 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mixture of Experts Vision Transformer for High-Fidelity Surface Code Decoding
Jan 18, 2026Quantum error correction is a key ingredient for large scale quantum computation, protecting logical information from physical noise by encoding it into many physical qubits. Topological stabilizer codes are particularly appealing due to their geometric locality and practical relevance. In these codes, stabilizer measurements yield a syndrome that must be decoded into a recovery operation, making decoding a central bottleneck for scalable real time operation. Existing decoders are commonly classified into two categories. Classical algorithmic decoders provide strong and well established baselines, but may incur substantial computational overhead at large code distances or under stringent latency constraints. Machine learning based decoders offer fast GPU inference and flexible function approximation, yet many approaches do not explicitly exploit the lattice geometry and local structure of topological codes, which can limit performance. In this work, we propose QuantumSMoE, a quantum vision transformer based decoder that incorporates code structure through plus shaped embeddings and adaptive masking to capture local interactions and lattice connectivity, and improves scalability via a mixture of experts layer with a novel auxiliary loss. Experiments on the toric code demonstrate that QuantumSMoE outperforms state-of-the-art machine learning decoders as well as widely used classical baselines.
Divergent-Convergent Thinking in Large Language Models for Creative Problem Generation
Dec 29, 2025Large language models (LLMs) have significant potential for generating educational questions and problems, enabling educators to create large-scale learning materials. However, LLMs are fundamentally limited by the ``Artificial Hivemind'' effect, where they generate similar responses within the same model and produce homogeneous outputs across different models. As a consequence, students may be exposed to overly similar and repetitive LLM-generated problems, which harms diversity of thought. Drawing inspiration from Wallas's theory of creativity and Guilford's framework of divergent-convergent thinking, we propose CreativeDC, a two-phase prompting method that explicitly scaffolds the LLM's reasoning into distinct phases. By decoupling creative exploration from constraint satisfaction, our method enables LLMs to explore a broader space of ideas before committing to a final problem. We evaluate CreativeDC for creative problem generation using a comprehensive set of metrics that capture diversity, novelty, and utility. The results show that CreativeDC achieves significantly higher diversity and novelty compared to baselines while maintaining high utility. Moreover, scaling analysis shows that CreativeDC generates a larger effective number of distinct problems as more are sampled, increasing at a faster rate than baseline methods.
Prompt Optimization Across Multiple Agents for Representing Diverse Human Populations
Oct 08, 2025The difficulty and expense of obtaining large-scale human responses make Large Language Models (LLMs) an attractive alternative and a promising proxy for human behavior. However, prior work shows that LLMs often produce homogeneous outputs that fail to capture the rich diversity of human perspectives and behaviors. Thus, rather than trying to capture this diversity with a single LLM agent, we propose a novel framework to construct a set of agents that collectively capture the diversity of a given human population. Each agent is an LLM whose behavior is steered by conditioning on a small set of human demonstrations (task-response pairs) through in-context learning. The central challenge is therefore to select a representative set of LLM agents from the exponentially large space of possible agents. We tackle this selection problem from the lens of submodular optimization. In particular, we develop methods that offer different trade-offs regarding time complexity and performance guarantees. Extensive experiments in crowdsourcing and educational domains demonstrate that our approach constructs agents that more effectively represent human populations compared to baselines. Moreover, behavioral analyses on new tasks show that these agents reproduce the behavior patterns and perspectives of the students and annotators they are designed to represent.
Synthesizing High-Quality Programming Tasks with LLM-based Expert and Student Agents
Apr 10, 2025



Generative AI is transforming computing education by enabling the automatic generation of personalized content and feedback. We investigate its capabilities in providing high-quality programming tasks to students. Despite promising advancements in task generation, a quality gap remains between AI-generated and expert-created tasks. The AI-generated tasks may not align with target programming concepts, could be incomprehensible for students to solve, or may contain critical issues such as incorrect tests. Existing works often require interventions from human teachers for validation. We address these challenges by introducing PyTaskSyn, a novel synthesis technique that first generates a programming task and then decides whether it meets certain quality criteria to be given to students. The key idea is to break this process into multiple stages performed by expert and student agents simulated using both strong and weaker generative models. Through extensive evaluation, we show that PyTaskSyn significantly improves task quality compared to baseline techniques and showcases the importance of each specialized agent type in our validation pipeline. Additionally, we conducted user studies using our publicly available web application and show that PyTaskSyn can deliver high-quality programming tasks comparable to expert-designed ones while reducing workload and costs, and being more engaging than programming tasks that are available in online resources.
