 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCF-DS: Deep Cascade Fusion of Diarization and Separation for Speech Recognition under Realistic Single-Channel Conditions
Nov 11, 2024



We propose a single-channel Deep Cascade Fusion of Diarization and Separation (DCF-DS) framework for back-end speech recognition, combining neural speaker diarization (NSD) and speech separation (SS). First, we sequentially integrate the NSD and SS modules within a joint training framework, enabling the separation module to leverage speaker time boundaries from the diarization module effectively. Then, to complement DCF-DS training, we introduce a window-level decoding scheme that allows the DCF-DS framework to handle the sparse data convergence instability (SDCI) problem. We also explore using an NSD system trained on real datasets to provide more accurate speaker boundaries during decoding. Additionally, we incorporate an optional multi-input multi-output speech enhancement module (MIMO-SE) within the DCF-DS framework, which offers further performance gains. Finally, we enhance diarization results by re-clustering DCF-DS outputs, improving ASR accuracy. By incorporating the DCF-DS method, we achieved first place in the realistic single-channel track of the CHiME-8 NOTSOFAR-1 challenge. We also perform the evaluation on the open LibriCSS dataset, achieving a new state-of-the-art performance on single-channel speech recognition.
Separation Guided Speaker Diarization in Realistic Mismatched Conditions
Jul 06, 2021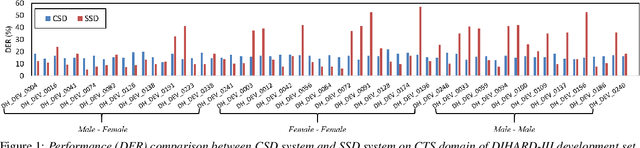
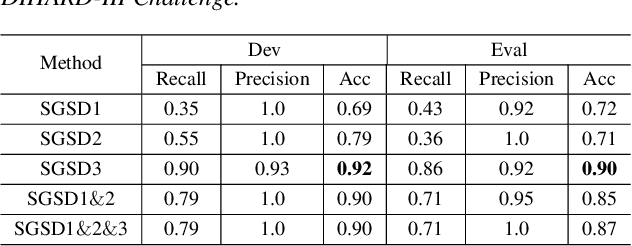
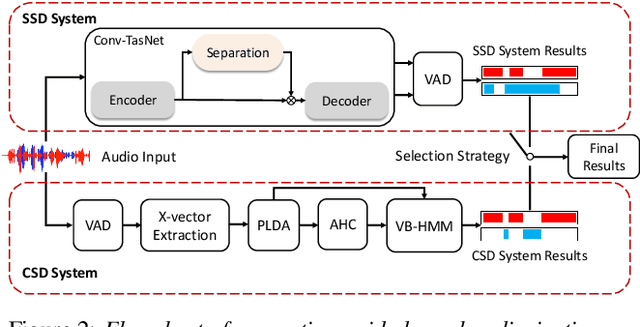
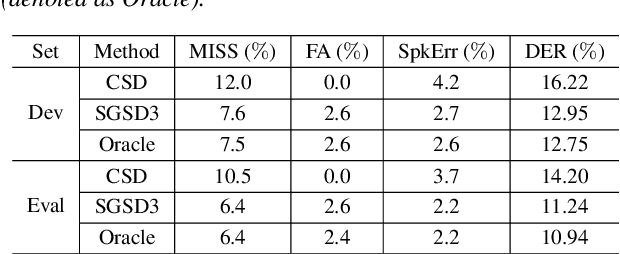
We propose a separation guided speaker diarization (SGSD) approach by fully utilizing a complementarity of speech separation and speaker clustering. Since the conventional clustering-based speaker diarization (CSD) approach cannot well handle overlapping speech segments, we investigate, in this study, separation-based speaker diarization (SSD) which inherently has the potential to handle the speaker overlap regions. Our preliminary analysis shows that the state-of-the-art Conv-TasNet based speech separation, which works quite well on the simulation data, is unstable in realistic conversational speech due to the high mismatch speaking styles in simulated training speech and read speech. In doing so, separation-based processing can assist CSD in handling the overlapping speech segments under the realistic mismatched conditions. Specifically, several strategies are designed to select between the results of SSD and CSD systems based on an analysis of the instability of the SSD system performances. Experiments on the conversational telephone speech (CTS) data from DIHARD-III Challenge show that the proposed SGSD system can significantly improve the performance of state-of-the-art CSD systems, yielding relative diarization error rate reductions of 20.2% and 20.8% on the development set and evaluation set, respectively.