 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniLayDiff: A Unified Diffusion Transformer for Content-Aware Layout Generation
Dec 09, 2025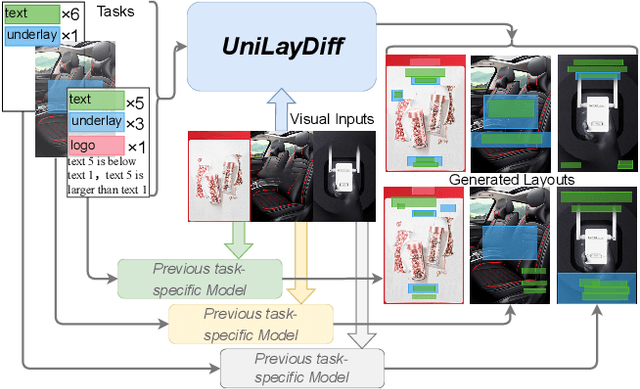
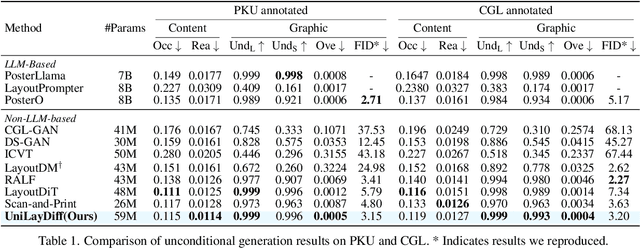
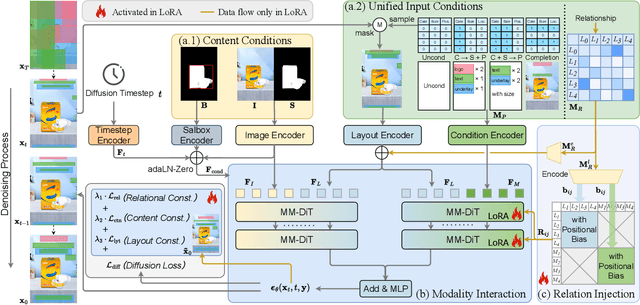
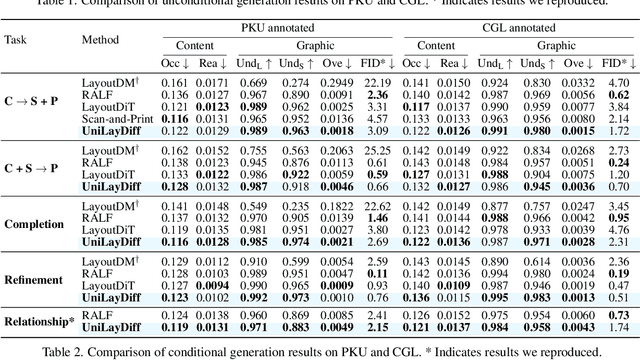
Content-aware layout generation is a critical task in graphic design automation, focused on creating visually appealing arrangements of elements that seamlessly blend with a given background image. The variety of real-world applications makes it highly challenging to develop a single model capable of unifying the diverse range of input-constrained generation sub-tasks, such as those conditioned by element types, sizes, or their relationships. Current methods either address only a subset of these tasks or necessitate separate model parameters for different conditions, failing to offer a truly unified solution. In this paper, we propose UniLayDiff: a Unified Diffusion Transformer, that for the first time, addresses various content-aware layout generation tasks with a single, end-to-end trainable model. Specifically, we treat layout constraints as a distinct modality and employ Multi-Modal Diffusion Transformer framework to capture the complex interplay between the background image, layout elements, and diverse constraints. Moreover, we integrate relation constraints through fine-tuning the model with LoRA after pretraining the model on other tasks. Such a schema not only achieves unified conditional generation but also enhances overall layout quality. Extensive experiments demonstrate that UniLayDiff achieves state-of-the-art performance across from unconditional to various conditional generation tasks and, to the best of our knowledge, is the first model to unify the full range of content-aware layout generation tasks.
