 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the generalization capacity of neural networks during generic multimodal reasoning
Jan 26, 2024The advent of the Transformer has led to the development of large language models (LLM), which appear to demonstrate human-like capabilities. To assess the generality of this class of models and a variety of other base neural network architectures to multimodal domains, we evaluated and compared their capacity for multimodal generalization. We introduce a multimodal question-answer benchmark to evaluate three specific types of out-of-distribution (OOD) generalization performance: distractor generalization (generalization in the presence of distractors), systematic compositional generalization (generalization to new task permutations), and productive compositional generalization (generalization to more complex tasks structures). We found that across model architectures (e.g., RNNs, Transformers, Perceivers, etc.), models with multiple attention layers, or models that leveraged cross-attention mechanisms between input domains, fared better. Our positive results demonstrate that for multimodal distractor and systematic generalization, either cross-modal attention or models with deeper attention layers are key architectural features required to integrate multimodal inputs. On the other hand, neither of these architectural features led to productive generalization, suggesting fundamental limitations of existing architectures for specific types of multimodal generalization. These results demonstrate the strengths and limitations of specific architectural components underlying modern neural models for multimodal reasoning. Finally, we provide Generic COG (gCOG), a configurable benchmark with several multimodal generalization splits, for future studies to explore.
Integration of AI and mechanistic modeling in generative adversarial networks for stochastic inverse problems
Sep 17, 2020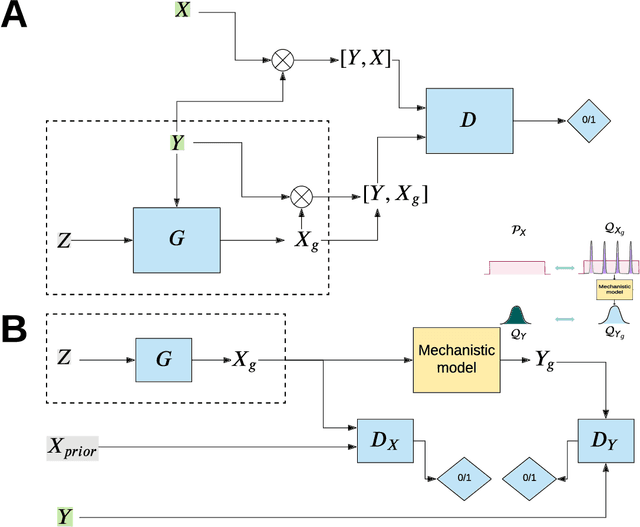
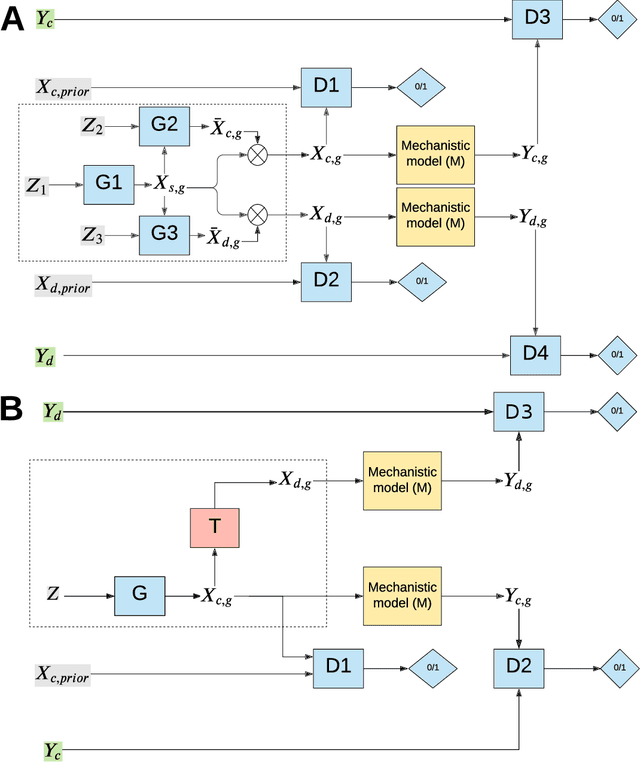
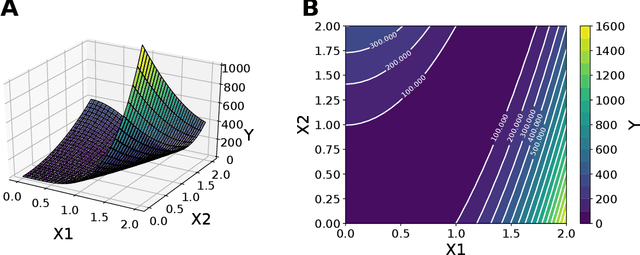
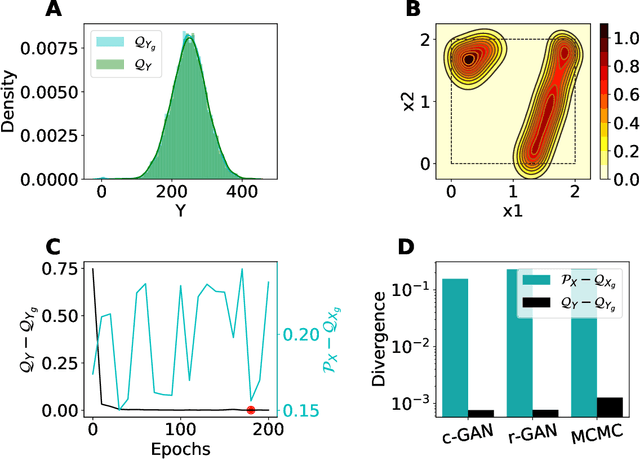
The problem of finding distributions of input parameters for deterministic mechanistic models to match distributions of model outputs to stochastic observations, i.e., the "Stochastic Inverse Problem" (SIP), encompasses a range of common tasks across a variety of scientific disciplines. Here, we demonstrate that SIP could be reformulated as a constrained optimization problem and adapted for applications in intervention studies to simultaneously infer model input parameters for two sets of observations, under control conditions and under an intervention. In the constrained optimization problem, the solution of SIP is enforced to accommodate the prior knowledge on the model input parameters and to produce outputs consistent with given observations by minimizing the divergence between the inferred distribution of input parameters and the prior. Unlike in standard SIP, the prior incorporates not only knowledge about model input parameters for objects in each set, but also information on the joint distribution or the deterministic map between the model input parameters in two sets of observations. To solve standard and intervention SIP, we employed conditional generative adversarial networks (GANs) and designed novel GANs that incorporate multiple generators and discriminators and have structures that reflect the underlying constrained optimization problems. This reformulation allows us to build computationally scalable solutions to tackle complex model input parameter inference scenarios, which appear routinely in physics, biophysics, economics and other areas, and which currently could not be handled with existing methods.