 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant-Based Diagnostics for Graph Benchmarks
May 07, 2026Progress on graph foundation models is hindered by benchmark practices that conflate the contributions of node features and graph structure, making it hard to tell whether a model actually learns from connectivity, or whether it even needs to. We propose addressing this using graph invariants, i.e., permutation-invariant, task-agnostic structural descriptors that serve as a diagnostic framework for graph benchmarks. We show that (i) invariants are more expressive than standard GNNs, (ii) invariants characterize structural heterogeneity within and across benchmark datasets, (iii) invariants predict multi-task performance, and (iv) simple invariant-based models are competitive with, and sometimes exceed, transformer and message-passing baselines across 26 datasets. Our results suggest that expressivity is not the main driver of predictive performance, and that on tasks where structure matters, a non-trainable structural proxy often matches trained message-passing models. We thus posit that invariant baselines should become a standard for evaluating whether structure is required for a task and whether a model picks up on it, serving as a stepping stone towards graph foundation models.
Graph and Simplicial Complex Prediction Gaussian Process via the Hodgelet Representations
May 16, 2025Predicting the labels of graph-structured data is crucial in scientific applications and is often achieved using graph neural networks (GNNs). However, when data is scarce, GNNs suffer from overfitting, leading to poor performance. Recently, Gaussian processes (GPs) with graph-level inputs have been proposed as an alternative. In this work, we extend the Gaussian process framework to simplicial complexes (SCs), enabling the handling of edge-level attributes and attributes supported on higher-order simplices. We further augment the resulting SC representations by considering their Hodge decompositions, allowing us to account for homological information, such as the number of holes, in the SC. We demonstrate that our framework enhances the predictions across various applications, paving the way for GPs to be more widely used for graph and SC-level predictions.
MANTRA: The Manifold Triangulations Assemblage
Oct 03, 2024
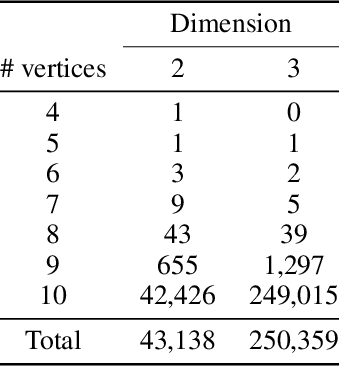

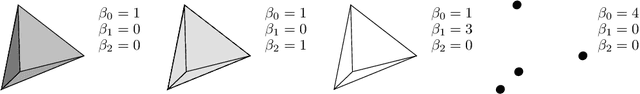
The rising interest in leveraging higher-order interactions present in complex systems has led to a surge in more expressive models exploiting high-order structures in the data, especially in topological deep learning (TDL), which designs neural networks on high-order domains such as simplicial complexes. However, progress in this field is hindered by the scarcity of datasets for benchmarking these architectures. To address this gap, we introduce MANTRA, the first large-scale, diverse, and intrinsically high order dataset for benchmarking high-order models, comprising over 43,000 and 249,000 triangulations of surfaces and three-dimensional manifolds, respectively. With MANTRA, we assess several graph- and simplicial complex-based models on three topological classification tasks. We demonstrate that while simplicial complex-based neural networks generally outperform their graph-based counterparts in capturing simple topological invariants, they also struggle, suggesting a rethink of TDL. Thus, MANTRA serves as a benchmark for assessing and advancing topological methods, leading the way for more effective high-order models.
Gaussian Processes on Cellular Complexes
Nov 02, 2023In recent years, there has been considerable interest in developing machine learning models on graphs in order to account for topological inductive biases. In particular, recent attention was given to Gaussian processes on such structures since they can additionally account for uncertainty. However, graphs are limited to modelling relations between two vertices. In this paper, we go beyond this dyadic setting and consider polyadic relations that include interactions between vertices, edges and one of their generalisations, known as cells. Specifically, we propose Gaussian processes on cellular complexes, a generalisation of graphs that captures interactions between these higher-order cells. One of our key contributions is the derivation of two novel kernels, one that generalises the graph Mat\'ern kernel and one that additionally mixes information of different cell types.
Graph Neural Networks Go Forward-Forward
Feb 10, 2023



We present the Graph Forward-Forward (GFF) algorithm, an extension of the Forward-Forward procedure to graphs, able to handle features distributed over a graph's nodes. This allows training graph neural networks with forward passes only, without backpropagation. Our method is agnostic to the message-passing scheme, and provides a more biologically plausible learning scheme than backpropagation, while also carrying computational advantages. With GFF, graph neural networks are trained greedily layer by layer, using both positive and negative samples. We run experiments on 11 standard graph property prediction tasks, showing how GFF provides an effective alternative to backpropagation for training graph neural networks. This shows in particular that this procedure is remarkably efficient in spite of combining the per-layer training with the locality of the processing in a GNN.
