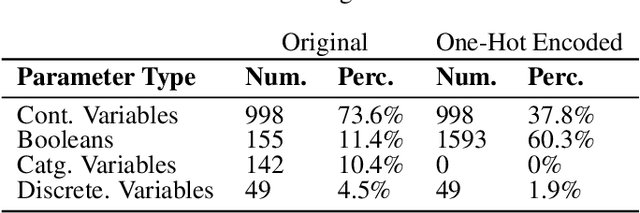

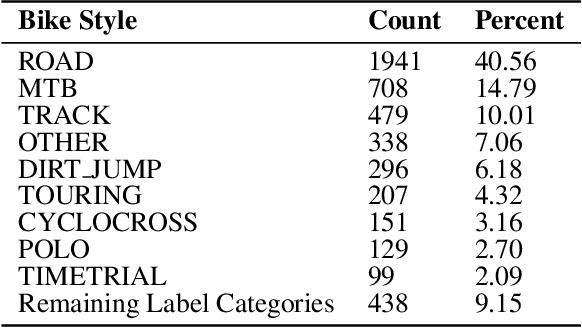
In this paper, we present "BIKED," a dataset comprised of 4500 individually designed bicycle models sourced from hundreds of designers. We expect BIKED to enable a variety of data-driven design applications for bicycles and generally support the development of data-driven design methods. The dataset is comprised of a variety of design information including assembly images, component images, numerical design parameters, and class labels. In this paper, we first discuss the processing of the dataset and present the various features provided. We then illustrate the scale, variety, and structure of the data using several unsupervised clustering studies. Next, we explore a variety of data-driven applications. We provide baseline classification performance for 10 algorithms trained on differing amounts of training data. We then contrast classification performance of three deep neural networks using parametric data, image data, and a combination of the two. Using one of the trained classification models, we conduct a Shapley Additive Explanations Analysis to better understand the extent to which certain design parameters impact classification predictions. Next, we test bike reconstruction and design synthesis using two Variational Autoencoders (VAEs) trained on images and parametric data. We furthermore contrast the performance of interpolation and extrapolation tasks in the original parameter space and the latent space of a VAE. Finally, we discuss some exciting possibilities for other applications beyond the few actively explored in this paper and summarize overall strengths and weaknesses of the dataset.