 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRicher Bayesian Last Layers with Subsampled NTK Features
Feb 01, 2026Bayesian Last Layers (BLLs) provide a convenient and computationally efficient way to estimate uncertainty in neural networks. However, they underestimate epistemic uncertainty because they apply a Bayesian treatment only to the final layer, ignoring uncertainty induced by earlier layers. We propose a method that improves BLLs by leveraging a projection of Neural Tangent Kernel (NTK) features onto the space spanned by the last-layer features. This enables posterior inference that accounts for variability of the full network while retaining the low computational cost of inference of a standard BLL. We show that our method yields posterior variances that are provably greater or equal to those of a standard BLL, correcting its tendency to underestimate epistemic uncertainty. To further reduce computational cost, we introduce a uniform subsampling scheme for estimating the projection matrix and for posterior inference. We derive approximation bounds for both types of sub-sampling. Empirical evaluations on UCI regression, contextual bandits, image classification, and out-of-distribution detection tasks in image and tabular datasets, demonstrate improved calibration and uncertainty estimates compared to standard BLLs and competitive baselines, while reducing computational cost.
Scalable Generalized Bayesian Online Neural Network Training for Sequential Decision Making
Jun 13, 2025We introduce scalable algorithms for online learning and generalized Bayesian inference of neural network parameters, designed for sequential decision making tasks. Our methods combine the strengths of frequentist and Bayesian filtering, which include fast low-rank updates via a block-diagonal approximation of the parameter error covariance, and a well-defined posterior predictive distribution that we use for decision making. More precisely, our main method updates a low-rank error covariance for the hidden layers parameters, and a full-rank error covariance for the final layer parameters. Although this characterizes an improper posterior, we show that the resulting posterior predictive distribution is well-defined. Our methods update all network parameters online, with no need for replay buffers or offline retraining. We show, empirically, that our methods achieve a competitive tradeoff between speed and accuracy on (non-stationary) contextual bandit problems and Bayesian optimization problems.
Rough Transformers: Lightweight Continuous-Time Sequence Modelling with Path Signatures
May 31, 2024Time-series data in real-world settings typically exhibit long-range dependencies and are observed at non-uniform intervals. In these settings, traditional sequence-based recurrent models struggle. To overcome this, researchers often replace recurrent architectures with Neural ODE-based models to account for irregularly sampled data and use Transformer-based architectures to account for long-range dependencies. Despite the success of these two approaches, both incur very high computational costs for input sequences of even moderate length. To address this challenge, we introduce the Rough Transformer, a variation of the Transformer model that operates on continuous-time representations of input sequences and incurs significantly lower computational costs. In particular, we propose \textit{multi-view signature attention}, which uses path signatures to augment vanilla attention and to capture both local and global (multi-scale) dependencies in the input data, while remaining robust to changes in the sequence length and sampling frequency and yielding improved spatial processing. We find that, on a variety of time-series-related tasks, Rough Transformers consistently outperform their vanilla attention counterparts while obtaining the representational benefits of Neural ODE-based models, all at a fraction of the computational time and memory resources.
Rough Transformers for Continuous and Efficient Time-Series Modelling
Mar 15, 2024Time-series data in real-world medical settings typically exhibit long-range dependencies and are observed at non-uniform intervals. In such contexts, traditional sequence-based recurrent models struggle. To overcome this, researchers replace recurrent architectures with Neural ODE-based models to model irregularly sampled data and use Transformer-based architectures to account for long-range dependencies. Despite the success of these two approaches, both incur very high computational costs for input sequences of moderate lengths and greater. To mitigate this, we introduce the Rough Transformer, a variation of the Transformer model which operates on continuous-time representations of input sequences and incurs significantly reduced computational costs, critical for addressing long-range dependencies common in medical contexts. In particular, we propose multi-view signature attention, which uses path signatures to augment vanilla attention and to capture both local and global dependencies in input data, while remaining robust to changes in the sequence length and sampling frequency. We find that Rough Transformers consistently outperform their vanilla attention counterparts while obtaining the benefits of Neural ODE-based models using a fraction of the computational time and memory resources on synthetic and real-world time-series tasks.