Implicit Variational Inference: the Parameter and the Predictor Space
Oct 24, 2020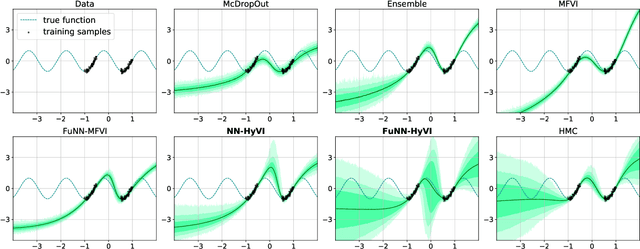
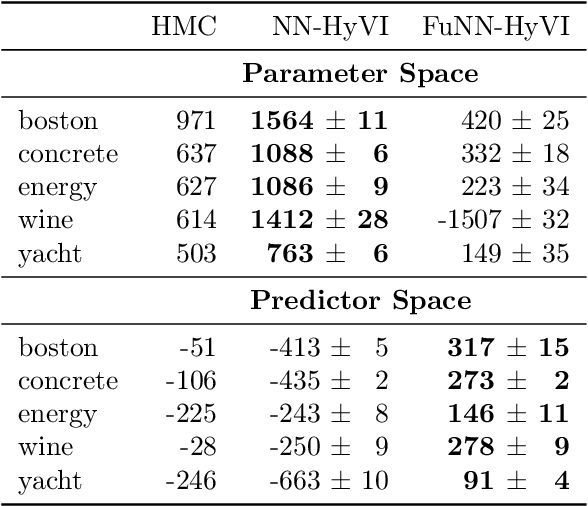
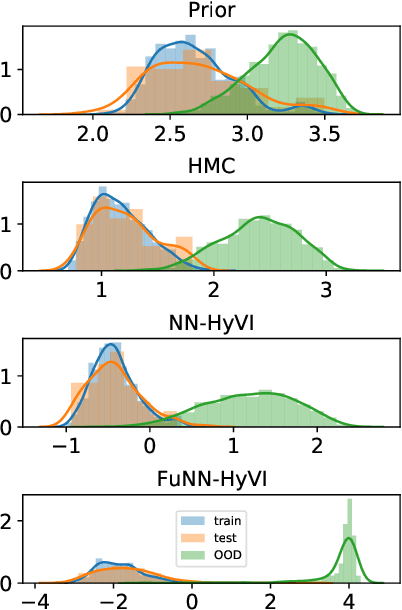
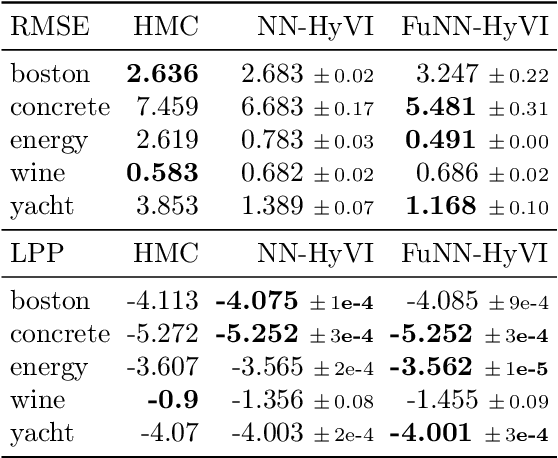
Having access to accurate confidence levels along with the predictions allows to determine whether making a decision is worth the risk. Under the Bayesian paradigm, the posterior distribution over parameters is used to capture model uncertainty, a valuable information that can be translated into predictive uncertainty. However, computing the posterior distribution for high capacity predictors, such as neural networks, is generally intractable, making approximate methods such as variational inference a promising alternative. While most methods perform inference in the space of parameters, we explore the benefits of carrying inference directly in the space of predictors. Relying on a family of distributions given by a deep generative neural network, we present two ways of carrying variational inference: one in \emph{parameter space}, one in \emph{predictor space}. Importantly, the latter requires us to choose a distribution of inputs, therefore allowing us at the same time to explicitly address the question of \emph{out-of-distribution} uncertainty. We explore from various perspectives the implications of working in the predictor space induced by neural networks as opposed to the parameter space, focusing mainly on the quality of uncertainty estimation for data lying outside of the training distribution. We compare posterior approximations obtained with these two methods to several standard methods and present results showing that variational approximations learned in the predictor space distinguish themselves positively from those trained in the parameter space.