 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Model Predictive Control for Deep Brain Stimulation in Parkinson's Disease
Apr 01, 2025We present a nonlinear data-driven Model Predictive Control (MPC) algorithm for deep brain stimulation (DBS) for the treatment of Parkinson's disease (PD). Although DBS is typically implemented in open-loop, closed-loop DBS (CLDBS) uses the amplitude of neural oscillations in specific frequency bands (e.g. beta 13-30 Hz) as a feedback signal, resulting in improved treatment outcomes with reduced side effects and slower rates of patient habituation to stimulation. To date, CLDBS has only been implemented in vivo with simple control algorithms, such as proportional or proportional-integral control. Our approach employs a multi-step predictor based on differences of input-convex neural networks to model the future evolution of beta oscillations. The use of a multi-step predictor enhances prediction accuracy over the optimization horizon and simplifies online computation. In tests using a simulated model of beta-band activity response and data from PD patients, we achieve reductions of more than 20% in both tracking error and control activity in comparison with existing CLDBS algorithms. The proposed control strategy provides a generalizable data-driven technique that can be applied to the treatment of PD and other diseases targeted by CLDBS, as well as to other neuromodulation techniques.
Infinite-Horizon Differentiable Model Predictive Control
Jan 07, 2020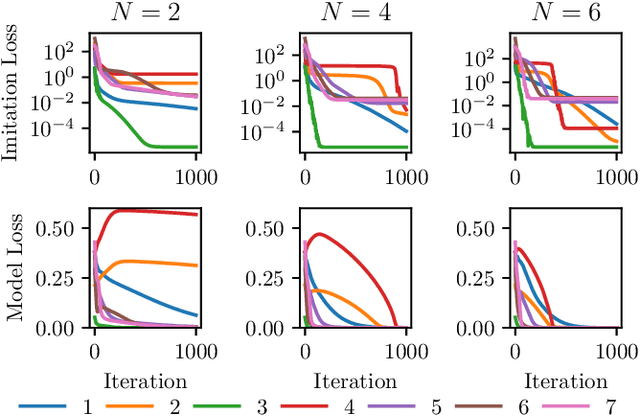
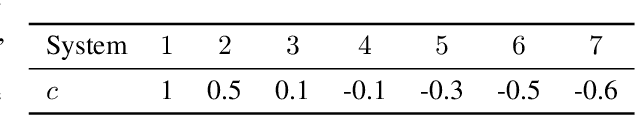

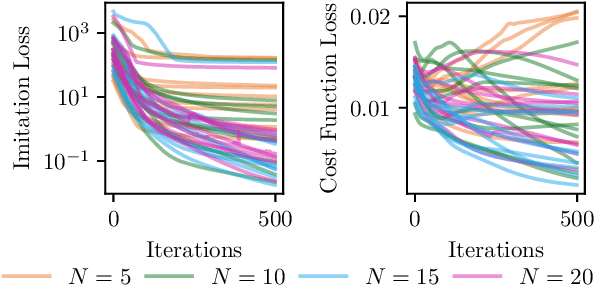
This paper proposes a differentiable linear quadratic Model Predictive Control (MPC) framework for safe imitation learning. The infinite-horizon cost is enforced using a terminal cost function obtained from the discrete-time algebraic Riccati equation (DARE), so that the learned controller can be proven to be stabilizing in closed-loop. A central contribution is the derivation of the analytical derivative of the solution of the DARE, thereby allowing the use of differentiation-based learning methods. A further contribution is the structure of the MPC optimization problem: an augmented Lagrangian method ensures that the MPC optimization is feasible throughout training whilst enforcing hard constraints on state and input, and a pre-stabilizing controller ensures that the MPC solution and derivatives are accurate at each iteration. The learning capabilities of the framework are demonstrated in a set of numerical studies.