 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised User-Based Insider Threat Detection Using Bayesian Gaussian Mixture Models
Nov 23, 2022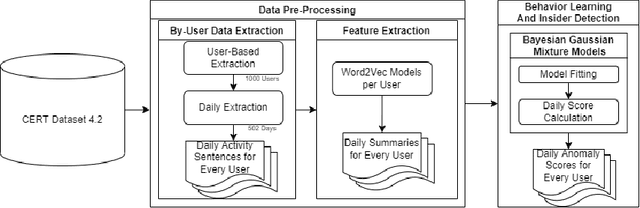



Insider threats are a growing concern for organizations due to the amount of damage that their members can inflict by combining their privileged access and domain knowledge. Nonetheless, the detection of such threats is challenging, precisely because of the ability of the authorized personnel to easily conduct malicious actions and because of the immense size and diversity of audit data produced by organizations in which the few malicious footprints are hidden. In this paper, we propose an unsupervised insider threat detection system based on audit data using Bayesian Gaussian Mixture Models. The proposed approach leverages a user-based model to optimize specific behaviors modelization and an automatic feature extraction system based on Word2Vec for ease of use in a real-life scenario. The solution distinguishes itself by not requiring data balancing nor to be trained only on normal instances, and by its little domain knowledge required to implement. Still, results indicate that the proposed method competes with state-of-the-art approaches, presenting a good recall of 88\%, accuracy and true negative rate of 93%, and a false positive rate of 6.9%. For our experiments, we used the benchmark dataset CERT version 4.2.
Implicit Variational Inference: the Parameter and the Predictor Space
Oct 24, 2020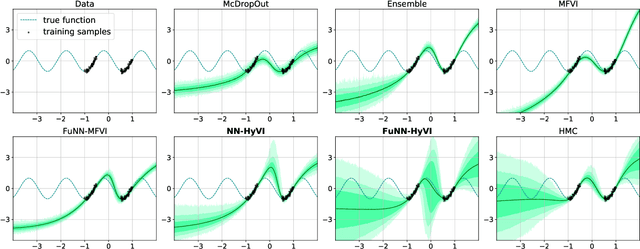
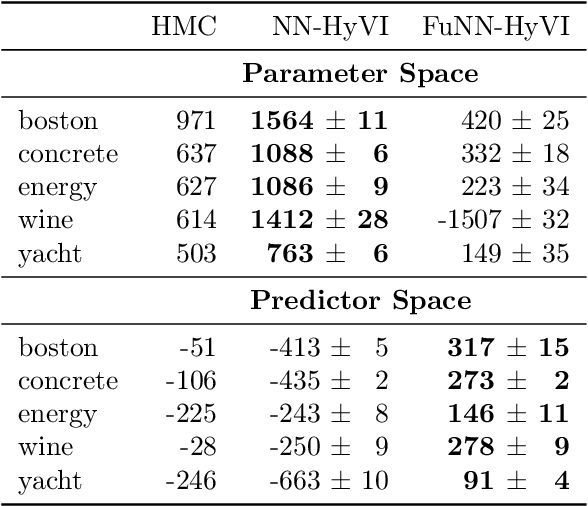
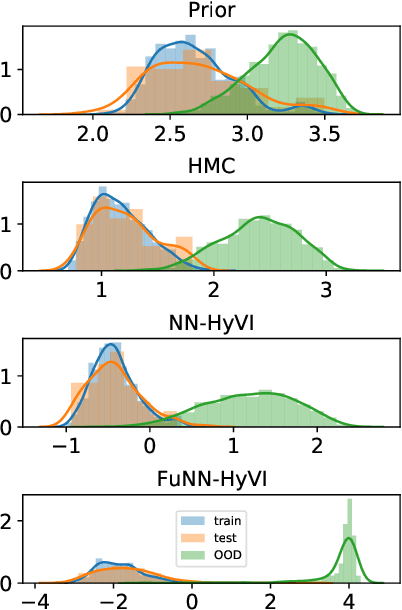
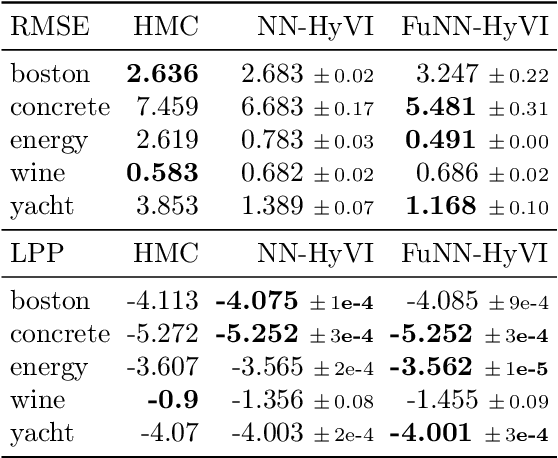
Having access to accurate confidence levels along with the predictions allows to determine whether making a decision is worth the risk. Under the Bayesian paradigm, the posterior distribution over parameters is used to capture model uncertainty, a valuable information that can be translated into predictive uncertainty. However, computing the posterior distribution for high capacity predictors, such as neural networks, is generally intractable, making approximate methods such as variational inference a promising alternative. While most methods perform inference in the space of parameters, we explore the benefits of carrying inference directly in the space of predictors. Relying on a family of distributions given by a deep generative neural network, we present two ways of carrying variational inference: one in \emph{parameter space}, one in \emph{predictor space}. Importantly, the latter requires us to choose a distribution of inputs, therefore allowing us at the same time to explicitly address the question of \emph{out-of-distribution} uncertainty. We explore from various perspectives the implications of working in the predictor space induced by neural networks as opposed to the parameter space, focusing mainly on the quality of uncertainty estimation for data lying outside of the training distribution. We compare posterior approximations obtained with these two methods to several standard methods and present results showing that variational approximations learned in the predictor space distinguish themselves positively from those trained in the parameter space.