 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Network Source Optimization with Graph-Kernel MAB
Paper and Code
Jul 07, 2023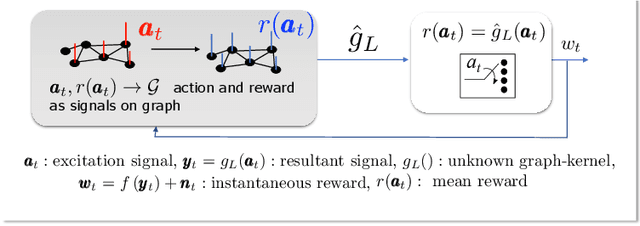
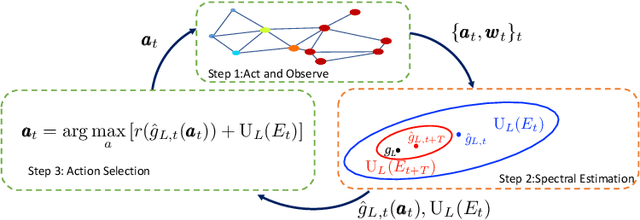
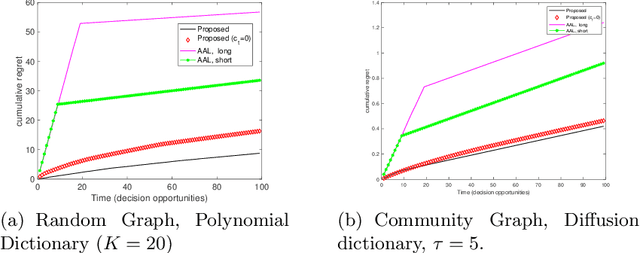
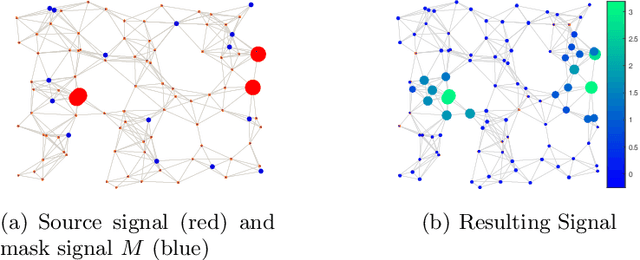
We propose Grab-UCB, a graph-kernel multi-arms bandit algorithm to learn online the optimal source placement in large scale networks, such that the reward obtained from a priori unknown network processes is maximized. The uncertainty calls for online learning, which suffers however from the curse of dimensionality. To achieve sample efficiency, we describe the network processes with an adaptive graph dictionary model, which typically leads to sparse spectral representations. This enables a data-efficient learning framework, whose learning rate scales with the dimension of the spectral representation model instead of the one of the network. We then propose Grab-UCB, an online sequential decision strategy that learns the parameters of the spectral representation while optimizing the action strategy. We derive the performance guarantees that depend on network parameters, which further influence the learning curve of the sequential decision strategy We introduce a computationally simplified solving method, Grab-arm-Light, an algorithm that walks along the edges of the polytope representing the objective function. Simulations results show that the proposed online learning algorithm outperforms baseline offline methods that typically separate the learning phase from the testing one. The results confirm the theoretical findings, and further highlight the gain of the proposed online learning strategy in terms of cumulative regret, sample efficiency and computational complexity.