 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMPO:Scale-wise Autoregression with Motion PrOmpt for generative world models
Sep 19, 2025World models allow agents to simulate the consequences of actions in imagined environments for planning, control, and long-horizon decision-making. However, existing autoregressive world models struggle with visually coherent predictions due to disrupted spatial structure, inefficient decoding, and inadequate motion modeling. In response, we propose \textbf{S}cale-wise \textbf{A}utoregression with \textbf{M}otion \textbf{P}r\textbf{O}mpt (\textbf{SAMPO}), a hybrid framework that combines visual autoregressive modeling for intra-frame generation with causal modeling for next-frame generation. Specifically, SAMPO integrates temporal causal decoding with bidirectional spatial attention, which preserves spatial locality and supports parallel decoding within each scale. This design significantly enhances both temporal consistency and rollout efficiency. To further improve dynamic scene understanding, we devise an asymmetric multi-scale tokenizer that preserves spatial details in observed frames and extracts compact dynamic representations for future frames, optimizing both memory usage and model performance. Additionally, we introduce a trajectory-aware motion prompt module that injects spatiotemporal cues about object and robot trajectories, focusing attention on dynamic regions and improving temporal consistency and physical realism. Extensive experiments show that SAMPO achieves competitive performance in action-conditioned video prediction and model-based control, improving generation quality with 4.4$\times$ faster inference. We also evaluate SAMPO's zero-shot generalization and scaling behavior, demonstrating its ability to generalize to unseen tasks and benefit from larger model sizes.
Moment Quantization for Video Temporal Grounding
Apr 03, 2025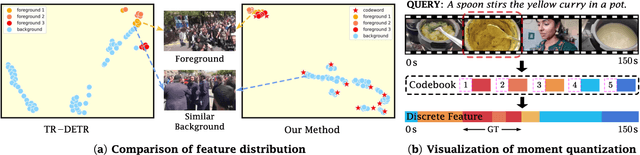
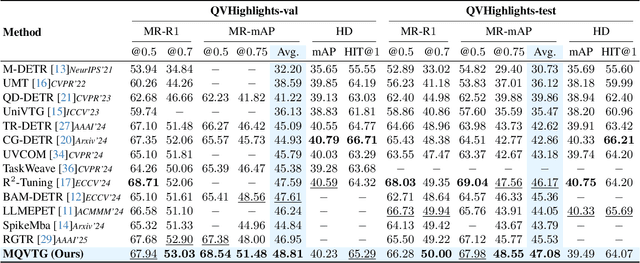
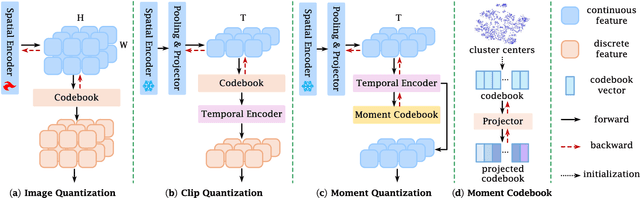
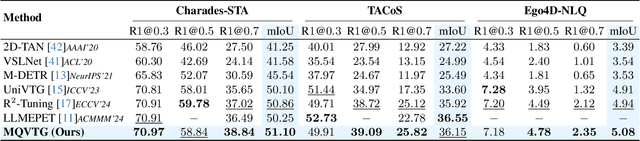
Video temporal grounding is a critical video understanding task, which aims to localize moments relevant to a language description. The challenge of this task lies in distinguishing relevant and irrelevant moments. Previous methods focused on learning continuous features exhibit weak differentiation between foreground and background features. In this paper, we propose a novel Moment-Quantization based Video Temporal Grounding method (MQVTG), which quantizes the input video into various discrete vectors to enhance the discrimination between relevant and irrelevant moments. Specifically, MQVTG maintains a learnable moment codebook, where each video moment matches a codeword. Considering the visual diversity, i.e., various visual expressions for the same moment, MQVTG treats moment-codeword matching as a clustering process without using discrete vectors, avoiding the loss of useful information from direct hard quantization. Additionally, we employ effective prior-initialization and joint-projection strategies to enhance the maintained moment codebook. With its simple implementation, the proposed method can be integrated into existing temporal grounding models as a plug-and-play component. Extensive experiments on six popular benchmarks demonstrate the effectiveness and generalizability of MQVTG, significantly outperforming state-of-the-art methods. Further qualitative analysis shows that our method effectively groups relevant features and separates irrelevant ones, aligning with our goal of enhancing discrimination.
