 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Improved Sentence Representations using Token Graphs
Mar 03, 2026Obtaining a single-vector representation from a Large Language Model's (LLM) token-level outputs is a critical step for nearly all sentence-level tasks. However, standard pooling methods like mean or max aggregation treat tokens as an independent set, discarding the rich relational structure captured by the model's self-attention layers and making them susceptible to signal dilution. To address this, we introduce GLOT, a lightweight, structure-aware pooling module that reframes pooling as relational learning followed by aggregation. Operating on the outputs of a frozen LLM, GLOT first constructs a latent token-similarity graph, then refines token representations with a graph neural network, and finally aggregates them using a readout layer. Experimentally, our approach is remarkably robust and efficient: on a diagnostic stress test where 90% of tokens are random distractors, GLOT maintains over 97% accuracy while baseline methods collapse. Furthermore, it is competitive with state-of-the-art techniques on benchmarks like GLUE and MTEB with 20x fewer trainable parameters and speeds up the training time by over 100x compared with parameter-efficient fine-tuning methods. Supported by a theoretical analysis of its expressive power, our work shows that learning over token graphs is a powerful paradigm for the efficient adaptation of frozen LLMs. Our code is published at https://github.com/ipsitmantri/GLOT.
Revisiting Node Affinity Prediction in Temporal Graphs
Oct 08, 2025Node affinity prediction is a common task that is widely used in temporal graph learning with applications in social and financial networks, recommender systems, and more. Recent works have addressed this task by adapting state-of-the-art dynamic link property prediction models to node affinity prediction. However, simple heuristics, such as Persistent Forecast or Moving Average, outperform these models. In this work, we analyze the challenges in training current Temporal Graph Neural Networks for node affinity prediction and suggest appropriate solutions. Combining the solutions, we develop NAViS - Node Affinity prediction model using Virtual State, by exploiting the equivalence between heuristics and state space models. While promising, training NAViS is non-trivial. Therefore, we further introduce a novel loss function for node affinity prediction. We evaluate NAViS on TGB and show that it outperforms the state-of-the-art, including heuristics. Our source code is available at https://github.com/orfeld415/NAVIS
FLASH: Flexible Learning of Adaptive Sampling from History in Temporal Graph Neural Networks
Apr 09, 2025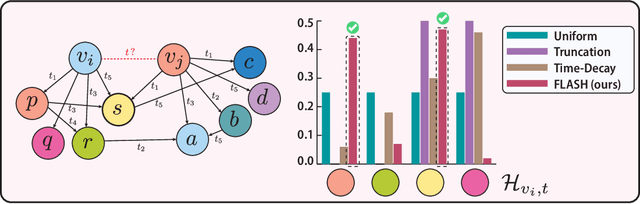

