 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Attention during Dimensional Shifts with Counterfactual and Delayed Feedback
Jan 19, 2025

Attention can be used to inform choice selection in contextual bandit tasks even when context features have not been previously experienced. One example of this is in dimensional shifts, where additional feature values are introduced and the relationship between features and outcomes can either be static or variable. Attentional mechanisms have been extensively studied in contextual bandit tasks where the feedback of choices is provided immediately, but less research has been done on tasks where feedback is delayed or in counterfactual feedback cases. Some methods have successfully modeled human attention with immediate feedback based on reward prediction errors (RPEs), though recent research raises questions of the applicability of RPEs onto more general attentional mechanisms. Alternative models suggest that information theoretic metrics can be used to model human attention, with broader applications to novel stimuli. In this paper, we compare two different methods for modeling how humans attend to specific features of decision making tasks, one that is based on calculating an information theoretic metric using a memory of past experiences, and another that is based on iteratively updating attention from reward prediction errors. We compare these models using simulations in a contextual bandit task with both intradimensional and extradimensional domain shifts, as well as immediate, delayed, and counterfactual feedback. We find that calculating an information theoretic metric over a history of experiences is best able to account for human-like behavior in tasks that shift dimensions and alter feedback presentation. These results indicate that information theoretic metrics of attentional mechanisms may be better suited than RPEs to predict human attention in decision making, though further studies of human behavior are necessary to support these results.
Leveraging a Cognitive Model to Measure Subjective Similarity of Human and GPT-4 Written Content
Aug 30, 2024



Cosine similarity between two documents can be computed using token embeddings formed by Large Language Models (LLMs) such as GPT-4, and used to categorize those documents across a range of uses. However, these similarities are ultimately dependent on the corpora used to train these LLMs, and may not reflect subjective similarity of individuals or how their biases and constraints impact similarity metrics. This lack of cognitively-aware personalization of similarity metrics can be particularly problematic in educational and recommendation settings where there is a limited number of individual judgements of category or preference, and biases can be particularly relevant. To address this, we rely on an integration of an Instance-Based Learning (IBL) cognitive model with LLM embeddings to develop the Instance-Based Individualized Similarity (IBIS) metric. This similarity metric is beneficial in that it takes into account individual biases and constraints in a manner that is grounded in the cognitive mechanisms of decision making. To evaluate the IBIS metric, we also introduce a dataset of human categorizations of emails as being either dangerous (phishing) or safe (ham). This dataset is used to demonstrate the benefits of leveraging a cognitive model to measure the subjective similarity of human participants in an educational setting.
Learning to Defend by Attacking : Transfer of Learning in Cybersecurity Games
Jun 03, 2023Designing cyber defense systems to account for cognitive biases in human decision making has demonstrated significant success in improving performance against human attackers. However, much of the attention in this area has focused on relatively simple accounts of biases in human attackers, and little is known about adversarial behavior or how defenses could be improved by disrupting attacker's behavior. In this work, we present a novel model of human decision-making inspired by the cognitive faculties of Instance-Based Learning Theory, Theory of Mind, and Transfer of Learning. This model functions by learning from both roles in a security scenario: defender and attacker, and by making predictions of the opponent's beliefs, intentions, and actions. The proposed model can better defend against attacks from a wide range of opponents compared to alternatives that attempt to perform optimally without accounting for human biases. Additionally, the proposed model performs better against a range of human-like behavior by explicitly modeling human transfer of learning, which has not yet been applied to cyber defense scenarios. Results from simulation experiments demonstrate the potential usefulness of cognitively inspired models of agents trained in attack and defense roles and how these insights could potentially be used in real-world cybersecurity.
Learning in Factored Domains with Information-Constrained Visual Representations
Mar 30, 2023Humans learn quickly even in tasks that contain complex visual information. This is due in part to the efficient formation of compressed representations of visual information, allowing for better generalization and robustness. However, compressed representations alone are insufficient for explaining the high speed of human learning. Reinforcement learning (RL) models that seek to replicate this impressive efficiency may do so through the use of factored representations of tasks. These informationally simplistic representations of tasks are similarly motivated as the use of compressed representations of visual information. Recent studies have connected biological visual perception to disentangled and compressed representations. This raises the question of how humans learn to efficiently represent visual information in a manner useful for learning tasks. In this paper we present a model of human factored representation learning based on an altered form of a $\beta$-Variational Auto-encoder used in a visual learning task. Modelling results demonstrate a trade-off in the informational complexity of model latent dimension spaces, between the speed of learning and the accuracy of reconstructions.