Comprehensive Manuscript Assessment with Text Summarization Using 69707 articles
Mar 26, 2025



Rapid and efficient assessment of the future impact of research articles is a significant concern for both authors and reviewers. The most common standard for measuring the impact of academic papers is the number of citations. In recent years, numerous efforts have been undertaken to predict citation counts within various citation windows. However, most of these studies focus solely on a specific academic field or require early citation counts for prediction, rendering them impractical for the early-stage evaluation of papers. In this work, we harness Scopus to curate a significantly comprehensive and large-scale dataset of information from 69707 scientific articles sourced from 99 journals spanning multiple disciplines. We propose a deep learning methodology for the impact-based classification tasks, which leverages semantic features extracted from the manuscripts and paper metadata. To summarize the semantic features, such as titles and abstracts, we employ a Transformer-based language model to encode semantic features and design a text fusion layer to capture shared information between titles and abstracts. We specifically focus on the following impact-based prediction tasks using information of scientific manuscripts in pre-publication stage: (1) The impact of journals in which the manuscripts will be published. (2) The future impact of manuscripts themselves. Extensive experiments on our datasets demonstrate the superiority of our proposed model for impact-based prediction tasks. We also demonstrate potentials in generating manuscript's feedback and improvement suggestions.
Semi-Supervised Transfer Boosting (SS-TrBoosting)
Dec 04, 2024Semi-supervised domain adaptation (SSDA) aims at training a high-performance model for a target domain using few labeled target data, many unlabeled target data, and plenty of auxiliary data from a source domain. Previous works in SSDA mainly focused on learning transferable representations across domains. However, it is difficult to find a feature space where the source and target domains share the same conditional probability distribution. Additionally, there is no flexible and effective strategy extending existing unsupervised domain adaptation (UDA) approaches to SSDA settings. In order to solve the above two challenges, we propose a novel fine-tuning framework, semi-supervised transfer boosting (SS-TrBoosting). Given a well-trained deep learning-based UDA or SSDA model, we use it as the initial model, generate additional base learners by boosting, and then use all of them as an ensemble. More specifically, half of the base learners are generated by supervised domain adaptation, and half by semi-supervised learning. Furthermore, for more efficient data transmission and better data privacy protection, we propose a source data generation approach to extend SS-TrBoosting to semi-supervised source-free domain adaptation (SS-SFDA). Extensive experiments showed that SS-TrBoosting can be applied to a variety of existing UDA, SSDA and SFDA approaches to further improve their performance.
Diversifying Query: Region-Guided Transformer for Temporal Sentence Grounding
May 31, 2024



Temporal sentence grounding is a challenging task that aims to localize the moment spans relevant to a language description. Although recent DETR-based models have achieved notable progress by leveraging multiple learnable moment queries, they suffer from overlapped and redundant proposals, leading to inaccurate predictions. We attribute this limitation to the lack of task-related guidance for the learnable queries to serve a specific mode. Furthermore, the complex solution space generated by variable and open-vocabulary language descriptions exacerbates the optimization difficulty, making it harder for learnable queries to distinguish each other adaptively. To tackle this limitation, we present a Region-Guided TRansformer (RGTR) for temporal sentence grounding, which diversifies moment queries to eliminate overlapped and redundant predictions. Instead of using learnable queries, RGTR adopts a set of anchor pairs as moment queries to introduce explicit regional guidance. Each anchor pair takes charge of moment prediction for a specific temporal region, which reduces the optimization difficulty and ensures the diversity of the final predictions. In addition, we design an IoU-aware scoring head to improve proposal quality. Extensive experiments demonstrate the effectiveness of RGTR, outperforming state-of-the-art methods on QVHighlights, Charades-STA and TACoS datasets.
