 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Graph-structured Dataset for Wikipedia Research
Mar 20, 2019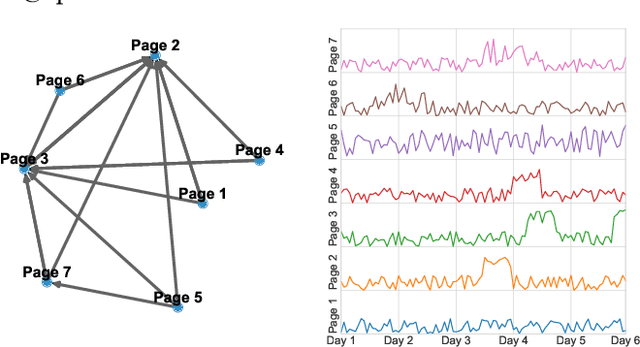


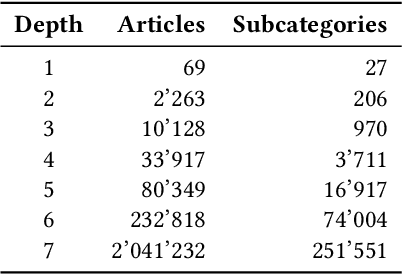
Wikipedia is a rich and invaluable source of information. Its central place on the Web makes it a particularly interesting object of study for scientists. Researchers from different domains used various complex datasets related to Wikipedia to study language, social behavior, knowledge organization, and network theory. While being a scientific treasure, the large size of the dataset hinders pre-processing and may be a challenging obstacle for potential new studies. This issue is particularly acute in scientific domains where researchers may not be technically and data processing savvy. On one hand, the size of Wikipedia dumps is large. It makes the parsing and extraction of relevant information cumbersome. On the other hand, the API is straightforward to use but restricted to a relatively small number of requests. The middle ground is at the mesoscopic scale when researchers need a subset of Wikipedia ranging from thousands to hundreds of thousands of pages but there exists no efficient solution at this scale. In this work, we propose an efficient data structure to make requests and access subnetworks of Wikipedia pages and categories. We provide convenient tools for accessing and filtering viewership statistics or "pagecounts" of Wikipedia web pages. The dataset organization leverages principles of graph databases that allows rapid and intuitive access to subgraphs of Wikipedia articles and categories. The dataset and deployment guidelines are available on the LTS2 website \url{https://lts2.epfl.ch/Datasets/Wikipedia/}.
Anomaly detection in the dynamics of web and social networks
Jan 22, 2019

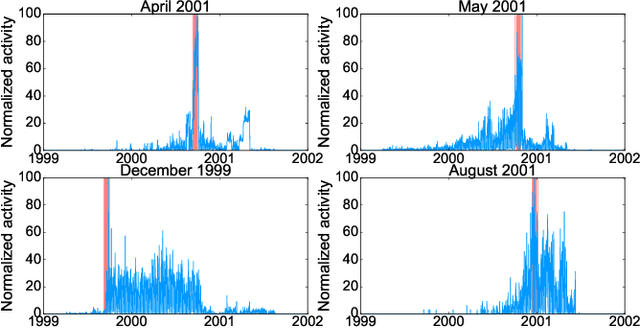

In this work, we propose a new, fast and scalable method for anomaly detection in large time-evolving graphs. It may be a static graph with dynamic node attributes (e.g. time-series), or a graph evolving in time, such as a temporal network. We define an anomaly as a localized increase in temporal activity in a cluster of nodes. The algorithm is unsupervised. It is able to detect and track anomalous activity in a dynamic network despite the noise from multiple interfering sources. We use the Hopfield network model of memory to combine the graph and time information. We show that anomalies can be spotted with a good precision using a memory network. The presented approach is scalable and we provide a distributed implementation of the algorithm. To demonstrate its efficiency, we apply it to two datasets: Enron Email dataset and Wikipedia page views. We show that the anomalous spikes are triggered by the real-world events that impact the network dynamics. Besides, the structure of the clusters and the analysis of the time evolution associated with the detected events reveals interesting facts on how humans interact, exchange and search for information, opening the door to new quantitative studies on collective and social behavior on large and dynamic datasets.