 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of Random Edge-Dropping on Over-Squashing in Graph Neural Networks
Feb 11, 2025



Message Passing Neural Networks (MPNNs) are a class of Graph Neural Networks (GNNs) that leverage the graph topology to propagate messages across increasingly larger neighborhoods. The message-passing scheme leads to two distinct challenges: over-smoothing and over-squashing. While several algorithms, e.g. DropEdge and its variants -- DropNode, DropAgg and DropGNN -- have successfully addressed the over-smoothing problem, their impact on over-squashing remains largely unexplored. This represents a critical gap in the literature as failure to mitigate over-squashing would make these methods unsuitable for long-range tasks. In this work, we take the first step towards closing this gap by studying the aforementioned algorithms in the context of over-squashing. We present novel theoretical results that characterize the negative effects of DropEdge on sensitivity between distant nodes, suggesting its unsuitability for long-range tasks. Our findings are easily extended to its variants, allowing us to build a comprehensive understanding of how they affect over-squashing. We evaluate these methods using real-world datasets, demonstrating their detrimental effects. Specifically, we show that while DropEdge-variants improve test-time performance in short range tasks, they deteriorate performance in long-range ones. Our theory explains these results as follows: random edge-dropping lowers the effective receptive field of GNNs, which although beneficial for short-range tasks, misaligns the models on long-range ones. This forces the models to overfit to short-range artefacts in the training set, resulting in poor generalization. Our conclusions highlight the need to re-evaluate various methods designed for training deep GNNs, with a renewed focus on modelling long-range interactions.
LingML: Linguistic-Informed Machine Learning for Enhanced Fake News Detection
May 07, 2024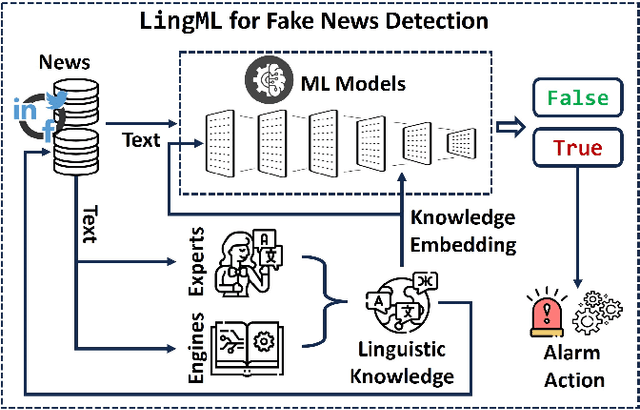
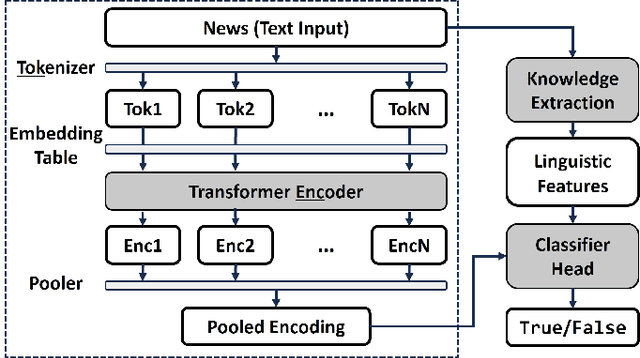

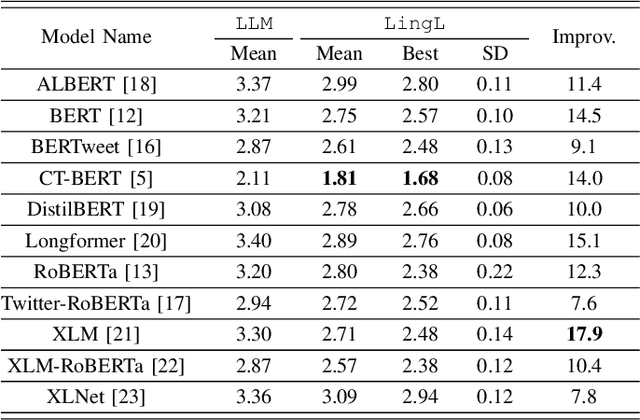
Nowadays, Information spreads at an unprecedented pace in social media and discerning truth from misinformation and fake news has become an acute societal challenge. Machine learning (ML) models have been employed to identify fake news but are far from perfect with challenging problems like limited accuracy, interpretability, and generalizability. In this paper, we enhance ML-based solutions with linguistics input and we propose LingML, linguistic-informed ML, for fake news detection. We conducted an experimental study with a popular dataset on fake news during the pandemic. The experiment results show that our proposed solution is highly effective. There are fewer than two errors out of every ten attempts with only linguistic input used in ML and the knowledge is highly explainable. When linguistics input is integrated with advanced large-scale ML models for natural language processing, our solution outperforms existing ones with 1.8% average error rate. LingML creates a new path with linguistics to push the frontier of effective and efficient fake news detection. It also sheds light on real-world multi-disciplinary applications requiring both ML and domain expertise to achieve optimal performance.
Training-Free Neural Active Learning with Initialization-Robustness Guarantees
Jun 07, 2023



Existing neural active learning algorithms have aimed to optimize the predictive performance of neural networks (NNs) by selecting data for labelling. However, other than a good predictive performance, being robust against random parameter initializations is also a crucial requirement in safety-critical applications. To this end, we introduce our expected variance with Gaussian processes (EV-GP) criterion for neural active learning, which is theoretically guaranteed to select data points which lead to trained NNs with both (a) good predictive performances and (b) initialization robustness. Importantly, our EV-GP criterion is training-free, i.e., it does not require any training of the NN during data selection, which makes it computationally efficient. We empirically demonstrate that our EV-GP criterion is highly correlated with both initialization robustness and generalization performance, and show that it consistently outperforms baseline methods in terms of both desiderata, especially in situations with limited initial data or large batch sizes.