 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylized Meta-Album: Group-bias injection with style transfer to study robustness against distribution shifts
Dec 10, 2025We introduce Stylized Meta-Album (SMA), a new image classification meta-dataset comprising 24 datasets (12 content datasets, and 12 stylized datasets), designed to advance studies on out-of-distribution (OOD) generalization and related topics. Created using style transfer techniques from 12 subject classification datasets, SMA provides a diverse and extensive set of 4800 groups, combining various subjects (objects, plants, animals, human actions, textures) with multiple styles. SMA enables flexible control over groups and classes, allowing us to configure datasets to reflect diverse benchmark scenarios. While ideally, data collection would capture extensive group diversity, practical constraints often make this infeasible. SMA addresses this by enabling large and configurable group structures through flexible control over styles, subject classes, and domains-allowing datasets to reflect a wide range of real-world benchmark scenarios. This design not only expands group and class diversity, but also opens new methodological directions for evaluating model performance across diverse group and domain configurations-including scenarios with many minority groups, varying group imbalance, and complex domain shifts-and for studying fairness, robustness, and adaptation under a broader range of realistic conditions. To demonstrate SMA's effectiveness, we implemented two benchmarks: (1) a novel OOD generalization and group fairness benchmark leveraging SMA's domain, class, and group diversity to evaluate existing benchmarks. Our findings reveal that while simple balancing and algorithms utilizing group information remain competitive as claimed in previous benchmarks, increasing group diversity significantly impacts fairness, altering the superiority and relative rankings of algorithms. We also propose to use \textit{Top-M worst group accuracy} as a new hyperparameter tuning metric, demonstrating broader fairness during optimization and delivering better final worst-group accuracy for larger group diversity. (2) An unsupervised domain adaptation (UDA) benchmark utilizing SMA's group diversity to evaluate UDA algorithms across more scenarios, offering a more comprehensive benchmark with lower error bars (reduced by 73\% and 28\% in closed-set setting and UniDA setting, respectively) compared to existing efforts. These use cases highlight SMA's potential to significantly impact the outcomes of conventional benchmarks.
Meta-Learning from Learning Curves for Budget-Limited Algorithm Selection
Oct 10, 2024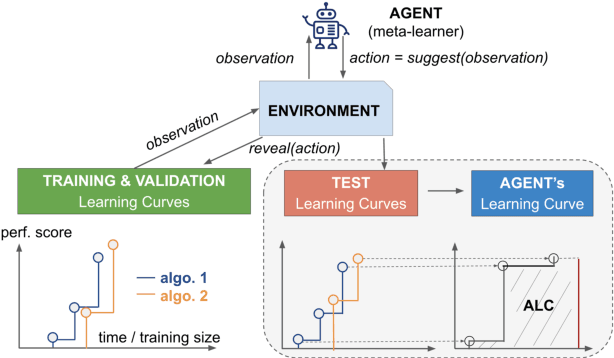
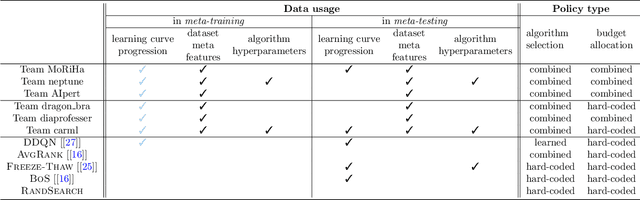
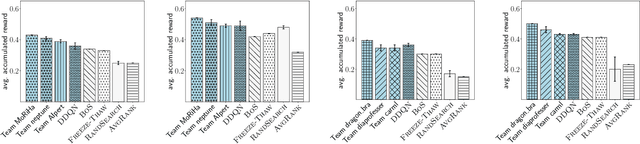
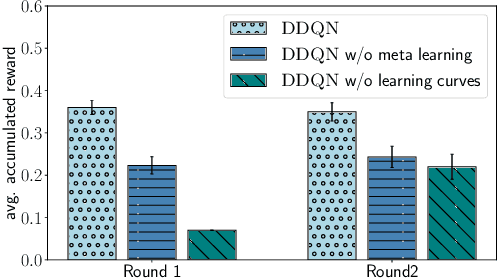
Training a large set of machine learning algorithms to convergence in order to select the best-performing algorithm for a dataset is computationally wasteful. Moreover, in a budget-limited scenario, it is crucial to carefully select an algorithm candidate and allocate a budget for training it, ensuring that the limited budget is optimally distributed to favor the most promising candidates. Casting this problem as a Markov Decision Process, we propose a novel framework in which an agent must select in the process of learning the most promising algorithm without waiting until it is fully trained. At each time step, given an observation of partial learning curves of algorithms, the agent must decide whether to allocate resources to further train the most promising algorithm (exploitation), to wake up another algorithm previously put to sleep, or to start training a new algorithm (exploration). In addition, our framework allows the agent to meta-learn from learning curves on past datasets along with dataset meta-features and algorithm hyperparameters. By incorporating meta-learning, we aim to avoid myopic decisions based solely on premature learning curves on the dataset at hand. We introduce two benchmarks of learning curves that served in international competitions at WCCI'22 and AutoML-conf'22, of which we analyze the results. Our findings show that both meta-learning and the progression of learning curves enhance the algorithm selection process, as evidenced by methods of winning teams and our DDQN baseline, compared to heuristic baselines or a random search. Interestingly, our cost-effective baseline, which selects the best-performing algorithm w.r.t. a small budget, can perform decently when learning curves do not intersect frequently.