What Matters in LLM-generated Data: Diversity and Its Effect on Model Fine-Tuning
Jun 24, 2025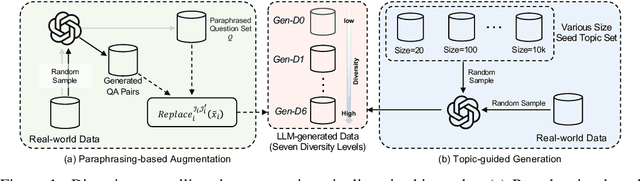
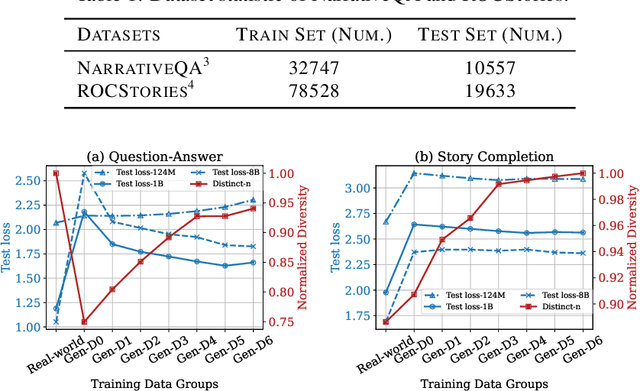
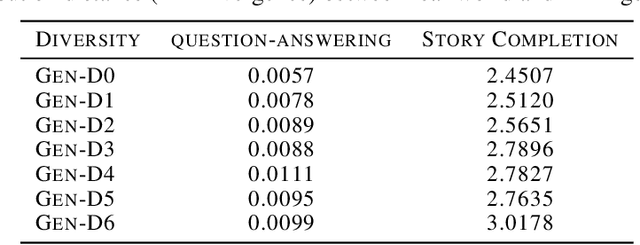
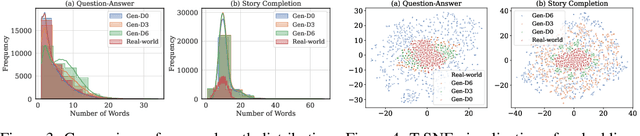
With the remarkable generative capabilities of large language models (LLMs), using LLM-generated data to train downstream models has emerged as a promising approach to mitigate data scarcity in specific domains and reduce time-consuming annotations. However, recent studies have highlighted a critical issue: iterative training on self-generated data results in model collapse, where model performance degrades over time. Despite extensive research on the implications of LLM-generated data, these works often neglect the importance of data diversity, a key factor in data quality. In this work, we aim to understand the implications of the diversity of LLM-generated data on downstream model performance. Specifically, we explore how varying levels of diversity in LLM-generated data affect downstream model performance. Additionally, we investigate the performance of models trained on data that mixes different proportions of LLM-generated data, which we refer to as synthetic data. Our experimental results show that, with minimal distribution shift, moderately diverse LLM-generated data can enhance model performance in scenarios with insufficient labeled data, whereas highly diverse generated data has a negative impact. We hope our empirical findings will offer valuable guidance for future studies on LLMs as data generators.
Moment Quantization for Video Temporal Grounding
Apr 03, 2025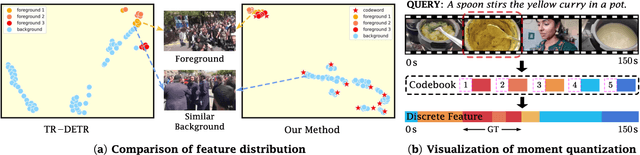
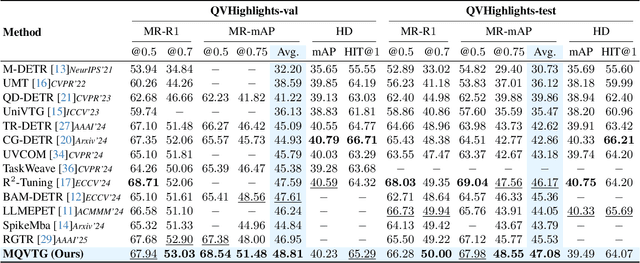
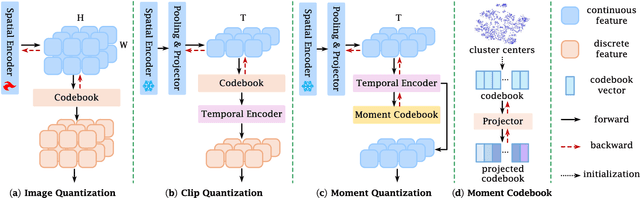
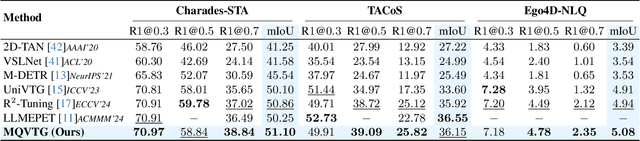
Video temporal grounding is a critical video understanding task, which aims to localize moments relevant to a language description. The challenge of this task lies in distinguishing relevant and irrelevant moments. Previous methods focused on learning continuous features exhibit weak differentiation between foreground and background features. In this paper, we propose a novel Moment-Quantization based Video Temporal Grounding method (MQVTG), which quantizes the input video into various discrete vectors to enhance the discrimination between relevant and irrelevant moments. Specifically, MQVTG maintains a learnable moment codebook, where each video moment matches a codeword. Considering the visual diversity, i.e., various visual expressions for the same moment, MQVTG treats moment-codeword matching as a clustering