 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large Scale Event-based Detection Dataset for Automotive
Jan 31, 2020
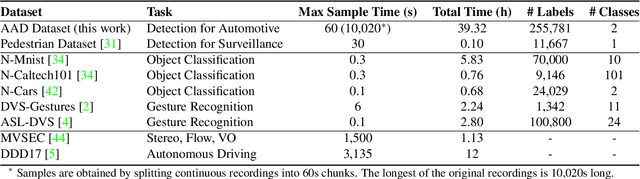

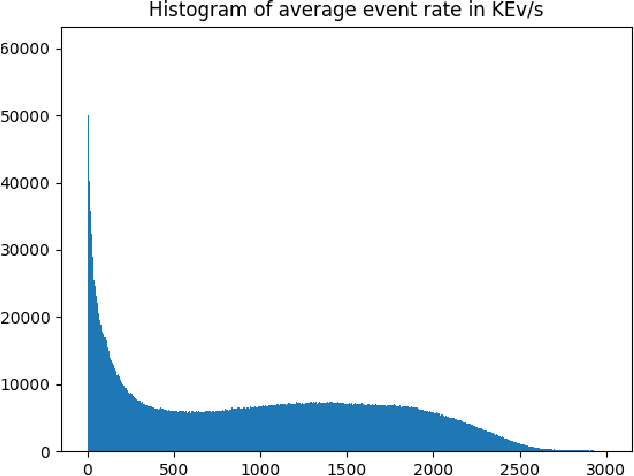
We introduce the first very large detection dataset for event cameras. The dataset is composed of more than 39 hours of automotive recordings acquired with a 304x240 ATIS sensor. It contains open roads and very diverse driving scenarios, ranging from urban, highway, suburbs and countryside scenes, as well as different weather and illumination conditions. Manual bounding box annotations of cars and pedestrians contained in the recordings are also provided at a frequency between 1 and 4Hz, yielding more than 255,000 labels in total. We believe that the availability of a labeled dataset of this size will contribute to major advances in event-based vision tasks such as object detection and classification. We also expect benefits in other tasks such as optical flow, structure from motion and tracking, where for example, the large amount of data can be leveraged by self-supervised learning methods.
Speed Invariant Time Surface for Learning to Detect Corner Points with Event-Based Cameras
Apr 30, 2019
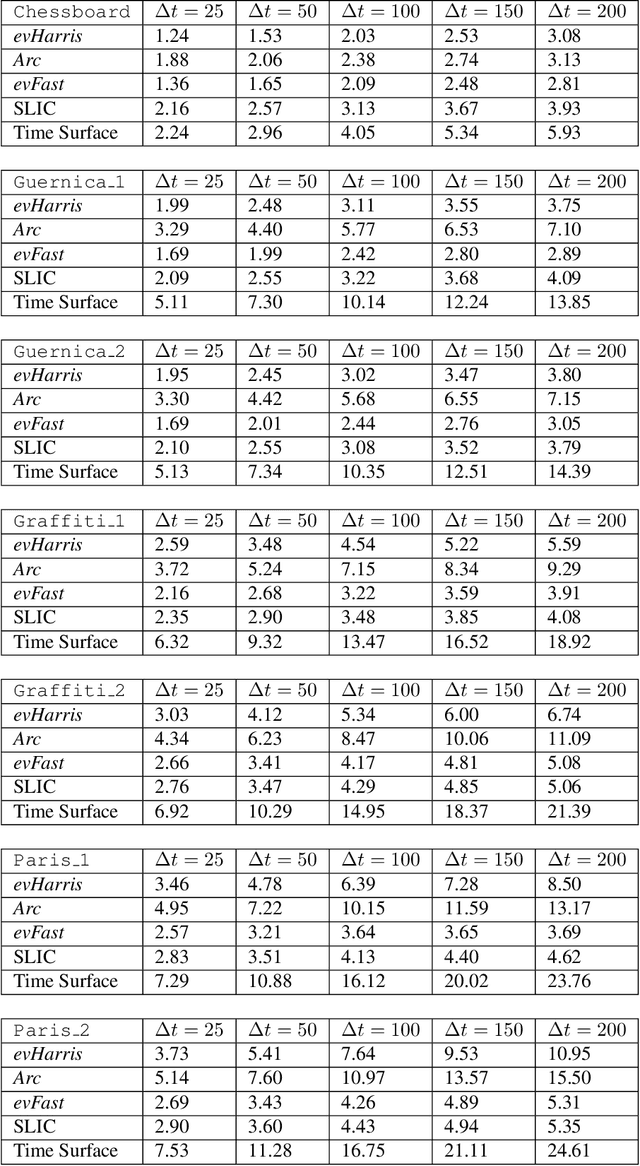