Consolidation via Policy Information Regularization in Deep RL for Multi-Agent Games
Nov 23, 2020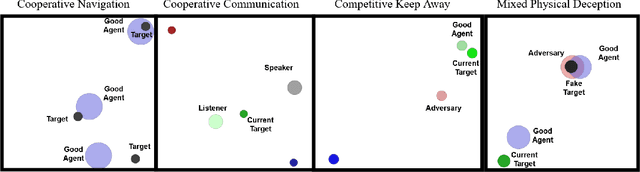
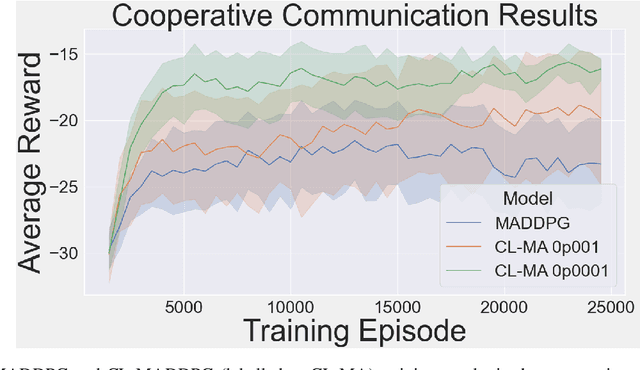
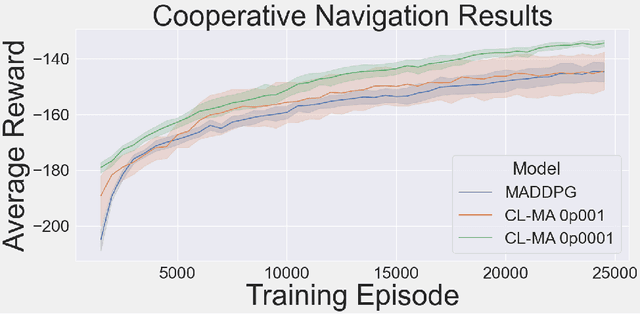
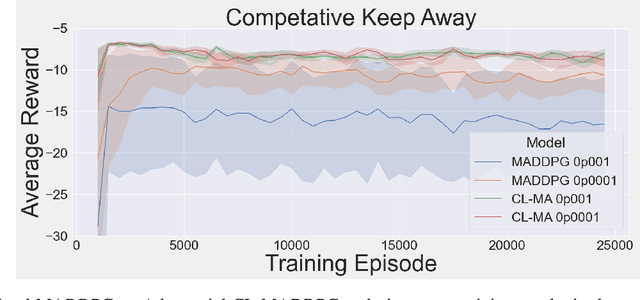
This paper introduces an information-theoretic constraint on learned policy complexity in the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) reinforcement learning algorithm. Previous research with a related approach in continuous control experiments suggests that this method favors learning policies that are more robust to changing environment dynamics. The multi-agent game setting naturally requires this type of robustness, as other agents' policies change throughout learning, introducing a nonstationary environment. For this reason, recent methods in continual learning are compared to our approach, termed Capacity-Limited MADDPG. Results from experimentation in multi-agent cooperative and competitive tasks demonstrate that the capacity-limited approach is a good candidate for improving learning performance in these environments.
Deep RL With Information Constrained Policies: Generalization in Continuous Control
Oct 09, 2020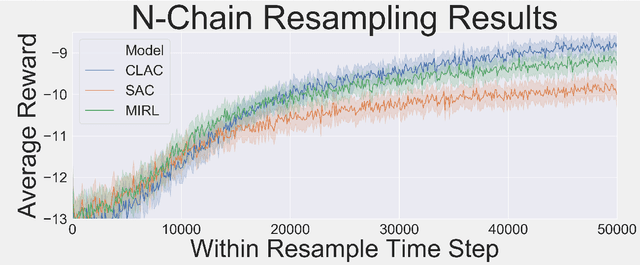
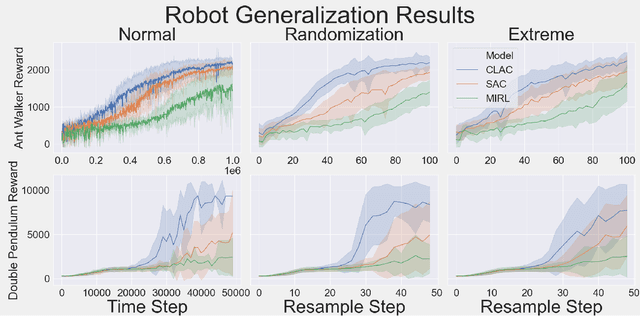
Biological agents learn and act intelligently in spite of a highly limited capacity to process and store information. Many real-world problems involve continuous control, which represents a difficult task for artificial intelligence agents. In this paper we explore the potential learning advantages a natural constraint on information flow might confer onto artificial agents in continuous control tasks. We focus on the model-free reinforcement learning (RL) setting and formalize our approach in terms of an information-theoretic constraint on the complexity of learned policies. We show that our approach emerges in a principled fashion from the application of rate-distortion theory. We implement a novel Capacity-Limited Actor-Critic (CLAC) algorithm and situate it within a broader family of RL algorithms such as the Soft Actor Critic (SAC) and Mutual Information Reinforcement Learning (MIRL) algorithm. Our experiments using continuous control tasks show that compared to alternative approaches, CLAC offers improvements in generalization between training and modified test environments. This is achieved in the CLAC model while displaying the high sample efficiency of similar methods.