 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Lived Accurate Keypoints in Event Streams
Oct 07, 2022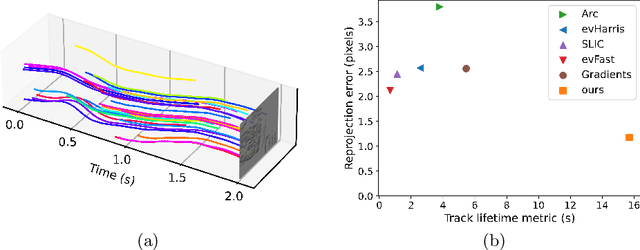
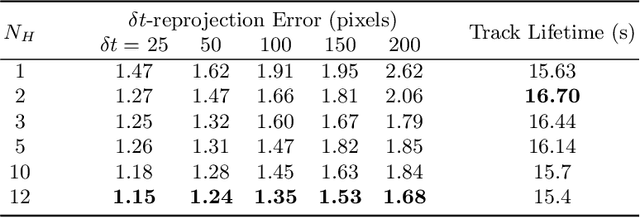
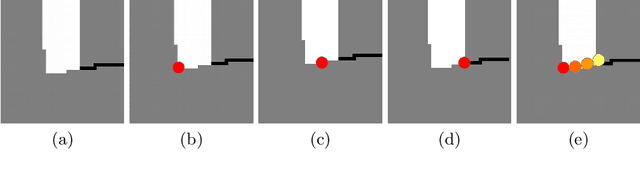
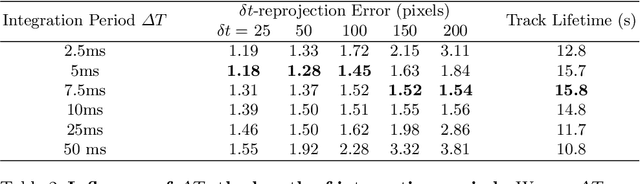
We present a novel end-to-end approach to keypoint detection and tracking in an event stream that provides better precision and much longer keypoint tracks than previous methods. This is made possible by two contributions working together. First, we propose a simple procedure to generate stable keypoint labels, which we use to train a recurrent architecture. This training data results in detections that are very consistent over time. Moreover, we observe that previous methods for keypoint detection work on a representation (such as the time surface) that integrates events over a period of time. Since this integration is required, we claim it is better to predict the keypoints' trajectories for the time period rather than single locations, as done in previous approaches. We predict these trajectories in the form of a series of heatmaps for the integration time period. This improves the keypoint localization. Our architecture can also be kept very simple, which results in very fast inference times. We demonstrate our approach on the HVGA ATIS Corner dataset as well as "The Event-Camera Dataset and Simulator" dataset, and show it results in keypoint tracks that are three times longer and nearly twice as accurate as the best previous state-of-the-art methods. We believe our approach can be generalized to other event-based camera problems, and we release our source code to encourage other authors to explore it.
