 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComboGAN: Unrestrained Scalability for Image Domain Translation
Paper and Code
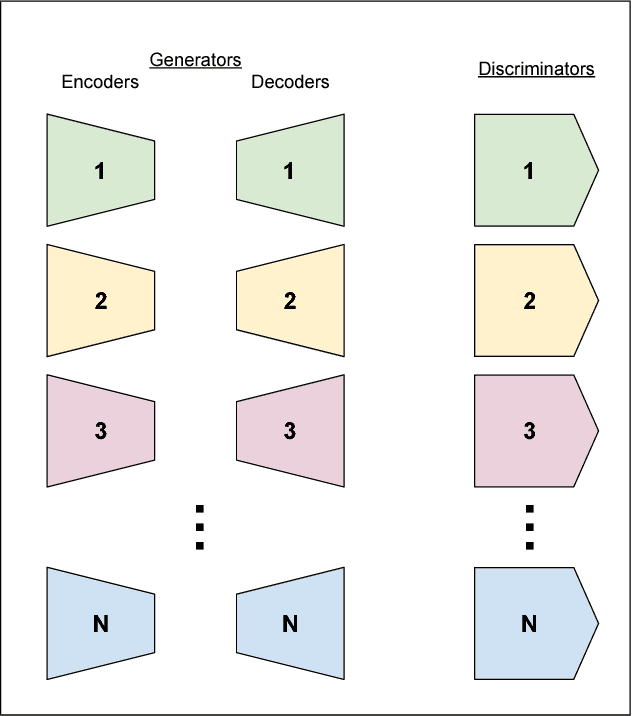
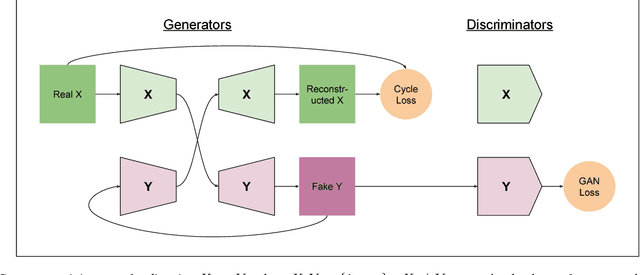
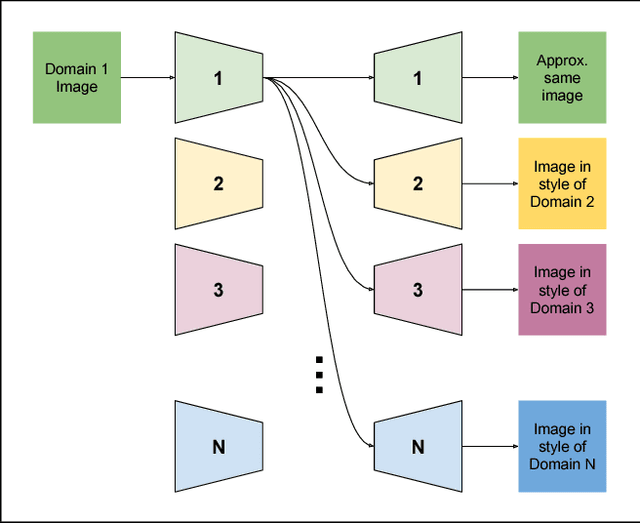

This year alone has seen unprecedented leaps in the area of learning-based image translation, namely CycleGAN, by Zhu et al. But experiments so far have been tailored to merely two domains at a time, and scaling them to more would require an quadratic number of models to be trained. And with two-domain models taking days to train on current hardware, the number of domains quickly becomes limited by the time and resources required to process them. In this paper, we propose a multi-component image translation model and training scheme which scales linearly - both in resource consumption and time required - with the number of domains. We demonstrate its capabilities on a dataset of paintings by 14 different artists and on images of the four different seasons in the Alps. Note that 14 data groups would need (14 choose 2) = 91 different CycleGAN models: a total of 182 generator/discriminator pairs; whereas our model requires only 14 generator/discriminator pairs.