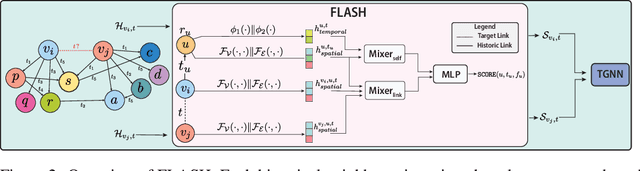

Aggregating temporal signals from historic interactions is a key step in future link prediction on dynamic graphs. However, incorporating long histories is resource-intensive. Hence, temporal graph neural networks (TGNNs) often rely on historical neighbors sampling heuristics such as uniform sampling or recent neighbors selection. These heuristics are static and fail to adapt to the underlying graph structure. We introduce FLASH, a learnable and graph-adaptive neighborhood selection mechanism that generalizes existing heuristics. FLASH integrates seamlessly into TGNNs and is trained end-to-end using a self-supervised ranking loss. We provide theoretical evidence that commonly used heuristics hinders TGNNs performance, motivating our design. Extensive experiments across multiple benchmarks demonstrate consistent and significant performance improvements for TGNNs equipped with FLASH.
DiTASK: Multi-Task Fine-Tuning with Diffeomorphic Transformations
Feb 09, 2025Pre-trained Vision Transformers now serve as powerful tools for computer vision. Yet, efficiently adapting them for multiple tasks remains a challenge that arises from the need to modify the rich hidden representations encoded by the learned weight matrices, without inducing interference between tasks. Current parameter-efficient methods like LoRA, which apply low-rank updates, force tasks to compete within constrained subspaces, ultimately degrading performance. We introduce DiTASK a novel Diffeomorphic Multi-Task Fine-Tuning approach that maintains pre-trained representations by preserving weight matrix singular vectors, while enabling task-specific adaptations through neural diffeomorphic transformations of the singular values. By following this approach, DiTASK enables both shared and task-specific feature modulations with minimal added parameters. Our theoretical analysis shows that DITASK achieves full-rank updates during optimization, preserving the geometric structure of pre-trained features, and establishing a new paradigm for efficient multi-task learning (MTL). Our experiments on PASCAL MTL and NYUD show that DiTASK achieves state-of-the-art performance across four dense prediction tasks, using 75% fewer parameters than existing methods.
OptiChat: Bridging Optimization Models and Practitioners with Large Language Models
Jan 14, 2025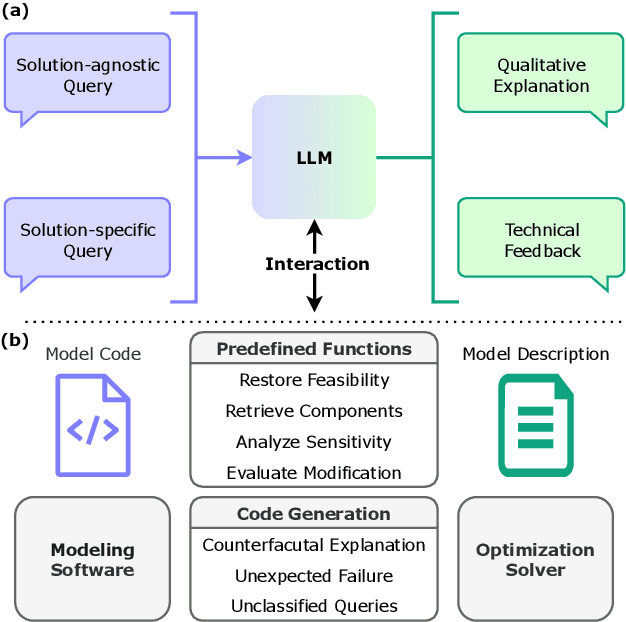


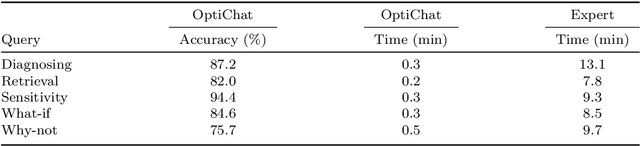
Optimization models have been applied to solve a wide variety of decision-making problems. These models are usually developed by optimization experts but are used by practitioners without optimization expertise in various application domains. As a result, practitioners often struggle to interact with and draw useful conclusions from optimization models independently. To fill this gap, we introduce OptiChat, a natural language dialogue system designed to help practitioners interpret model formulation, diagnose infeasibility, analyze sensitivity, retrieve information, evaluate modifications, and provide counterfactual explanations. By augmenting large language models (LLMs) with functional calls and code generation tailored for optimization models, we enable seamless interaction and minimize the risk of hallucinations in OptiChat. We develop a new dataset to evaluate OptiChat's performance in explaining optimization models. Experiments demonstrate that OptiChat effectively bridges the gap between optimization models and practitioners, delivering autonomous, accurate, and instant responses.
DiGRAF: Diffeomorphic Graph-Adaptive Activation Function
Jul 02, 2024



In this paper, we propose a novel activation function tailored specifically for graph data in Graph Neural Networks (GNNs). Motivated by the need for graph-adaptive and flexible activation functions, we introduce DiGRAF, leveraging Continuous Piecewise-Affine Based (CPAB) transformations, which we augment with an additional GNN to learn a graph-adaptive diffeomorphic activation function in an end-to-end manner. In addition to its graph-adaptivity and flexibility, DiGRAF also possesses properties that are widely recognized as desirable for activation functions, such as differentiability, boundness within the domain and computational efficiency. We conduct an extensive set of experiments across diverse datasets and tasks, demonstrating a consistent and superior performance of DiGRAF compared to traditional and graph-specific activation functions, highlighting its effectiveness as an activation function for GNNs.
RWKV: Reinventing RNNs for the Transformer Era
May 22, 2023



Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability. We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of Transformers with the efficient inference of RNNs. Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transformer or an RNN, which parallelizes computations during training and maintains constant computational and memory complexity during inference, leading to the first non-transformer architecture to be scaled to tens of billions of parameters. Our experiments reveal that RWKV performs on par with similarly sized Transformers, suggesting that future work can leverage this architecture to create more efficient models. This work presents a significant step towards reconciling the trade-offs between computational efficiency and model performance in sequence processing tasks.