Detecting Toxic Flow
Dec 10, 2023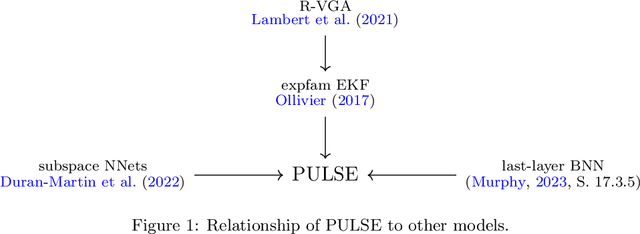
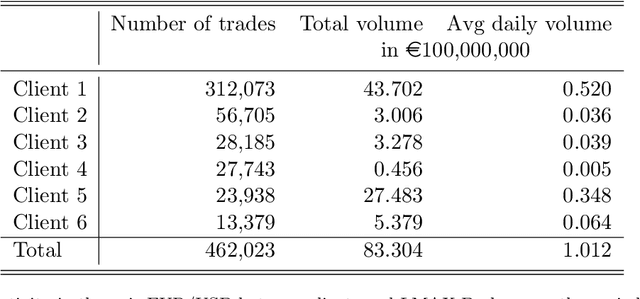
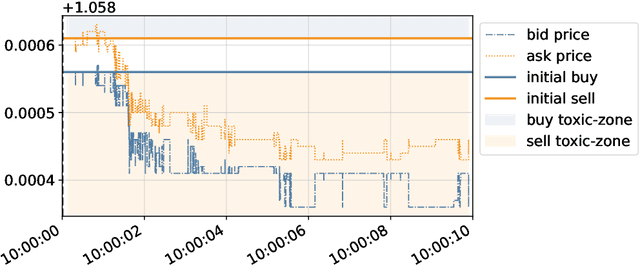
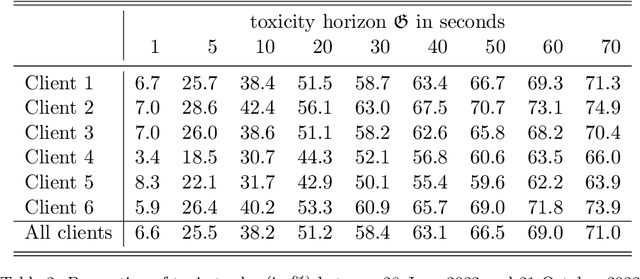
This paper develops a framework to predict toxic trades that a broker receives from her clients. Toxic trades are predicted with a novel online Bayesian method which we call the projection-based unification of last-layer and subspace estimation (PULSE). PULSE is a fast and statistically-efficient online procedure to train a Bayesian neural network sequentially. We employ a proprietary dataset of foreign exchange transactions to test our methodology. PULSE outperforms standard machine learning and statistical methods when predicting if a trade will be toxic; the benchmark methods are logistic regression, random forests, and a recursively-updated maximum-likelihood estimator. We devise a strategy for the broker who uses toxicity predictions to internalise or to externalise each trade received from her clients. Our methodology can be implemented in real-time because it takes less than one millisecond to update parameters and make a prediction. Compared with the benchmarks, PULSE attains the highest PnL and the largest avoided loss for the horizons we consider.
Conditionally Elicitable Dynamic Risk Measures for Deep Reinforcement Learning
Jun 29, 2022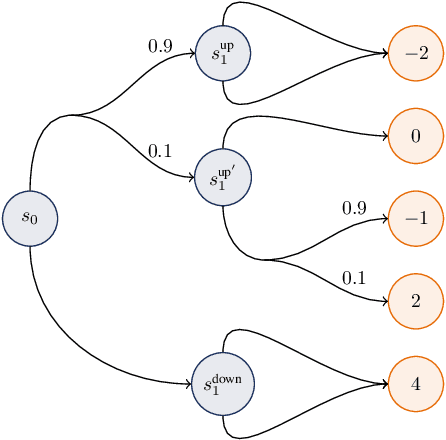
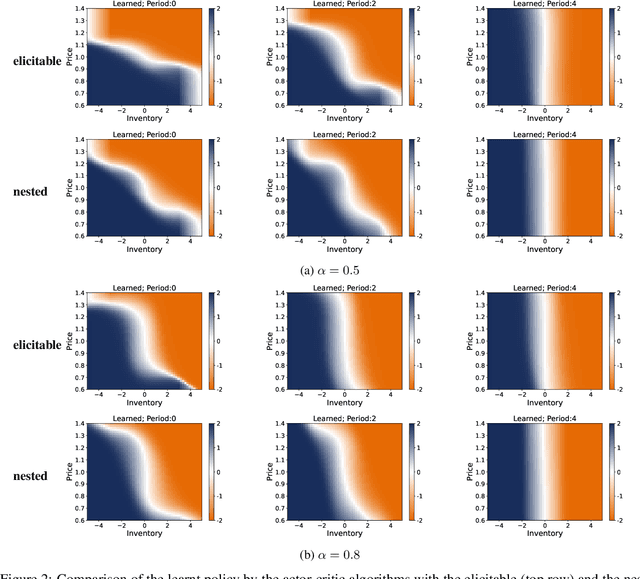
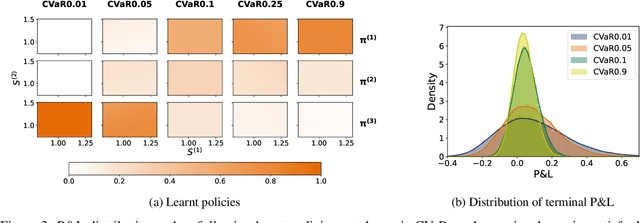
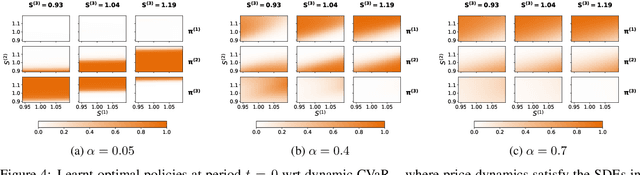
We propose a novel framework to solve risk-sensitive reinforcement learning (RL) problems where the agent optimises time-consistent dynamic spectral risk measures. Based on the notion of conditional elicitability, our methodology constructs (strictly consistent) scoring functions that are used as penalizers in the estimation procedure. Our contribution is threefold: we (i) devise an efficient approach to estimate a class of dynamic spectral risk measures with deep neural networks, (ii) prove that these dynamic spectral risk measures may be approximated to any arbitrary accuracy using deep neural networks, and (iii) develop a risk-sensitive actor-critic algorithm that uses full episodes and does not require any additional nested transitions. We compare our conceptually improved reinforcement learning algorithm with the nested simulation approach and illustrate its performance in two settings: statistical arbitrage and portfolio allocation on both simulated and real data.