 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Semi-Supervised Temporal Action Localization by Learning from Non-Target Classes
Paper and Code
Mar 17, 2024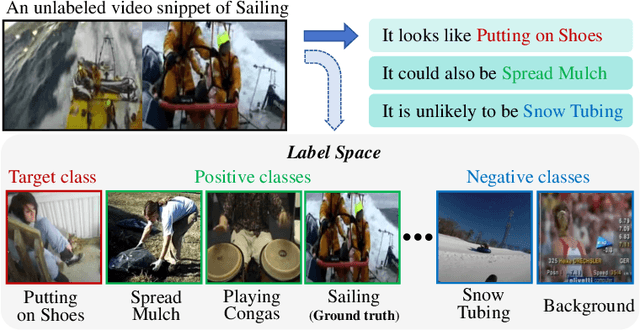
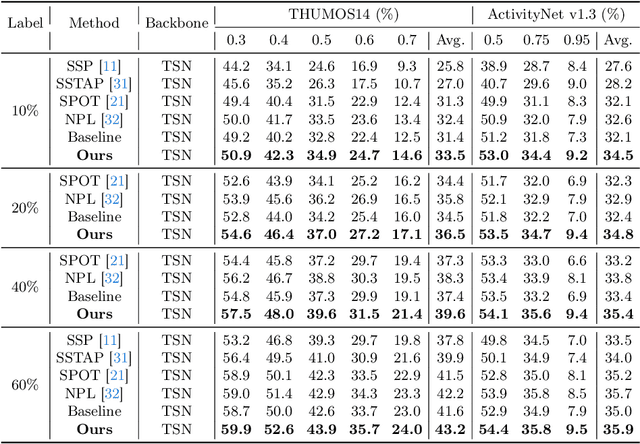
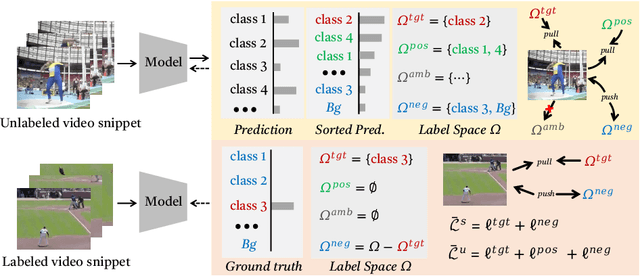

The crux of semi-supervised temporal action localization (SS-TAL) lies in excavating valuable information from abundant unlabeled videos. However, current approaches predominantly focus on building models that are robust to the error-prone target class (i.e, the predicted class with the highest confidence) while ignoring informative semantics within non-target classes. This paper approaches SS-TAL from a novel perspective by advocating for learning from non-target classes, transcending the conventional focus solely on the target class. The proposed approach involves partitioning the label space of the predicted class distribution into distinct subspaces: target class, positive classes, negative classes, and ambiguous classes, aiming to mine both positive and negative semantics that are absent in the target class, while excluding ambiguous classes. To this end, we first devise innovative strategies to adaptively select high-quality positive and negative classes from the label space, by modeling both the confidence and rank of a class in relation to those of the target class. Then, we introduce novel positive and negative losses designed to guide the learning process, pushing predictions closer to positive classes and away from negative classes. Finally, the positive and negative processes are integrated into a hybrid positive-negative learning framework, facilitating the utilization of non-target classes in both labeled and unlabeled videos. Experimental results on THUMOS14 and ActivityNet v1.3 demonstrate the superiority of the proposed method over prior state-of-the-art approaches.