 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonnegative Spectral Analysis with Adaptive Graph and $L_{2,0}$-Norm Regularization for Unsupervised Feature Selection
Paper and Code
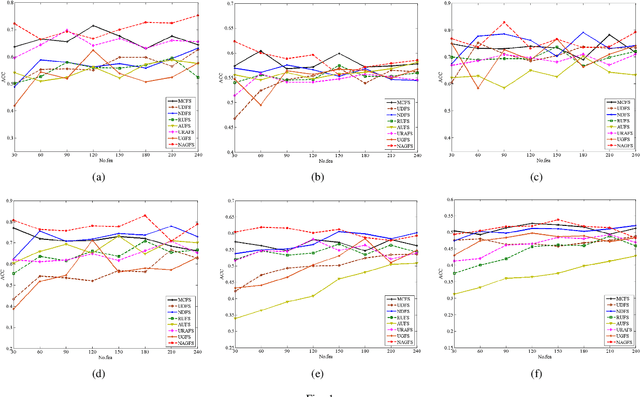
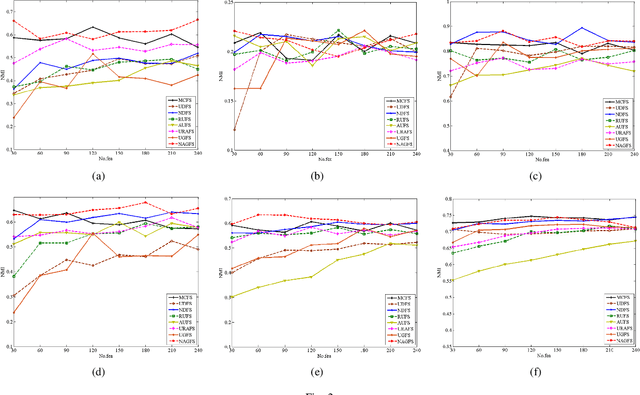
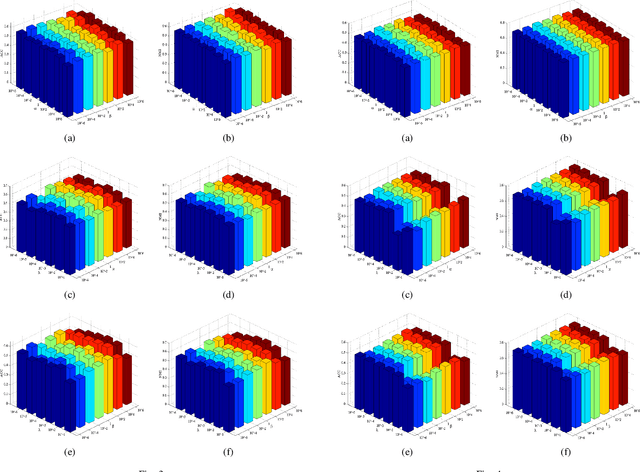

Feature selection is used to reduce feature dimension while maintain model's performance, which has been an important data preprocessing in many fields. Since obtaining annotated data is laborious or even infeasible in many cases, unsupervised feature selection is more practical in reality. Although a lots of methods have been proposed, these methods select features independently, thus it is no guarantee that the group of selected features is optimal. What's more, the number of selected features must be tuned carefully to get a satisfactory result. In this paper, we propose a novel unsupervised feature selection method which incorporate spectral analysis with a $l_{2,0}$-norm regularized term. After optimization, a group of optimal features will be selected, and the number of selected features will be determined automatically. What's more, a nonnegative constraint with respect to the class indicators is imposed to learn more accurate cluster labels, and a graph regularized term is added to learn the similarity matrix adaptively. An efficient and simple iterative algorithm is designed to optimize the proposed problem. Experiments on six different benchmark data sets validate the effectiveness of the proposed approach.