Real-Time Face & Eye Tracking and Blink Detection using Event Cameras
Oct 16, 2020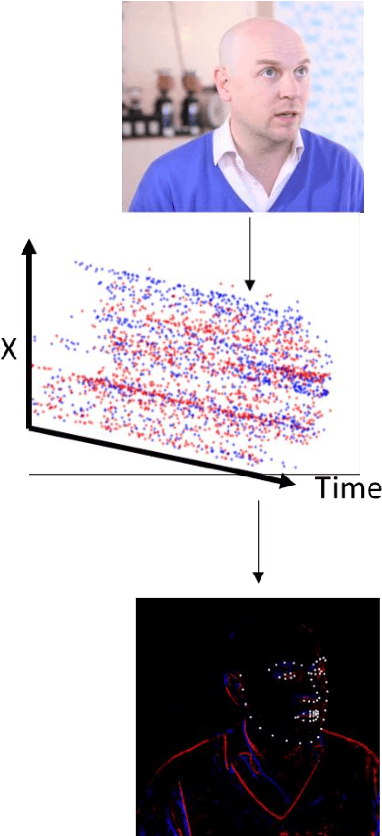

Event cameras contain emerging, neuromorphic vision sensors that capture local light intensity changes at each pixel, generating a stream of asynchronous events. This way of acquiring visual information constitutes a departure from traditional frame based cameras and offers several significant advantages: low energy consumption, high temporal resolution, high dynamic range and low latency. Driver monitoring systems (DMS) are in-cabin safety systems designed to sense and understand a drivers physical and cognitive state. Event cameras are particularly suited to DMS due to their inherent advantages. This paper proposes a novel method to simultaneously detect and track faces and eyes for driver monitoring. A unique, fully convolutional recurrent neural network architecture is presented. To train this network, a synthetic event-based dataset is simulated with accurate bounding box annotations, called Neuromorphic HELEN. Additionally, a method to detect and analyse drivers eye blinks is proposed, exploiting the high temporal resolution of event cameras. Behaviour of blinking provides greater insights into a driver level of fatigue or drowsiness. We show that blinks have a unique temporal signature that can be better captured by event cameras.
Learning to Detect Objects with a 1 Megapixel Event Camera
Sep 28, 2020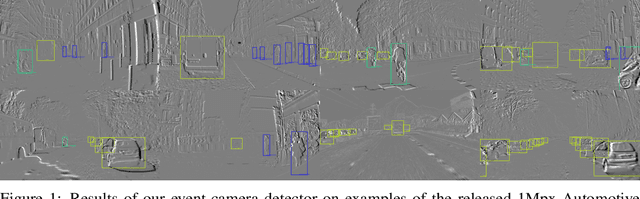

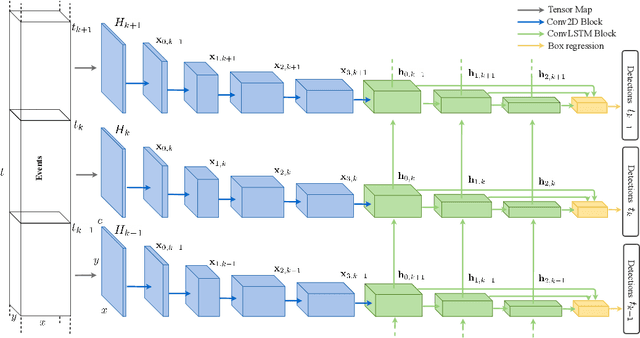
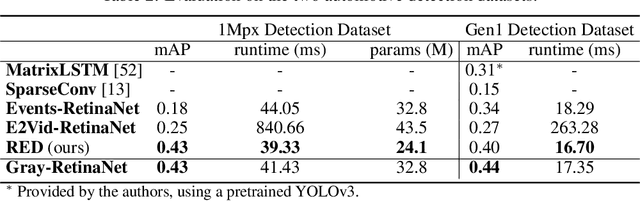
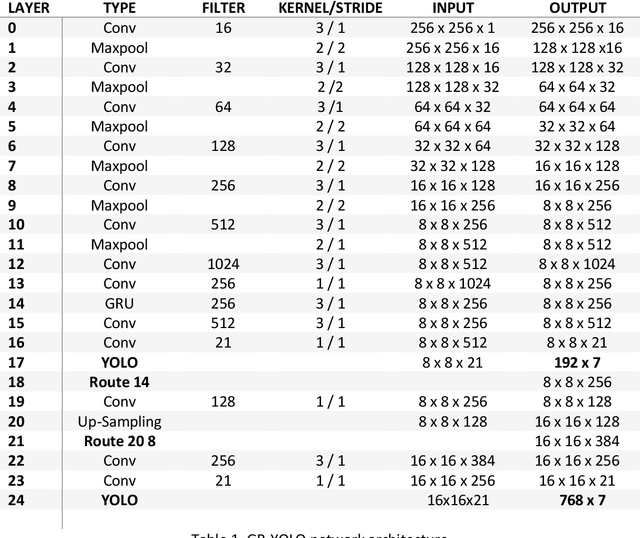
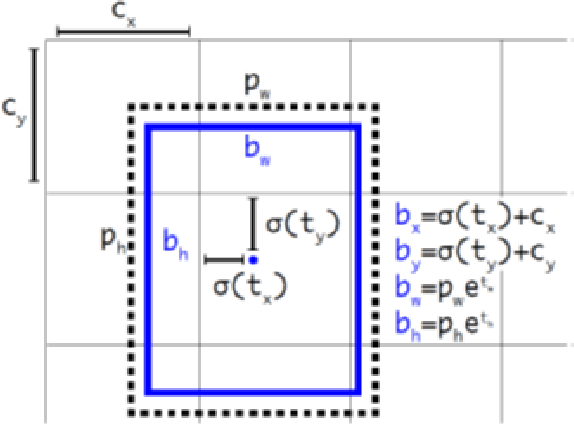
Event cameras encode visual information with high temporal precision, low data-rate, and high-dynamic range. Thanks to these characteristics, event cameras are particularly suited for scenarios with high motion, challenging lighting conditions and requiring low latency. However, due to the novelty of the field, the performance of event-based systems on many vision tasks is still lower compared to conventional frame-based solutions. The main reasons for this performance gap are: the lower spatial resolution of event sensors, compared to frame cameras; the lack of large-scale training datasets; the absence of well established deep