process without using discrete vectors, avoiding the loss of useful information from direct hard quantization. Additionally, we employ effective prior-initialization and joint-projection strategies to enhance the maintained moment codebook. With its simple implementation, the proposed method can be integrated into existing temporal grounding models as a plug-and-play component. Extensive experiments on six popular benchmarks demonstrate the effectiveness and generalizability of MQVTG, significantly outperforming state-of-the-art methods. Further qualitative analysis shows that our method effectively groups relevant features and separates irrelevant ones, aligning with our goal of enhancing discrimination.
Other Vehicle Trajectories Are Also Needed: A Driving World Model Unifies Ego-Other Vehicle Trajectories in Video Latant Space
Mar 12, 2025Advanced end-to-end autonomous driving systems predict other vehicles' motions and plan ego vehicle's trajectory. The world model that can foresee the outcome of the trajectory has been used to evaluate the end-to-end autonomous driving system. However, existing world models predominantly emphasize the trajectory of the ego vehicle and leave other vehicles uncontrollable. This limitation hinders their ability to realistically simulate the interaction between the ego vehicle and the driving scenario. In addition, it remains a challenge to match multiple trajectories with each vehicle in the video to control the video generation. To address above issues, a driving \textbf{W}orld \textbf{M}odel named EOT-WM is proposed in this paper, unifying \textbf{E}go-\textbf{O}ther vehicle \textbf{T}rajectories in videos. Specifically, we first project ego and other vehicle trajectories in the BEV space into the image coordinate to match each trajectory with its corresponding vehicle in the video. Then, trajectory videos are encoded by the Spatial-Temporal Variational Auto Encoder to align with driving video latents spatially and temporally in the unified visual space. A trajectory-injected diffusion Transformer is further designed to denoise the noisy video latents for video generation with the guidance of ego-other vehicle trajectories. In addition, we propose a metric based on control latent similarity to evaluate the controllability of trajectories. Extensive experiments are conducted on the nuScenes dataset, and the proposed model outperforms the state-of-the-art method by 30\% in FID and 55\% in FVD. The model can also predict unseen driving scenes with self-produced trajectories.
Moving Target Detection Method Based on Range? Doppler Domain Compensation and Cancellation for UAV-Mounted Radar