Learning Discriminative Spatio-temporal Representations for Semi-supervised Action Recognition
Apr 25, 2024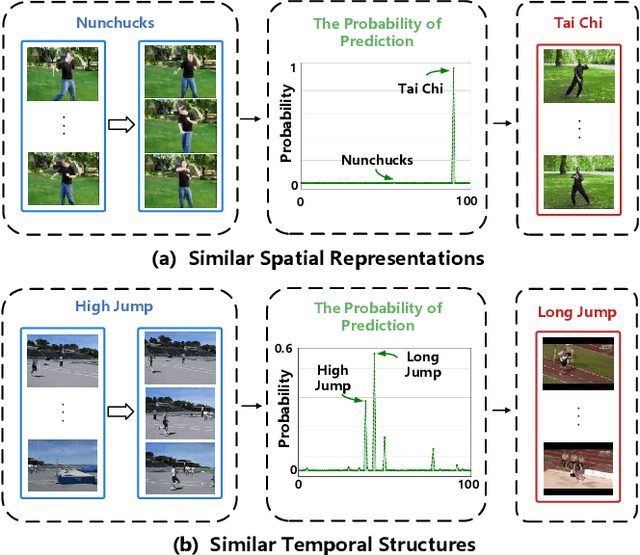
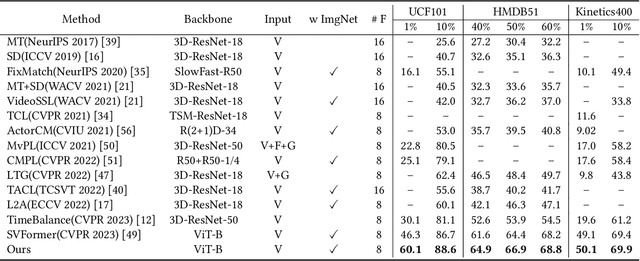
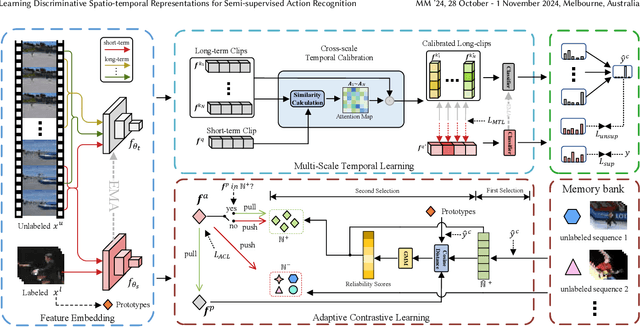
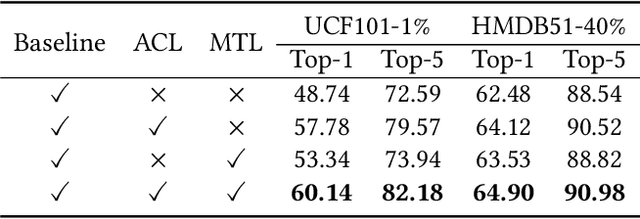
Semi-supervised action recognition aims to improve spatio-temporal reasoning ability with a few labeled data in conjunction with a large amount of unlabeled data. Albeit recent advancements, existing powerful methods are still prone to making ambiguous predictions under scarce labeled data, embodied as the limitation of distinguishing different actions with similar spatio-temporal information. In this paper, we approach this problem by empowering the model two aspects of capability, namely discriminative spatial modeling and temporal structure modeling for learning discriminative spatio-temporal representations. Specifically, we propose an Adaptive Contrastive Learning~(ACL) strategy. It assesses the confidence of all unlabeled samples by the class prototypes of the labeled data, and adaptively selects positive-negative samples from a pseudo-labeled sample bank to construct contrastive learning. Additionally, we introduce a Multi-scale Temporal Learning~(MTL) strategy. It could highlight informative semantics from long-term clips and integrate them into the short-term clip while suppressing noisy information. Afterwards, both of these two new techniques are integrated in a unified framework to encourage the model to make accurate predictions. Extensive experiments on UCF101, HMDB51 and Kinetics400 show the superiority of our method over prior state-of-the-art approaches.