learning architectures for event-based processing. In this paper, we address all these problems in the context of an event-based object detection task. First, we publicly release the first high-resolution large-scale dataset for object detection. The dataset contains more than 14 hours recordings of a 1 megapixel event camera, in automotive scenarios, together with 25M bounding boxes of cars, pedestrians, and two-wheelers, labeled at high frequency. Second, we introduce a novel recurrent architecture for event-based detection and a temporal consistency loss for better-behaved training. The ability to compactly represent the sequence of events into the internal memory of the model is essential to achieve high accuracy. Our model outperforms by a large margin feed-forward event-based architectures. Moreover, our method does not require any reconstruction of intensity images from events, showing that training directly from raw events is possible, more efficient, and more accurate than passing through an intermediate intensity image. Experiments on the dataset introduced in this work, for which events and gray level images are available, show performance on par with that of highly tuned and studied frame-based detectors.
A Large Scale Event-based Detection Dataset for Automotive
Jan 31, 2020
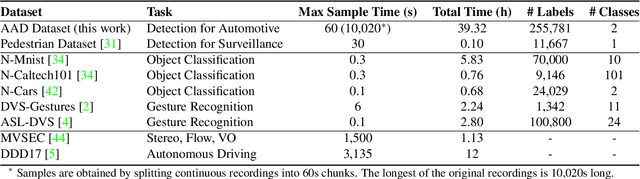

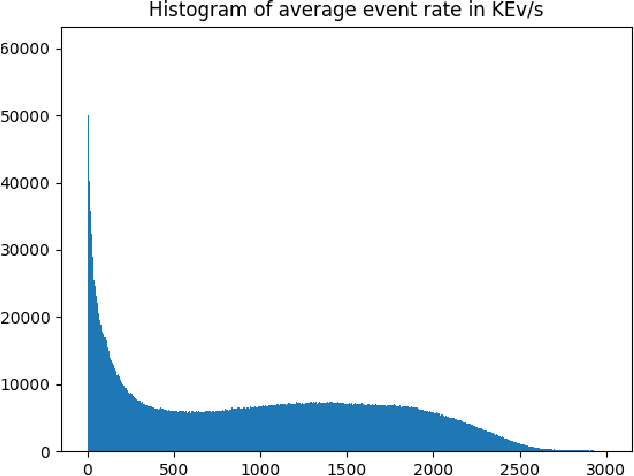
We introduce the first very large detection dataset for event cameras. The dataset is composed of more than 39 hours of automotive recordings acquired with a 304x240 ATIS sensor. It contains open roads and very diverse driving scenarios, ranging from urban, highway, suburbs and countryside scenes, as well as different weather and illumination conditions. Manual bounding box annotations of cars and pedestrians contained in the recordings are also provided at a frequency between 1 and 4Hz, yielding more than 255,000 labels in total. We believe that the availability of a labeled dataset of this size will contribute to major advances in event-based vision tasks such as object detection and classification. We also expect benefits in other tasks such as optical flow, structure from motion and tracking, where for example, the large amount of data can be leveraged by self-supervised learning methods.
