 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in Factored Domains with Information-Constrained Visual Representations
Mar 30, 2023Humans learn quickly even in tasks that contain complex visual information. This is due in part to the efficient formation of compressed representations of visual information, allowing for better generalization and robustness. However, compressed representations alone are insufficient for explaining the high speed of human learning. Reinforcement learning (RL) models that seek to replicate this impressive efficiency may do so through the use of factored representations of tasks. These informationally simplistic representations of tasks are similarly motivated as the use of compressed representations of visual information. Recent studies have connected biological visual perception to disentangled and compressed representations. This raises the question of how humans learn to efficiently represent visual information in a manner useful for learning tasks. In this paper we present a model of human factored representation learning based on an altered form of a $\beta$-Variational Auto-encoder used in a visual learning task. Modelling results demonstrate a trade-off in the informational complexity of model latent dimension spaces, between the speed of learning and the accuracy of reconstructions.
Consolidation via Policy Information Regularization in Deep RL for Multi-Agent Games
Nov 23, 2020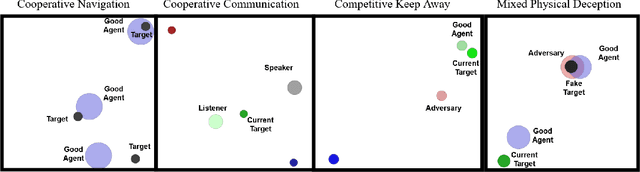
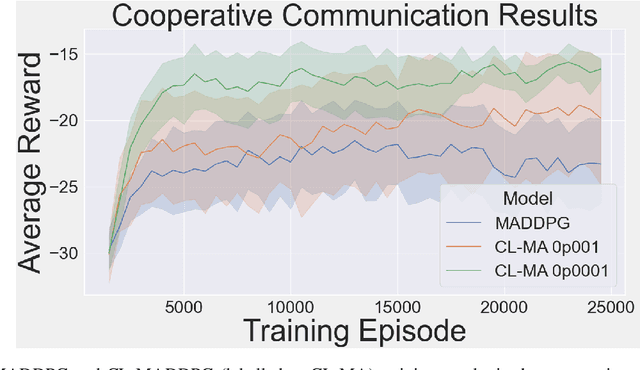
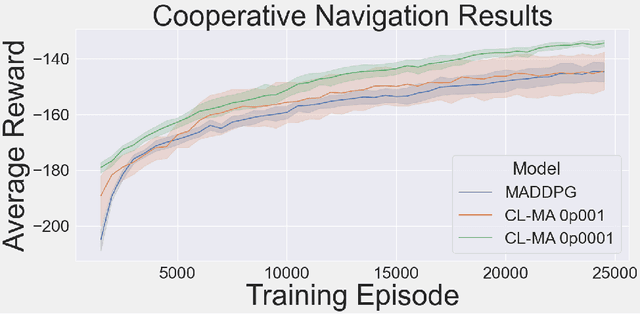
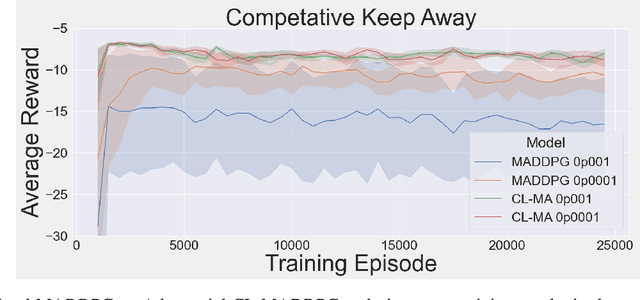
This paper introduces an information-theoretic constraint on learned policy complexity in the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) reinforcement learning algorithm. Previous research with a related approach in continuous control experiments suggests that this method favors learning policies that are more robust to changing environment dynamics. The multi-agent game setting naturally requires this type of robustness, as other agents' policies change throughout learning, introducing a nonstationary environment. For this reason, recent methods in continual learning are compared to our approach, termed Capacity-Limited MADDPG. Results from experimentation in multi-agent cooperative and competitive tasks demonstrate that the capacity-limited approach is a good candidate for improving learning performance in these environments.
Deep RL With Information Constrained Policies: Generalization in Continuous Control
Oct 09, 2020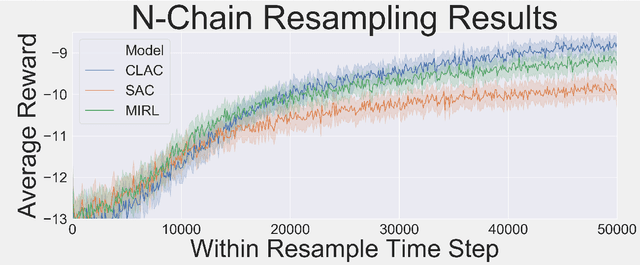
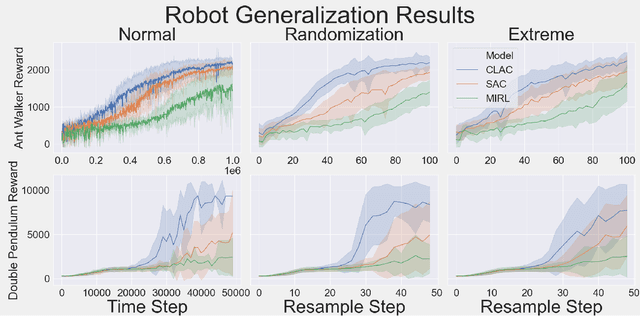
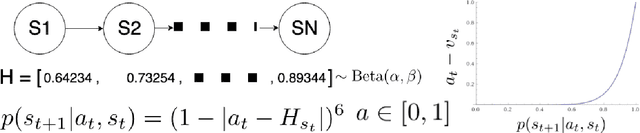
Biological agents learn and act intelligently in spite of a highly limited capacity to process and store information. Many real-world problems involve continuous control, which represents a difficult task for artificial intelligence agents. In this paper we explore the potential learning advantages a natural constraint on information flow might confer onto artificial agents in continuous control tasks. We focus on the model-free reinforcement learning (RL) setting and formalize our approach in terms of an information-theoretic constraint on the complexity of learned policies. We show that our approach emerges in a principled fashion from the application of rate-distortion theory. We implement a novel Capacity-Limited Actor-Critic (CLAC) algorithm and situate it within a broader family of RL algorithms such as the Soft Actor Critic (SAC) and Mutual Information Reinforcement Learning (MIRL) algorithm. Our experiments using continuous control tasks show that compared to alternative approaches, CLAC offers improvements in generalization between training and modified test environments. This is achieved in the CLAC model while displaying the high sample efficiency of similar methods.