 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Inference for Model-Free and Model-Based Reinforcement Learning
Sep 04, 2022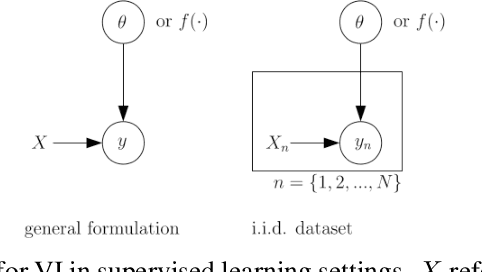

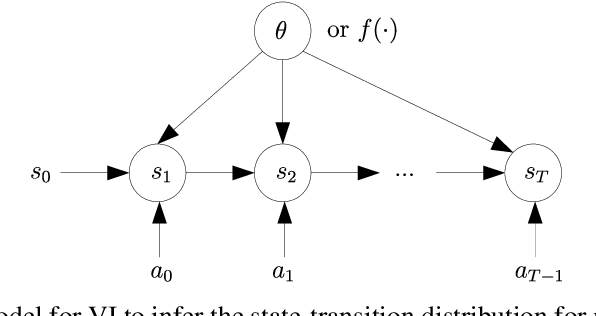
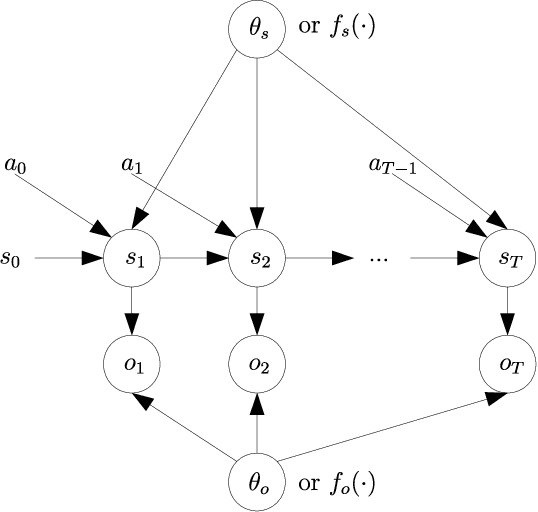
Variational inference (VI) is a specific type of approximate Bayesian inference that approximates an intractable posterior distribution with a tractable one. VI casts the inference problem as an optimization problem, more specifically, the goal is to maximize a lower bound of the logarithm of the marginal likelihood with respect to the parameters of the approximate posterior. Reinforcement learning (RL) on the other hand deals with autonomous agents and how to make them act optimally such as to maximize some notion of expected future cumulative reward. In the non-sequential setting where agents' actions do not have an impact on future states of the environment, RL is covered by contextual bandits and Bayesian optimization. In a proper sequential scenario, however, where agents' actions affect future states, instantaneous rewards need to be carefully traded off against potential long-term rewards. This manuscript shows how the apparently different subjects of VI and RL are linked in two fundamental ways. First, the optimization objective of RL to maximize future cumulative rewards can be recovered via a VI objective under a soft policy constraint in both the non-sequential and the sequential setting. This policy constraint is not just merely artificial but has proven as a useful regularizer in many RL tasks yielding significant improvements in agent performance. And second, in model-based RL where agents aim to learn about the environment they are operating in, the model-learning part can be naturally phrased as an inference problem over the process that governs environment dynamics. We are going to distinguish between two scenarios for the latter: VI when environment states are fully observable by the agent and VI when they are only partially observable through an observation distribution.
Bellman: A Toolbox for Model-Based Reinforcement Learning in TensorFlow
Apr 13, 2021
In the past decade, model-free reinforcement learning (RL) has provided solutions to challenging domains such as robotics. Model-based RL shows the prospect of being more sample-efficient than model-free methods in terms of agent-environment interactions, because the model enables to extrapolate to unseen situations. In the more recent past, model-based methods have shown superior results compared to model-free methods in some challenging domains with non-linear state transitions. At the same time, it has become apparent that RL is not market-ready yet and that many real-world applications are going to require model-based approaches, because model-free methods are too sample-inefficient and show poor performance in early stages of training. The latter is particularly important in industry, e.g. in production systems that directly impact a company's revenue. This demonstrates the necessity for a toolbox to push the boundaries for model-based RL. While there is a plethora of toolboxes for model-free RL, model-based RL has received little attention in terms of toolbox development. Bellman aims to fill this gap and introduces the first thoroughly designed and tested model-based RL toolbox using state-of-the-art software engineering practices. Our modular approach enables to combine a wide range of environment models with generic model-based agent classes that recover state-of-the-art algorithms. We also provide an experiment harness to compare both model-free and model-based agents in a systematic fashion w.r.t. user-defined evaluation metrics (e.g. cumulative reward). This paves the way for new research directions, e.g. investigating uncertainty-aware environment models that are not necessarily neural-network-based, or developing algorithms to solve industrially-motivated benchmarks that share characteristics with real-world problems.