Meta-Learning from Learning Curves for Budget-Limited Algorithm Selection
Oct 10, 2024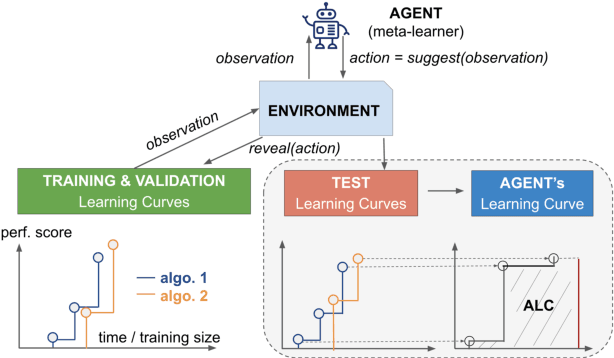
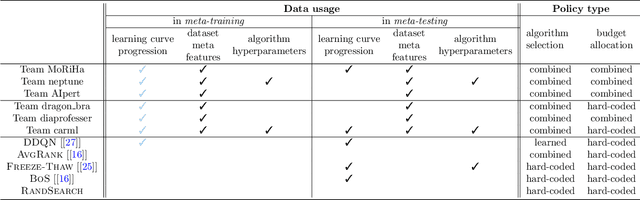
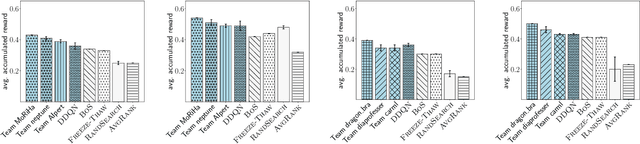
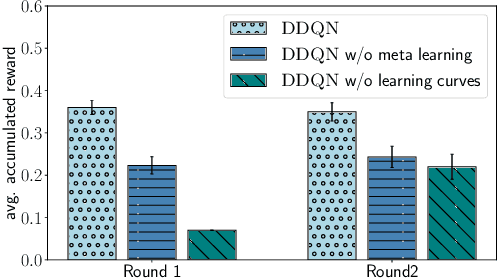
Training a large set of machine learning algorithms to convergence in order to select the best-performing algorithm for a dataset is computationally wasteful. Moreover, in a budget-limited scenario, it is crucial to carefully select an algorithm candidate and allocate a budget for training it, ensuring that the limited budget is optimally distributed to favor the most promising candidates. Casting this problem as a Markov Decision Process, we propose a novel framework in which an agent must select in the process of learning the most promising algorithm without waiting until it is fully trained. At each time step, given an observation of partial learning curves of algorithms, the agent must decide whether to allocate resources to further train the most promising algorithm (exploitation), to wake up another algorithm previously put to sleep, or to start training a new algorithm (exploration). In addition, our framework allows the agent to meta-learn from learning curves on past datasets along with dataset meta-features and algorithm hyperparameters. By incorporating meta-learning, we aim to avoid myopic decisions based solely on premature learning curves on the dataset at hand. We introduce two benchmarks of learning curves that served in international competitions at WCCI'22 and AutoML-conf'22, of which we analyze the results. Our findings show that both meta-learning and the progression of learning curves enhance the algorithm selection process, as evidenced by methods of winning teams and our DDQN baseline, compared to heuristic baselines or a random search. Interestingly, our cost-effective baseline, which selects the best-performing algorithm w.r.t. a small budget, can perform decently when learning curves do not intersect frequently.
Large Language Models for In-Context Student Modeling: Synthesizing Student's Behavior in Visual Programming from One-Shot Observation
Oct 15, 2023Student modeling is central to many educational technologies as it enables the prediction of future learning outcomes and targeted instructional strategies. However, open-ended learning environments pose challenges for accurately modeling students due to the diverse behaviors exhibited by students and the absence of a well-defined set of learning skills. To approach these challenges, we explore the application of Large Language Models (LLMs) for in-context student modeling in open-ended learning environments. We introduce a novel framework, LLM-SS, that leverages LLMs for synthesizing student's behavior. More concretely, given a particular student's solving attempt on a reference task as observation, the goal is to synthesize the student's attempt on a target task. Our framework can be combined with different LLMs; moreover, we fine-tune LLMs using domain-specific expertise to boost their understanding of domain background and student behaviors. We evaluate several concrete methods based on LLM-SS using the StudentSyn benchmark, an existing student's attempt synthesis benchmark in visual programming. Experimental results show a significant improvement compared to baseline methods included in the StudentSyn benchmark. Furthermore, our method using the fine-tuned Llama2-70B model improves noticeably compared to using the base model and becomes on par with using the state-of-the-art GPT-4 model.