End-to-End Race Driving with Deep Reinforcement Learning
Aug 31, 2018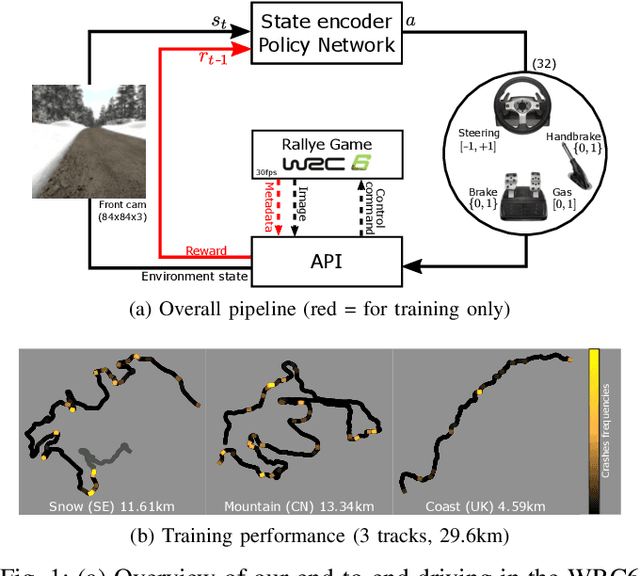
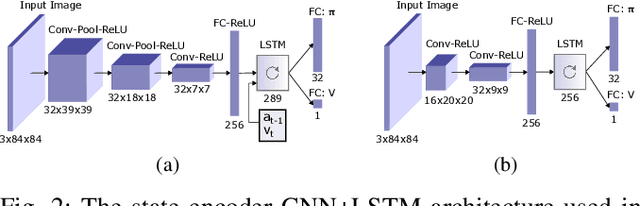
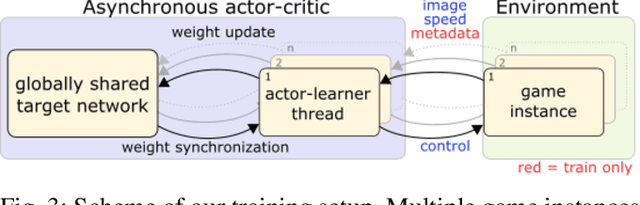
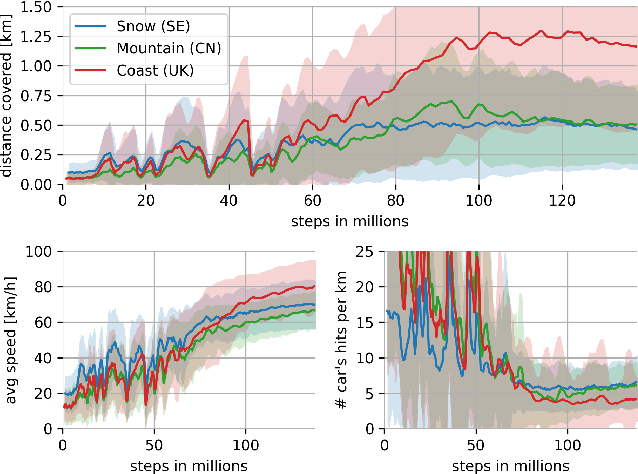
We present research using the latest reinforcement learning algorithm for end-to-end driving without any mediated perception (object recognition, scene understanding). The newly proposed reward and learning strategies lead together to faster convergence and more robust driving using only RGB image from a forward facing camera. An Asynchronous Actor Critic (A3C) framework is used to learn the car control in a physically and graphically realistic rally game, with the agents evolving simultaneously on tracks with a variety of road structures (turns, hills), graphics (seasons, location) and physics (road adherence). A thorough evaluation is conducted and generalization is proven on unseen tracks and using legal speed limits. Open loop tests on real sequences of images show some domain adaption capability of our method.
