 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee then Tell: Enhancing Key Information Extraction with Vision Grounding
Paper and Code
Sep 29, 2024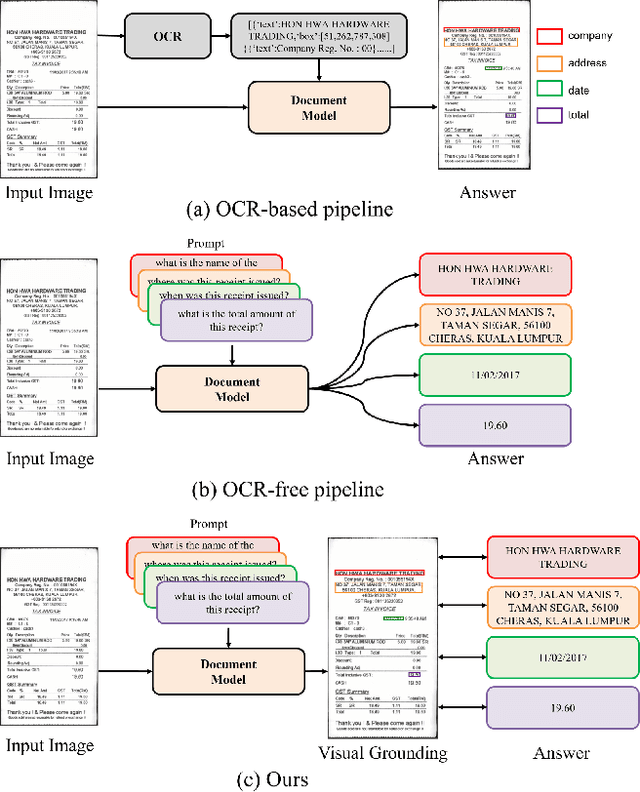
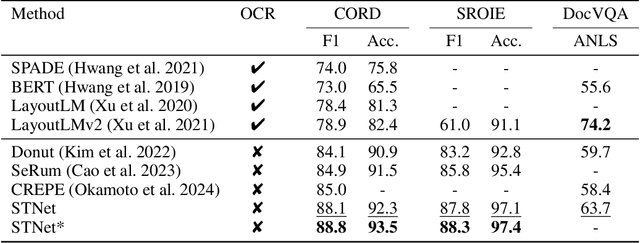
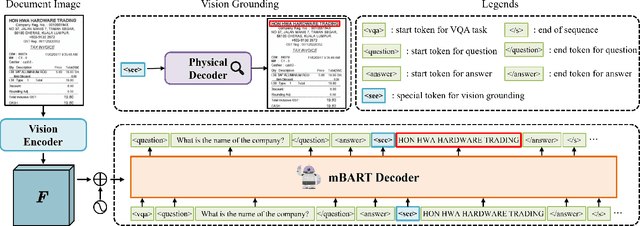

In the digital era, the ability to understand visually rich documents that integrate text, complex layouts, and imagery is critical. Traditional Key Information Extraction (KIE) methods primarily rely on Optical Character Recognition (OCR), which often introduces significant latency, computational overhead, and errors. Current advanced image-to-text approaches, which bypass OCR, typically yield plain text outputs without corresponding vision grounding. In this paper, we introduce STNet (See then Tell Net), a novel end-to-end model designed to deliver precise answers with relevant vision grounding. Distinctively, STNet utilizes a unique <see> token to observe pertinent image areas, aided by a decoder that interprets physical coordinates linked to this token. Positioned at the outset of the answer text, the <see> token allows the model to first see--observing the regions of the image related to the input question--and then tell--providing articulated textual responses. To enhance the model's seeing capabilities, we collect extensive structured table recognition datasets. Leveraging the advanced text processing prowess of GPT-4, we develop the TVG (TableQA with Vision Grounding) dataset, which not only provides text-based Question Answering (QA) pairs but also incorporates precise vision grounding for these pairs. Our approach demonstrates substantial advancements in KIE performance, achieving state-of-the-art results on publicly available datasets such as CORD, SROIE, and DocVQA. The code will also be made publicly available.