GPflux: A Library for Deep Gaussian Processes
Apr 12, 2021
We introduce GPflux, a Python library for Bayesian deep learning with a strong emphasis on deep Gaussian processes (DGPs). Implementing DGPs is a challenging endeavour due to the various mathematical subtleties that arise when dealing with multivariate Gaussian distributions and the complex bookkeeping of indices. To date, there are no actively maintained, open-sourced and extendable libraries available that support research activities in this area. GPflux aims to fill this gap by providing a library with state-of-the-art DGP algorithms, as well as building blocks for implementing novel Bayesian and GP-based hierarchical models and inference schemes. GPflux is compatible with and built on top of the Keras deep learning eco-system. This enables practitioners to leverage tools from the deep learning community for building and training customised Bayesian models, and create hierarchical models that consist of Bayesian and standard neural network layers in a single coherent framework. GPflux relies on GPflow for most of its GP objects and operations, which makes it an efficient, modular and extensible library, while having a lean codebase.
A Tutorial on Sparse Gaussian Processes and Variational Inference
Feb 02, 2021

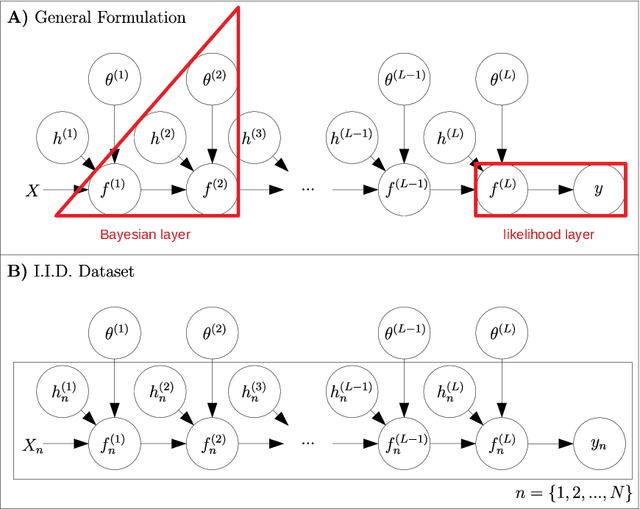
Gaussian processes (GPs) provide a framework for Bayesian inference that can offer principled uncertainty estimates for a large range of problems. For example, if we consider regression problems with Gaussian likelihoods, a GP model enjoys a posterior in closed form. However, identifying the posterior GP scales cubically with the number of training examples and requires to store all examples in memory. In order to overcome these obstacles, sparse GPs have been proposed that approximate the true posterior GP with pseudo-training examples. Importantly, the number of pseudo-training examples is user-defined and enables control over computational and memory complexity. In the general case, sparse GPs do not enjoy closed-form solutions and one has to resort to approximate inference. In this context, a convenient choice for approximate inference is variational inference (VI), where the problem of Bayesian inference is cast as an optimization problem -- namely, to maximize a lower bound of the log marginal likelihood. This paves the way for a powerful and versatile framework, where pseudo-training examples are treated as optimization arguments of the approximate posterior that are jointly identified together with hyperparameters of the generative model (i.e. prior and likelihood). The framework can naturally handle a wide scope of supervised learning problems, ranging from regression with heteroscedastic and non-Gaussian likelihoods to classification problems with discrete labels, but also multilabel problems. The purpose of this tutorial is to provide access to the basic matter for readers without prior knowledge in both GPs and VI. A proper exposition to the subject enables also access to more recent advances (like importance-weighted VI as well as inderdomain, multioutput and deep GPs) that can serve as an inspiration for new research ideas.
