 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Spatial Cues in Modular Speaker Diarization for Multi-channel Multi-party Meetings
Paper and Code
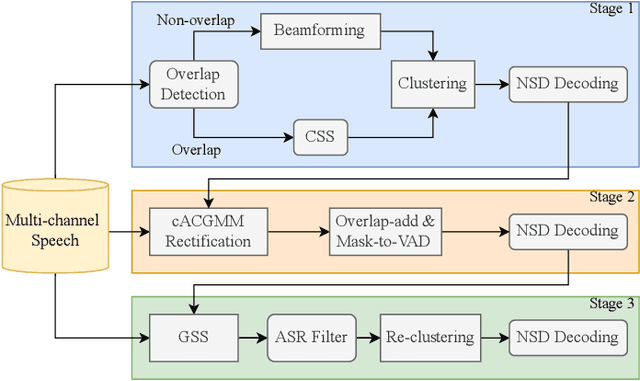
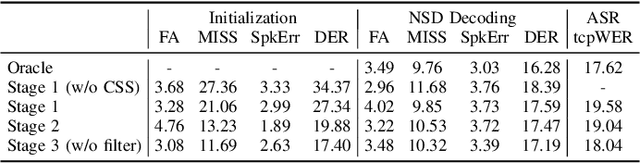


Although fully end-to-end speaker diarization systems have made significant progress in recent years, modular systems often achieve superior results in real-world scenarios due to their greater adaptability and robustness. Historically, modular speaker diarization methods have seldom discussed how to leverage spatial cues from multi-channel speech. This paper proposes a three-stage modular system to enhance single-channel neural speaker diarization systems and recognition performance by utilizing spatial cues from multi-channel speech to provide more accurate initialization for each stage of neural speaker diarization (NSD) decoding: (1) Overlap detection and continuous speech separation (CSS) on multi-channel speech are used to obtain cleaner single speaker speech segments for clustering, followed by the first NSD decoding pass. (2) The results from the first pass initialize a complex Angular Central Gaussian Mixture Model (cACGMM) to estimate speaker-wise masks on multi-channel speech, and through Overlap-add and Mask-to-VAD, achieve initialization with lower speaker error (SpkErr), followed by the second NSD decoding pass. (3) The second decoding results are used for guided source separation (GSS), recognizing and filtering short segments containing less one word to obtain cleaner speech segments, followed by re-clustering and the final NSD decoding pass. We presented the progressively explored evaluation results from the CHiME-8 NOTSOFAR-1 (Natural Office Talkers in Settings Of Far-field Audio Recordings) challenge, demonstrating the effectiveness of our system and its contribution to improving recognition performance. Our final system achieved the first place in the challenge.