Deep Reinforcement Learning framework for Autonomous Driving
Apr 08, 2017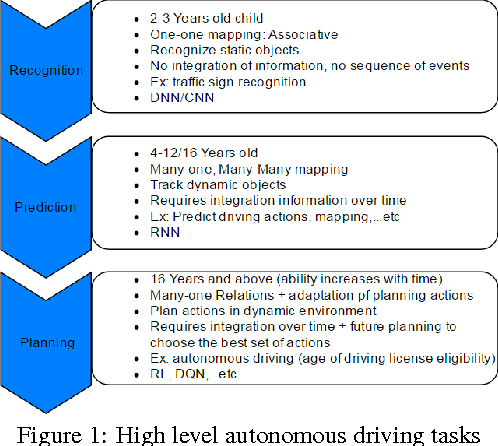
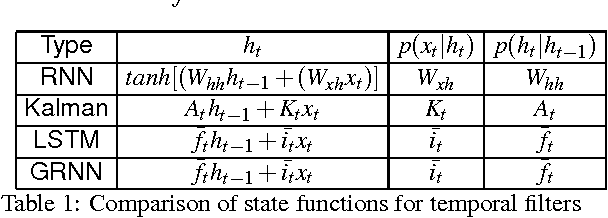

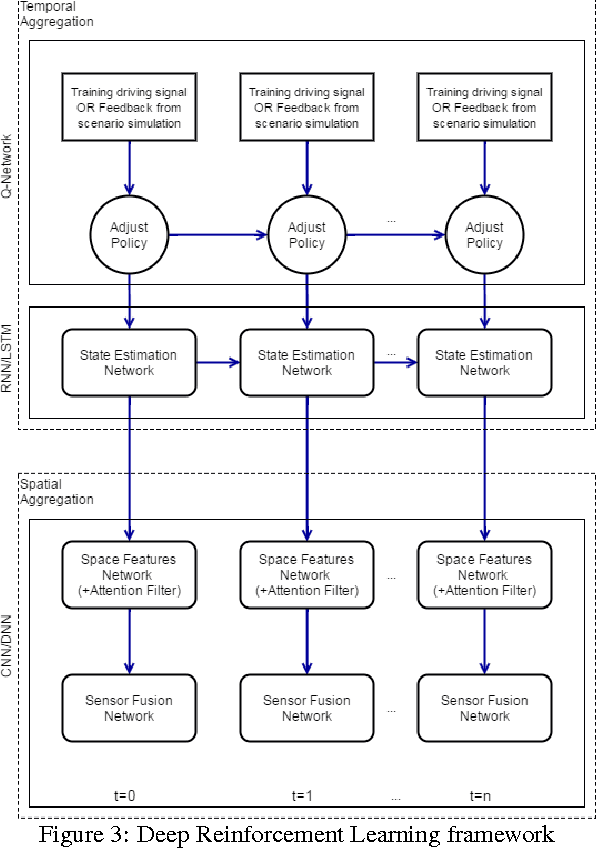
Reinforcement learning is considered to be a strong AI paradigm which can be used to teach machines through interaction with the environment and learning from their mistakes. Despite its perceived utility, it has not yet been successfully applied in automotive applications. Motivated by the successful demonstrations of learning of Atari games and Go by Google DeepMind, we propose a framework for autonomous driving using deep reinforcement learning. This is of particular relevance as it is difficult to pose autonomous driving as a supervised learning problem due to strong interactions with the environment including other vehicles, pedestrians and roadworks. As it is a relatively new area of research for autonomous driving, we provide a short overview of deep reinforcement learning and then describe our proposed framework. It incorporates Recurrent Neural Networks for information integration, enabling the car to handle partially observable scenarios. It also integrates the recent work on attention models to focus on relevant information, thereby reducing the computational complexity for deployment on embedded hardware. The framework was tested in an open source 3D car racing simulator called TORCS. Our simulation results demonstrate learning of autonomous maneuvering in a scenario of complex road curvatures and simple interaction of other vehicles.
