 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee then Tell: Enhancing Key Information Extraction with Vision Grounding
Sep 29, 2024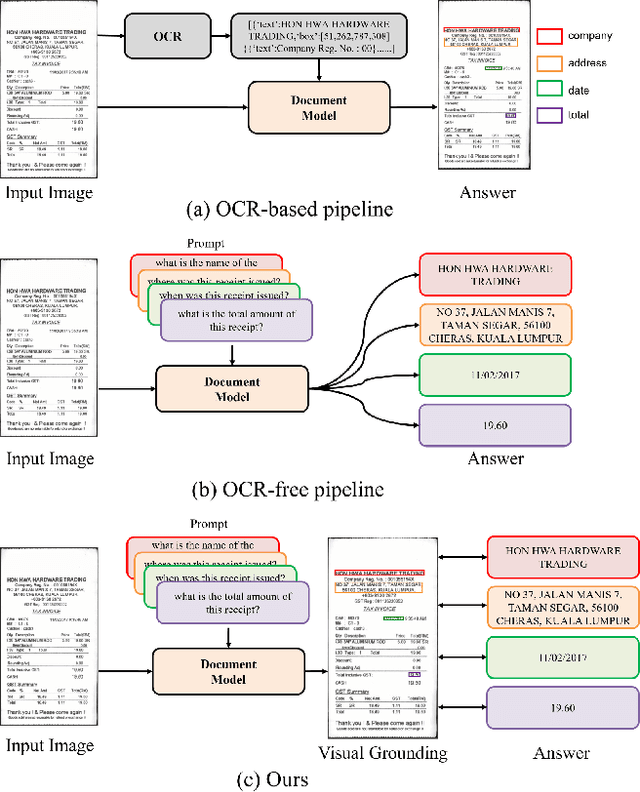
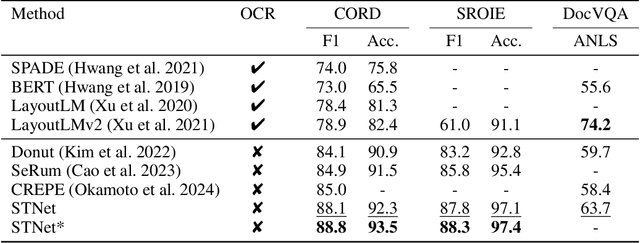
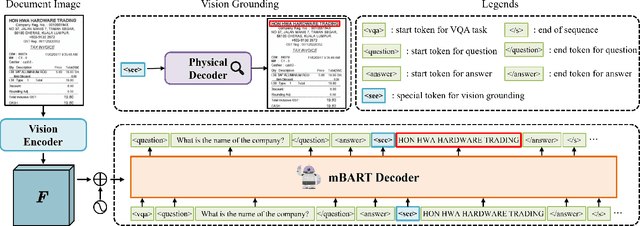

In the digital era, the ability to understand visually rich documents that integrate text, complex layouts, and imagery is critical. Traditional Key Information Extraction (KIE) methods primarily rely on Optical Character Recognition (OCR), which often introduces significant latency, computational overhead, and errors. Current advanced image-to-text approaches, which bypass OCR, typically yield plain text outputs without corresponding vision grounding. In this paper, we introduce STNet (See then Tell Net), a novel end-to-end model designed to deliver precise answers with relevant vision grounding. Distinctively, STNet utilizes a unique <see> token to observe pertinent image areas, aided by a decoder that interprets physical coordinates linked to this token. Positioned at the outset of the answer text, the <see> token allows the model to first see--observing the regions of the image related to the input question--and then tell--providing articulated textual responses. To enhance the model's seeing capabilities, we collect extensive structured table recognition datasets. Leveraging the advanced text processing prowess of GPT-4, we develop the TVG (TableQA with Vision Grounding) dataset, which not only provides text-based Question Answering (QA) pairs but also incorporates precise vision grounding for these pairs. Our approach demonstrates substantial advancements in KIE performance, achieving state-of-the-art results on publicly available datasets such as CORD, SROIE, and DocVQA. The code will also be made publicly available.
DocMamba: Efficient Document Pre-training with State Space Model
Sep 18, 2024



In recent years, visually-rich document understanding has attracted increasing attention. Transformer-based pre-trained models have become the mainstream approach, yielding significant performance gains in this field. However, the self-attention mechanism's quadratic computational complexity hinders their efficiency and ability to process long documents. In this paper, we present DocMamba, a novel framework based on the state space model. It is designed to reduce computational complexity to linear while preserving global modeling capabilities. To further enhance its effectiveness in document processing, we introduce the Segment-First Bidirectional Scan (SFBS) to capture contiguous semantic information. Experimental results demonstrate that DocMamba achieves new state-of-the-art results on downstream datasets such as FUNSD, CORD, and SORIE, while significantly improving speed and reducing memory usage. Notably, experiments on the HRDoc confirm DocMamba's potential for length extrapolation. The code will be available online.
Momentum Decoding: Open-ended Text Generation As Graph Exploration
Dec 05, 2022



Open-ended text generation with autoregressive language models (LMs) is one of the core tasks in natural language processing. However, maximization-based decoding methods (e.g., greedy/beam search) often lead to the degeneration problem, i.e., the generated text is unnatural and contains undesirable repetitions. Existing solutions to this problem either introduce randomness prone to incoherence or require a look-ahead mechanism that demands extra computational overhead. In this study, we formulate open-ended text generation from a new perspective, i.e., we view it as an exploration process within a directed graph. Thereby, we understand the phenomenon of degeneration as circular loops within the directed graph. Based on our formulation, we propose a novel decoding method -- \textit{momentum decoding} -- which encourages the LM to \textit{greedily} explore new nodes outside the current graph. Meanwhile, it also allows the LM to return to the existing nodes with a momentum downgraded by a pre-defined resistance function. We extensively test our approach on three benchmarks from different domains through automatic and human evaluations. The results show that momentum decoding performs comparably with the current state of the art while enjoying notably improved inference speed and computation FLOPs. Furthermore, we conduct a detailed analysis to reveal the merits and inner workings of our approach. Our codes and other related resources are publicly available at https://github.com/gmftbyGMFTBY/MomentumDecoding.