Meta-learning from Learning Curves Challenge: Lessons learned from the First Round and Design of the Second Round
Aug 04, 2022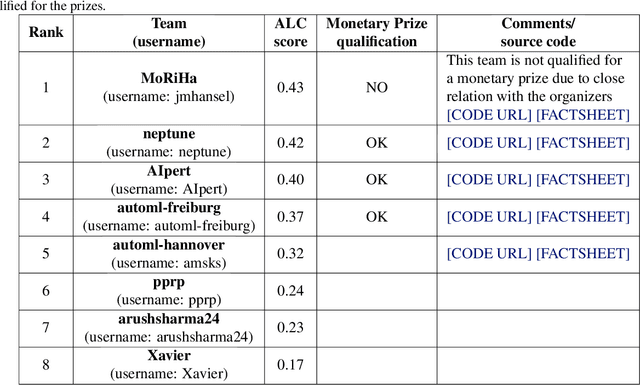
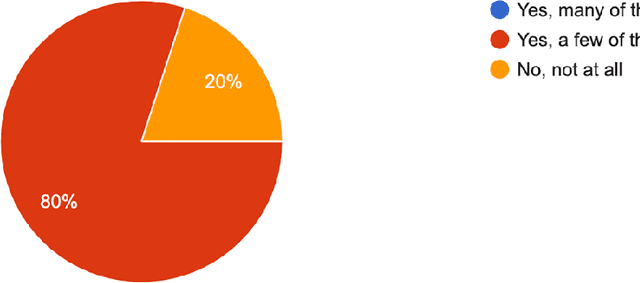
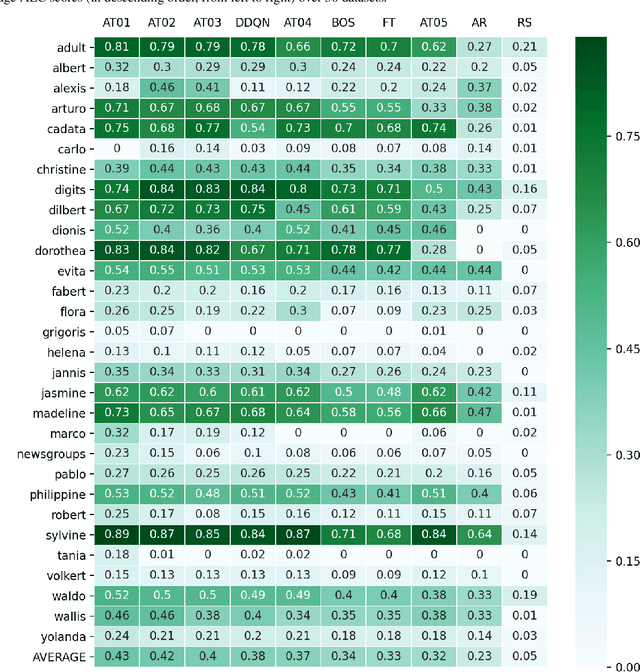
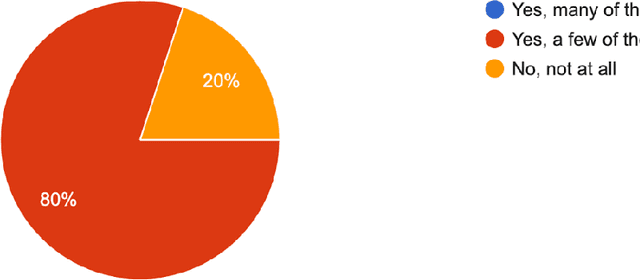
Meta-learning from learning curves is an important yet often neglected research area in the Machine Learning community. We introduce a series of Reinforcement Learning-based meta-learning challenges, in which an agent searches for the best suited algorithm for a given dataset, based on feedback of learning curves from the environment. The first round attracted participants both from academia and industry. This paper analyzes the results of the first round (accepted to the competition program of WCCI 2022), to draw insights into what makes a meta-learner successful at learning from learning curves. With the lessons learned from the first round and the feedback from the participants, we have designed the second round of our challenge with a new protocol and a new meta-dataset. The second round of our challenge is accepted at the AutoML-Conf 2022 and currently ongoing .