RelevAI-Reviewer: A Benchmark on AI Reviewers for Survey Paper Relevance
Jun 13, 2024



Recent advancements in Artificial Intelligence (AI), particularly the widespread adoption of Large Language Models (LLMs), have significantly enhanced text analysis capabilities. This technological evolution offers considerable promise for automating the review of scientific papers, a task traditionally managed through peer review by fellow researchers. Despite its critical role in maintaining research quality, the conventional peer-review process is often slow and subject to biases, potentially impeding the swift propagation of scientific knowledge. In this paper, we propose RelevAI-Reviewer, an automatic system that conceptualizes the task of survey paper review as a classification problem, aimed at assessing the relevance of a paper in relation to a specified prompt, analogous to a "call for papers". To address this, we introduce a novel dataset comprised of 25,164 instances. Each instance contains one prompt and four candidate papers, each varying in relevance to the prompt. The objective is to develop a machine learning (ML) model capable of determining the relevance of each paper and identifying the most pertinent one. We explore various baseline approaches, including traditional ML classifiers like Support Vector Machine (SVM) and advanced language models such as BERT. Preliminary findings indicate that the BERT-based end-to-end classifier surpasses other conventional ML methods in performance. We present this problem as a public challenge to foster engagement and interest in this area of research.
Towards AutoML in the presence of Drift: first results
Jul 24, 2019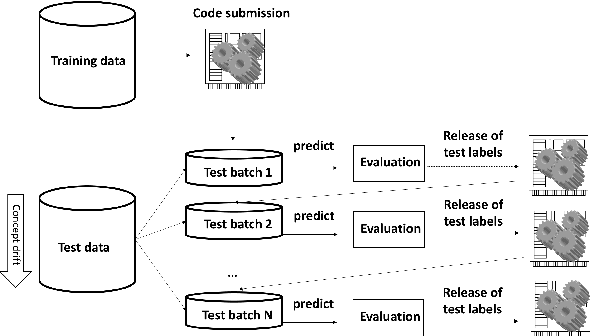
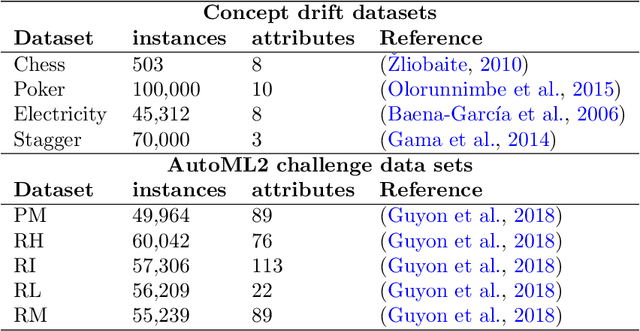

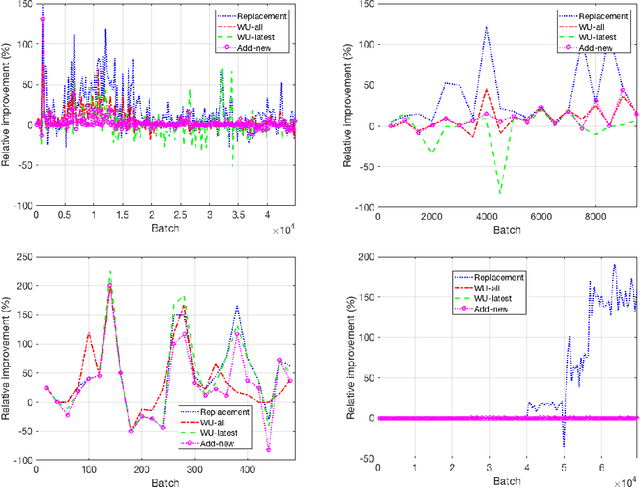
Research progress in AutoML has lead to state of the art solutions that can cope quite wellwith supervised learning task, e.g., classification with AutoSklearn. However, so far thesesystems do not take into account the changing nature of evolving data over time (i.e., theystill assume i.i.d. data); even when this sort of domains are increasingly available in realapplications (e.g., spam filtering, user preferences, etc.). We describe a first attempt to de-velop an AutoML solution for scenarios in which data distribution changes relatively slowlyover time and in which the problem is approached in a lifelong learning setting. We extendAuto-Sklearn with sound and intuitive mechanisms that allow it to cope with this sort ofproblems. The extended Auto-Sklearn is combined with concept drift detection techniquesthat allow it to automatically determine when the initial models have to be adapted. Wereport experimental results in benchmark data from AutoML competitions that adhere tothis scenario. Results demonstrate the effectiveness of the proposed methodology.