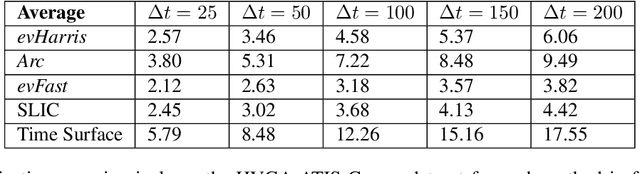
We propose a learning approach to corner detection for event-based cameras that is stable even under fast and abrupt motions. Event-based cameras offer high temporal resolution, power efficiency, and high dynamic range. However, the properties of event-based data are very different compared to standard intensity images, and simple extensions of corner detection methods designed for these images do not perform well on event-based data. We first introduce an efficient way to compute a time surface that is invariant to the speed of the objects. We then show that we can train a Random Forest to recognize events generated by a moving corner from our time surface. Random Forests are also extremely efficient, and therefore a good choice to deal with the high capture frequency of event-based cameras ---our implementation processes up to 1.6Mev/s on a single CPU. Thanks to our time surface formulation and this learning approach, our method is significantly more robust to abrupt changes of direction of the corners compared to previous ones. Our method also naturally assigns a confidence score for the corners, which can be useful for postprocessing. Moreover, we introduce a high-resolution dataset suitable for quantitative evaluation and comparison of corner detection methods for event-based cameras. We call our approach SILC, for Speed Invariant Learned Corners, and compare it to the state-of-the-art with extensive experiments, showing better performance.
Descriptor learning for omnidirectional image matching
Dec 29, 2011
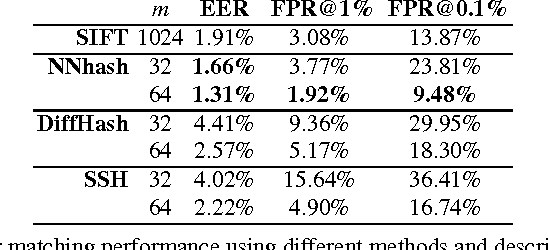
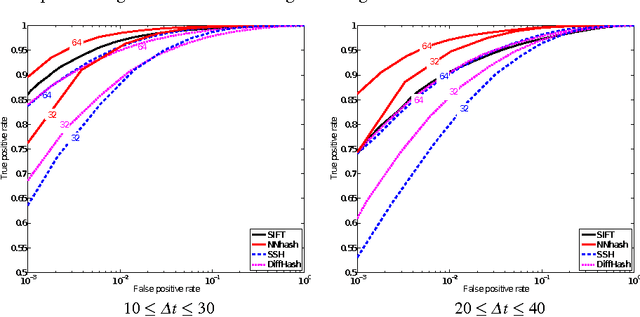

Feature matching in omnidirectional vision systems is a challenging problem, mainly because complicated optical systems make the theoretical modelling of invariance and construction of invariant feature descriptors hard or even impossible. In this paper, we propose learning invariant descriptors using a training set of similar and dissimilar descriptor pairs. We use the similarity-preserving hashing framework, in which we are trying to map the descriptor data to the Hamming space preserving the descriptor similarity on the training set. A neural network is used to solve the underlying optimization problem. Our approach outperforms not only straightforward descriptor matching, but also state-of-the-art similarity-preserving hashing methods.