Mutual-Information Regularization in Markov Decision Processes and Actor-Critic Learning
Sep 11, 2019
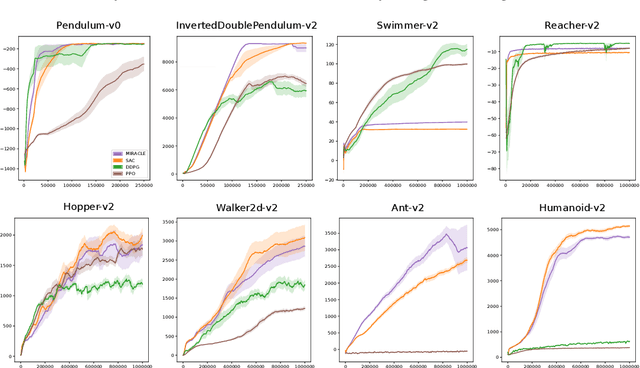


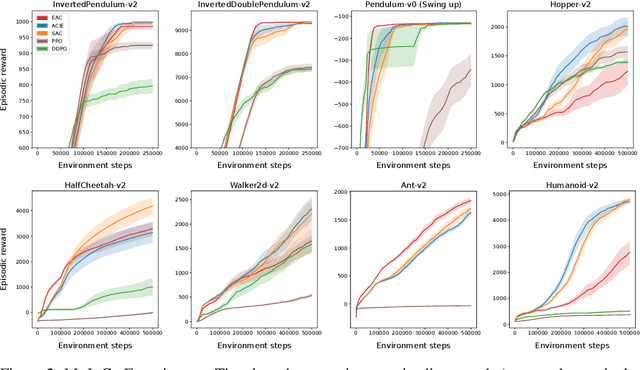
Cumulative entropy regularization introduces a regulatory signal to the reinforcement learning (RL) problem that encourages policies with high-entropy actions, which is equivalent to enforcing small deviations from a uniform reference marginal policy. This has been shown to improve exploration and robustness, and it tackles the value overestimation problem. It also leads to a significant performance increase in tabular and high-dimensional settings, as demonstrated via algorithms such as soft Q-learning (SQL) and soft actor-critic (SAC). Cumulative entropy regularization has been extended to optimize over the reference marginal policy instead of keeping it fixed, yielding a regularization that minimizes the mutual information between states and actions. While this has been initially proposed for Markov Decision Processes (MDPs) in tabular settings, it was recently shown that a similar principle leads to significant improvements over vanilla SQL in RL for high-dimensional domains with discrete actions and function approximators. Here, we follow the motivation of mutual-information regularization from an inference perspective and theoretically analyze the corresponding Bellman operator. Inspired by this Bellman operator, we devise a novel mutual-information regularized actor-critic learning (MIRACLE) algorithm for continuous action spaces that optimizes over the reference marginal policy. We empirically validate MIRACLE in the Mujoco robotics simulator, where we demonstrate that it can compete with contemporary RL methods. Most notably, it can improve over the model-free state-of-the-art SAC algorithm which implicitly assumes a fixed reference policy.
A Unified Bellman Optimality Principle Combining Reward Maximization and Empowerment
Sep 09, 2019
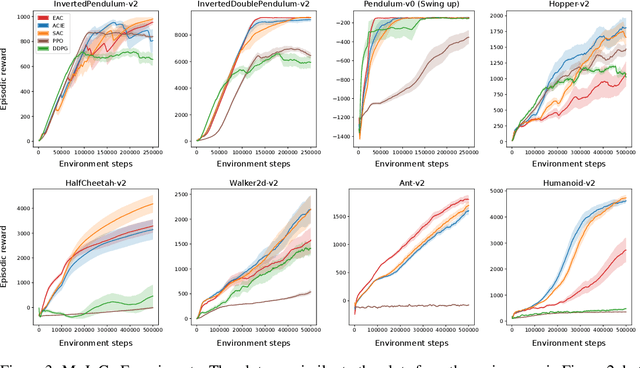
Empowerment is an information-theoretic method that can be used to intrinsically motivate learning agents. It attempts to maximize an agent's control over the environment by encouraging visiting states with a large number of reachable next states. Empowered learning has been shown to lead to complex behaviors, without requiring an explicit reward signal. In this paper, we investigate the use of empowerment in the presence of an extrinsic reward signal. We hypothesize that empowerment can guide reinforcement learning (RL) agents to find good early behavioral solutions by encouraging highly empowered states. We propose a unified Bellman optimality principle for empowered reward maximization. Our empowered reward maximization approach generalizes both Bellman's optimality principle as well as recent information-theoretical extensions to it. We prove uniqueness of the empowered values and show convergence to the optimal solution. We then apply this idea to develop off-policy actor-critic RL algorithms for high-dimensional continuous domains. We experimentally validate our methods in robotics domains (MuJoCo). Our methods demonstrate improved initial and competitive final performance compared to model-free state-of-the-art techniques.
