 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoment Quantization for Video Temporal Grounding
Apr 03, 2025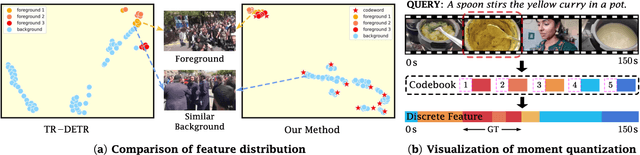
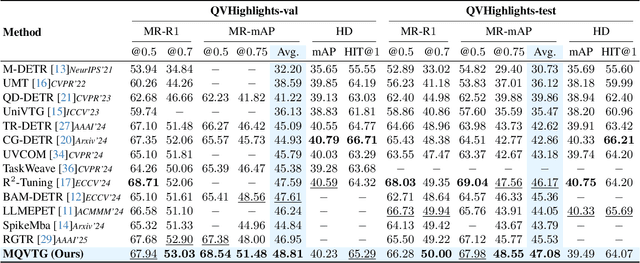
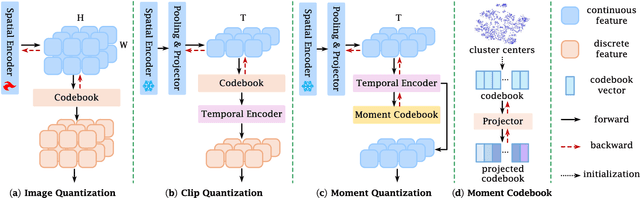
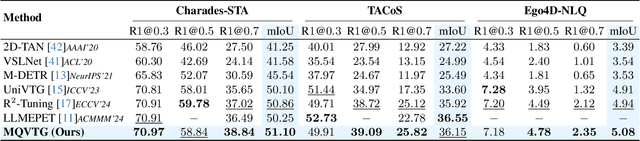
Video temporal grounding is a critical video understanding task, which aims to localize moments relevant to a language description. The challenge of this task lies in distinguishing relevant and irrelevant moments. Previous methods focused on learning continuous features exhibit weak differentiation between foreground and background features. In this paper, we propose a novel Moment-Quantization based Video Temporal Grounding method (MQVTG), which quantizes the input video into various discrete vectors to enhance the discrimination between relevant and irrelevant moments. Specifically, MQVTG maintains a learnable moment codebook, where each video moment matches a codeword. Considering the visual diversity, i.e., various visual expressions for the same moment, MQVTG treats moment-codeword matching as a clustering process without using discrete vectors, avoiding the loss of useful information from direct hard quantization. Additionally, we employ effective prior-initialization and joint-projection strategies to enhance the maintained moment codebook. With its simple implementation, the proposed method can be integrated into existing temporal grounding models as a plug-and-play component. Extensive experiments on six popular benchmarks demonstrate the effectiveness and generalizability of MQVTG, significantly outperforming state-of-the-art methods. Further qualitative analysis shows that our method effectively groups relevant features and separates irrelevant ones, aligning with our goal of enhancing discrimination.