* Reprinted with permission of IS&T: The Society for Imaging Science and Technology, sole copyright owners of Electronic Imaging, Autonomous Vehicles and Machines 2017
End-to-End Deep Reinforcement Learning for Lane Keeping Assist
Dec 13, 2016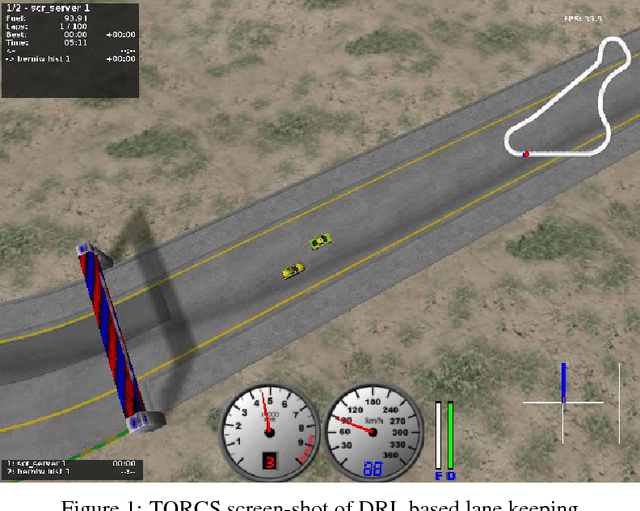

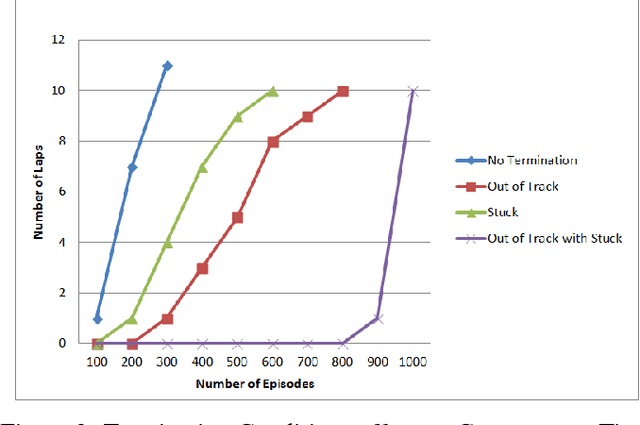
Reinforcement learning is considered to be a strong AI paradigm which can be used to teach machines through interaction with the environment and learning from their mistakes, but it has not yet been successfully used for automotive applications. There has recently been a revival of interest in the topic, however, driven by the ability of deep learning algorithms to learn good representations of the environment. Motivated by Google DeepMind's successful demonstrations of learning for games from Breakout to Go, we will propose different methods for autonomous driving using deep reinforcement learning. This is of particular interest as it is difficult to pose autonomous driving as a supervised learning problem as it has a strong interaction with the environment including other vehicles, pedestrians and roadworks. As this is a relatively new area of research for autonomous driving, we will formulate two main categories of algorithms: 1) Discrete actions category, and 2) Continuous actions category. For the discrete actions category, we will deal with Deep Q-Network Algorithm (DQN) while for the continuous actions category, we will deal with Deep Deterministic Actor Critic Algorithm (DDAC). In addition to that, We will also discover the performance of these two categories on an open source car simulator for Racing called (TORCS) which stands for The Open Racing car Simulator. Our simulation results demonstrate learning of autonomous maneuvering in a scenario of complex road curvatures and simple interaction with other vehicles. Finally, we explain the effect of some restricted conditions, put on the car during the learning phase, on the convergence time for finishing its learning phase.