Boosting Semi-Supervised Temporal Action Localization by Learning from Non-Target Classes
Mar 17, 2024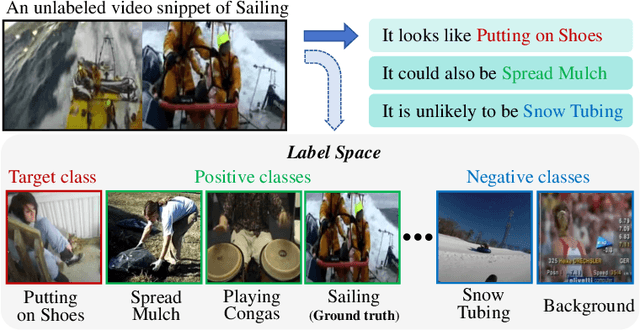
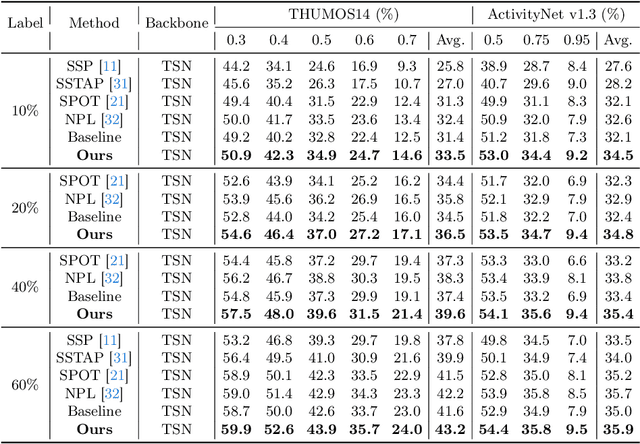
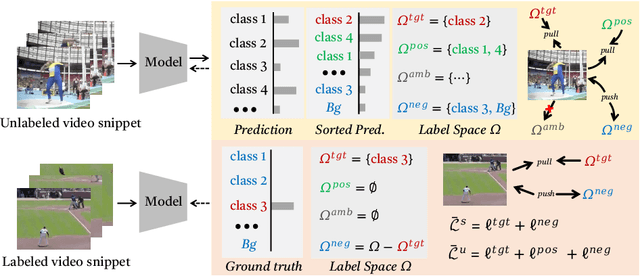

The crux of semi-supervised temporal action localization (SS-TAL) lies in excavating valuable information from abundant unlabeled videos. However, current approaches predominantly focus on building models that are robust to the error-prone target class (i.e, the predicted class with the highest confidence) while ignoring informative semantics within non-target classes. This paper approaches SS-TAL from a novel perspective by advocating for learning from non-target classes, transcending the conventional focus solely on the target class. The proposed approach involves partitioning the label space of the predicted class distribution into distinct subspaces: target class, positive classes, negative classes, and ambiguous classes, aiming to mine both positive and negative semantics that are absent in the target class, while excluding ambiguous classes. To this end, we first devise innovative strategies to adaptively select high-quality positive and negative classes from the label space, by modeling both the confidence and rank of a class in relation to those of the target class. Then, we introduce novel positive and negative losses designed to guide the learning process, pushing predictions closer to positive classes and away from negative classes. Finally, the positive and negative processes are integrated into a hybrid positive-negative learning framework, facilitating the utilization of non-target classes in both labeled and unlabeled videos. Experimental results on THUMOS14 and ActivityNet v1.3 demonstrate the superiority of the proposed method over prior state-of-the-art approaches.
Learning to Refactor Action and Co-occurrence Features for Temporal Action Localization
Jun 23, 2022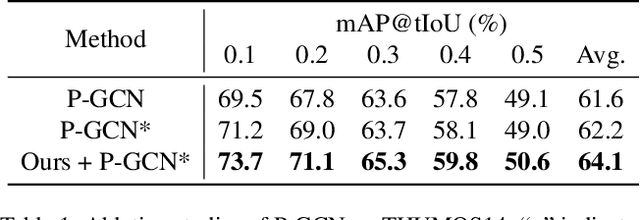
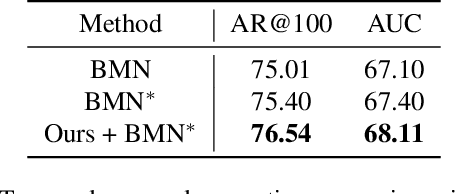
The main challenge of Temporal Action Localization is to retrieve subtle human actions from various co-occurring ingredients, e.g., context and background, in an untrimmed video. While prior approaches have achieved substantial progress through devising advanced action detectors, they still suffer from these co-occurring ingredients which often dominate the actual action content in videos. In this paper, we explore two orthogonal but complementary aspects of a video snippet, i.e., the action features and the co-occurrence features. Especially, we develop a novel auxiliary task by decoupling these two types of features within a video snippet and recombining them to generate a new feature representation with more salient action information for accurate action localization. We term our method RefactorNet, which first explicitly factorizes the action content and regularizes its co-occurrence features, and then synthesizes a new action-dominated video representation. Extensive experimental results and ablation studies on THUMOS14 and ActivityNet v1.3 demonstrate that our new representation, combined with a simple action detector, can significantly improve the action localization performance.