Jul 04, 2024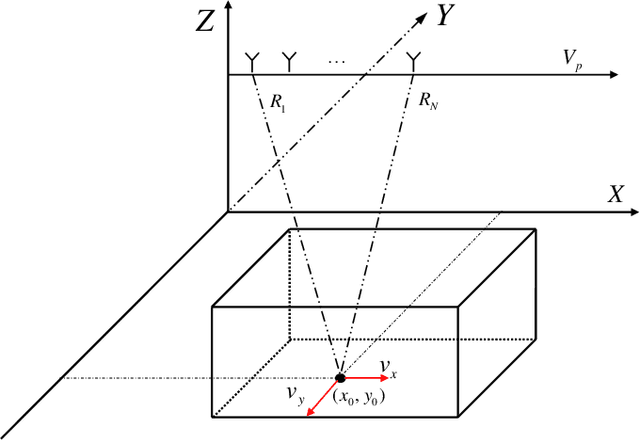
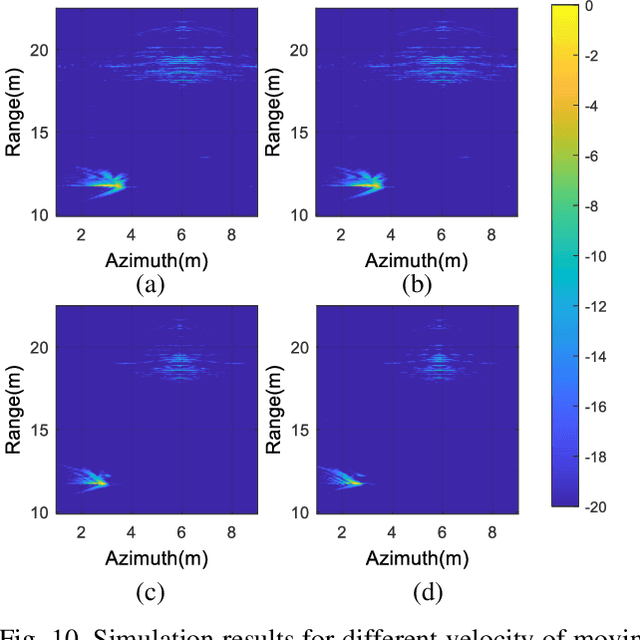
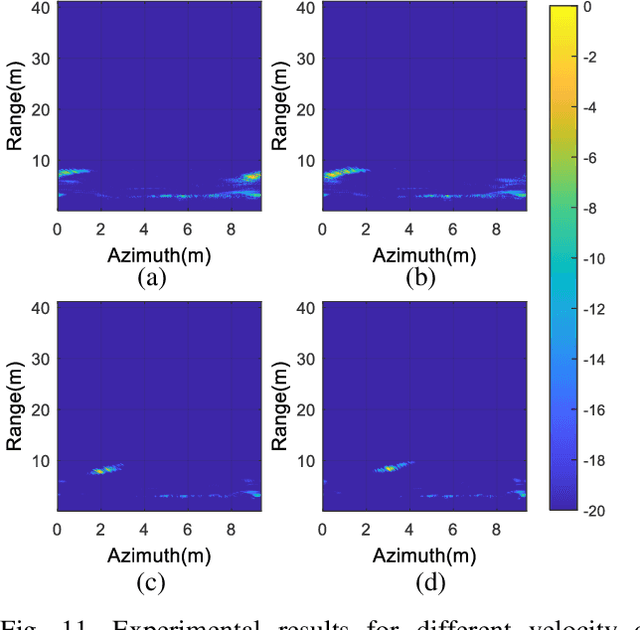

Combining unmanned aerial vehicle (UAV) with through-the-wall radar can realize moving targets detection in complex building scenes. However, clutters generated by obstacles and static objects are always stronger and non-stationary, which results in heavy impacts on moving targets detection. To address this issue, this paper proposes a moving target detection method based on Range-Doppler domain compensation and cancellation for UAV mounted dual channel radar. In the proposed method, phase compensation is performed on the dual channel in range-Doppler domain and then cancellation is utilized to achieve roughly clutters suppression. Next, a filter is constructed based on the cancellation result and the raw echoes, which is used to suppress stationary clutter furthermore. Finally, mismatch imaging is used to focus moving target for detection. Both simulation and UAV-based experiment results are analyzed to verify the efficacy and practicability of the proposed method.
Diversifying Query: Region-Guided Transformer for Temporal Sentence Grounding
May 31, 2024



Temporal sentence grounding is a challenging task that aims to localize the moment spans relevant to a language description. Although recent DETR-based models have achieved notable progress by leveraging multiple learnable moment queries, they suffer from overlapped and redundant proposals, leading to inaccurate predictions. We attribute this limitation to the lack of task-related guidance for the learnable queries to serve a specific mode. Furthermore, the complex solution space generated by variable and open-vocabulary language descriptions exacerbates the optimization difficulty, making it harder for learnable queries to distinguish each other adaptively. To tackle this limitation, we present a Region-Guided TRansformer (RGTR) for temporal sentence grounding, which diversifies moment queries to eliminate overlapped and redundant predictions. Instead of using learnable queries, RGTR adopts a set of anchor pairs as moment queries to introduce explicit regional guidance. Each anchor pair takes charge of moment prediction for a specific temporal region, which reduces the optimization difficulty and ensures the diversity of the final predictions. In addition, we design an IoU-aware scoring head to improve proposal quality. Extensive experiments demonstrate the effectiveness of RGTR, outperforming state-of-the-art methods on QVHighlights, Charades-STA and TACoS datasets.