 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Transfer Boosting (SS-TrBoosting)
Dec 04, 2024Semi-supervised domain adaptation (SSDA) aims at training a high-performance model for a target domain using few labeled target data, many unlabeled target data, and plenty of auxiliary data from a source domain. Previous works in SSDA mainly focused on learning transferable representations across domains. However, it is difficult to find a feature space where the source and target domains share the same conditional probability distribution. Additionally, there is no flexible and effective strategy extending existing unsupervised domain adaptation (UDA) approaches to SSDA settings. In order to solve the above two challenges, we propose a novel fine-tuning framework, semi-supervised transfer boosting (SS-TrBoosting). Given a well-trained deep learning-based UDA or SSDA model, we use it as the initial model, generate additional base learners by boosting, and then use all of them as an ensemble. More specifically, half of the base learners are generated by supervised domain adaptation, and half by semi-supervised learning. Furthermore, for more efficient data transmission and better data privacy protection, we propose a source data generation approach to extend SS-TrBoosting to semi-supervised source-free domain adaptation (SS-SFDA). Extensive experiments showed that SS-TrBoosting can be applied to a variety of existing UDA, SSDA and SFDA approaches to further improve their performance.
Overcoming Negative Transfer: A Survey
Sep 02, 2020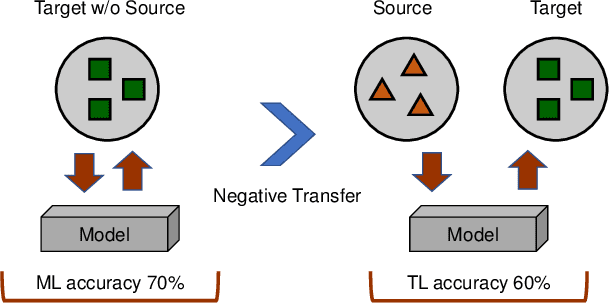
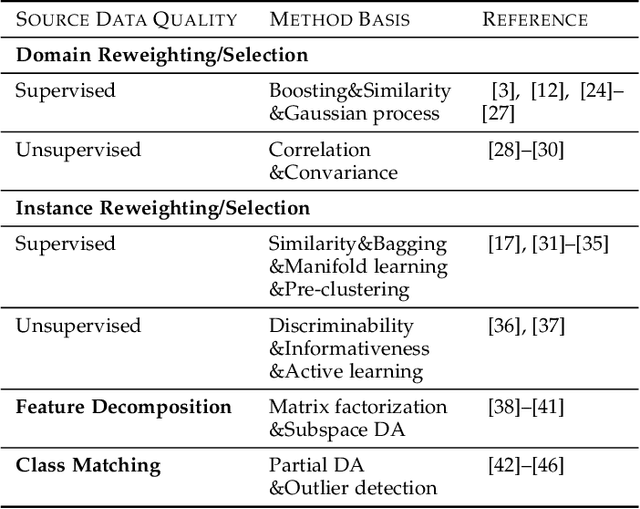


Transfer learning aims to help the target task with little or no training data by leveraging knowledge from one or multi-related auxiliary tasks. In practice, the success of transfer learning is not always guaranteed, negative transfer is a long-standing problem in transfer learning literature, which has been well recognized within the transfer learning community. How to overcome negative transfer has been studied for a long time and has raised increasing attention in recent years. Thus, it is both necessary and challenging to comprehensively review the relevant researches. This survey attempts to analyze the factors related to negative transfer and summarizes the theories and advances of overcoming negative transfer from four crucial aspects: source data quality, target data quality, domain divergence and generic algorithms, which may provide the readers an insight into the current research status and ideas. Additionally, we provided some general guidelines on how to detect and overcome negative transfer on real data, including the negative transfer detection, datasets, baselines, and general routines. The survey provides researchers a framework for better understanding and identifying the research status, fundamental questions, open challenges and future directions of the field.