 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Detect Objects with a 1 Megapixel Event Camera
Sep 28, 2020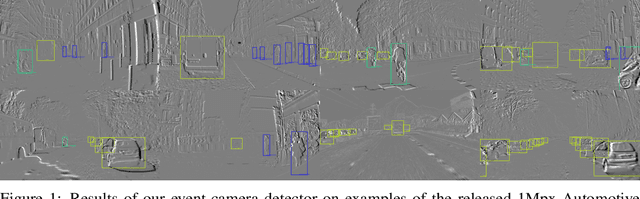

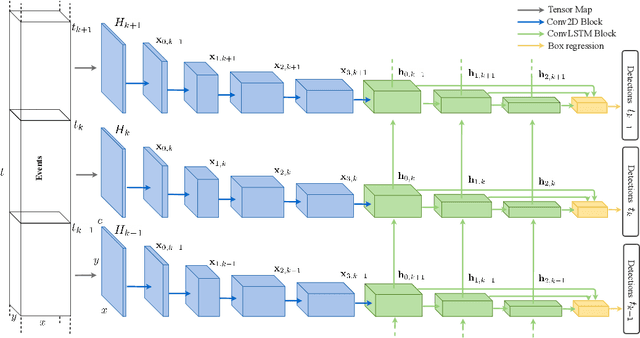
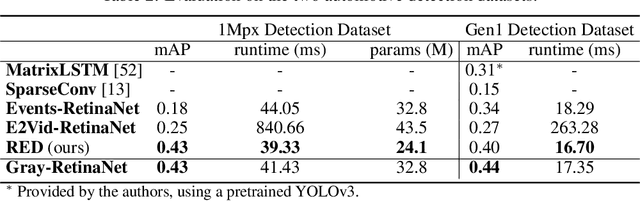
Event cameras encode visual information with high temporal precision, low data-rate, and high-dynamic range. Thanks to these characteristics, event cameras are particularly suited for scenarios with high motion, challenging lighting conditions and requiring low latency. However, due to the novelty of the field, the performance of event-based systems on many vision tasks is still lower compared to conventional frame-based solutions. The main reasons for this performance gap are: the lower spatial resolution of event sensors, compared to frame cameras; the lack of large-scale training datasets; the absence of well established deep learning architectures for event-based processing. In this paper, we address all these problems in the context of an event-based object detection task. First, we publicly release the first high-resolution large-scale dataset for object detection. The dataset contains more than 14 hours recordings of a 1 megapixel event camera, in automotive scenarios, together with 25M bounding boxes of cars, pedestrians, and two-wheelers, labeled at high frequency. Second, we introduce a novel recurrent architecture for event-based detection and a temporal consistency loss for better-behaved training. The ability to compactly represent the sequence of events into the internal memory of the model is essential to achieve high accuracy. Our model outperforms by a large margin feed-forward event-based architectures. Moreover, our method does not require any reconstruction of intensity images from events, showing that training directly from raw events is possible, more efficient, and more accurate than passing through an intermediate intensity image. Experiments on the dataset introduced in this work, for which events and gray level images are available, show performance on par with that of highly tuned and studied frame-based detectors.
A Large Scale Event-based Detection Dataset for Automotive
Jan 31, 2020
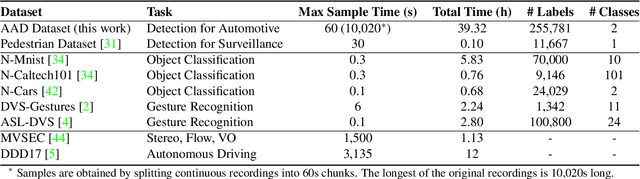

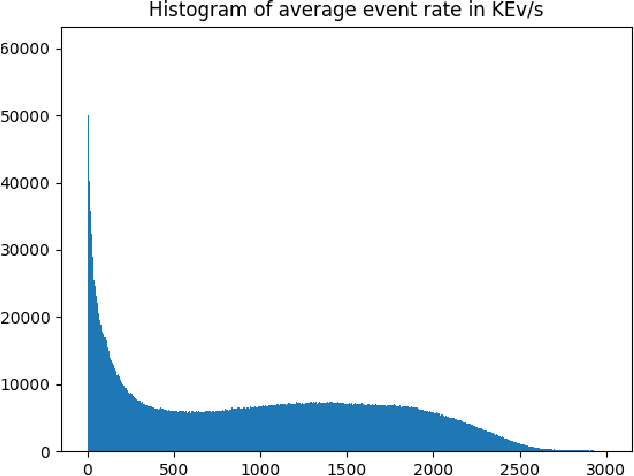
We introduce the first very large detection dataset for event cameras. The dataset is composed of more than 39 hours of automotive recordings acquired with a 304x240 ATIS sensor. It contains open roads and very diverse driving scenarios, ranging from urban, highway, suburbs and countryside scenes, as well as different weather and illumination conditions. Manual bounding box annotations of cars and pedestrians contained in the recordings are also provided at a frequency between 1 and 4Hz, yielding more than 255,000 labels in total. We believe that the availability of a labeled dataset of this size will contribute to major advances in event-based vision tasks such as object detection and classification. We also expect benefits in other tasks such as optical flow, structure from motion and tracking, where for example, the large amount of data can be leveraged by self-supervised learning methods.
An Artificial Agent for Robust Image Registration
Nov 30, 2016
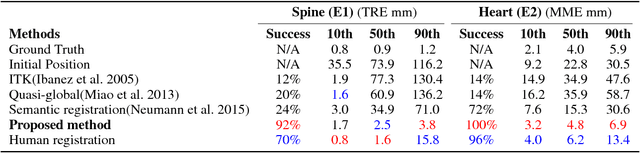
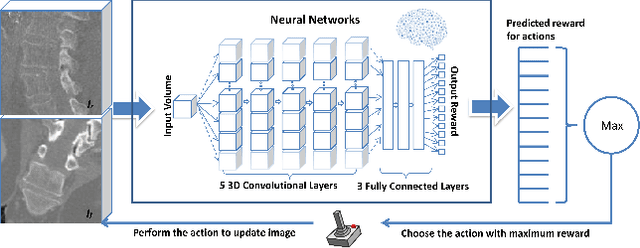

3-D image registration, which involves aligning two or more images, is a critical step in a variety of medical applications from diagnosis to therapy. Image registration is commonly performed by optimizing an image matching metric as a cost function. However, this task is challenging due to the non-convex nature of the matching metric over the plausible registration parameter space and insufficient approaches for a robust optimization. As a result, current approaches are often customized to a specific problem and sensitive to image quality and artifacts. In this paper, we propose a completely different approach to image registration, inspired by how experts perform the task. We first cast the image registration problem as a "strategy learning" process, where the goal is to find the best sequence of motion actions (e.g. up, down, etc.) that yields image alignment. Within this approach, an artificial agent is learned, modeled using deep convolutional neural networks, with 3D raw image data as the input, and the next optimal action as the output. To cope with the dimensionality of the problem, we propose a greedy supervised approach for an end-to-end training, coupled with attention-driven hierarchical strategy. The resulting registration approach inherently encodes both a data-driven matching metric and an optimal registration strategy (policy). We demonstrate, on two 3-D/3-D medical image registration examples with drastically different nature of challenges, that the artificial agent outperforms several state-of-art registration methods by a large margin in terms of both accuracy and robustness.