Model-Based Stabilisation of Deep Reinforcement Learning
Sep 06, 2018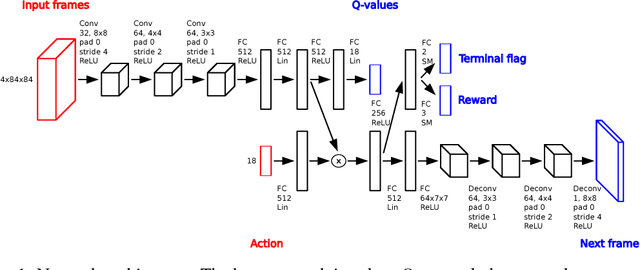
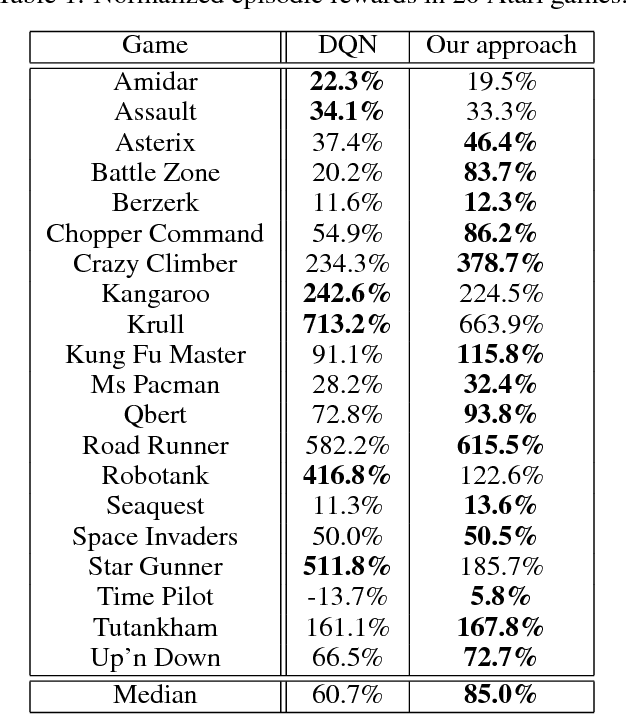
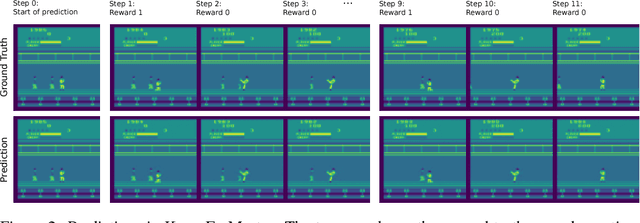
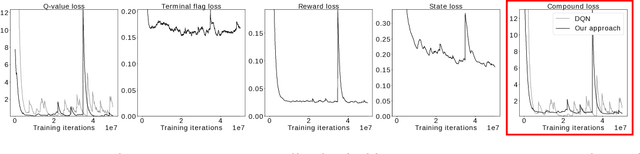
Though successful in high-dimensional domains, deep reinforcement learning exhibits high sample complexity and suffers from stability issues as reported by researchers and practitioners in the field. These problems hinder the application of such algorithms in real-world and safety-critical scenarios. In this paper, we take steps towards stable and efficient reinforcement learning by following a model-based approach that is known to reduce agent-environment interactions. Namely, our method augments deep Q-networks (DQNs) with model predictions for transitions, rewards, and termination flags. Having the model at hand, we then conduct a rigorous theoretical study of our algorithm and show, for the first time, convergence to a stationary point. En route, we provide a counter-example showing that 'vanilla' DQNs can diverge confirming practitioners' and researchers' experiences. Our proof is novel in its own right and can be extended to other forms of deep reinforcement learning. In particular, we believe exploiting the relation between reinforcement (with deep function approximators) and online learning can serve as a recipe for future proofs in the domain. Finally, we validate our theoretical results in 20 games from the Atari benchmark. Our results show that following the proposed model-based learning approach not only ensures convergence but leads to a reduction in sample complexity and superior performance.
Regularised Deep Reinforcement Learning with Guaranteed Convergence
Sep 06, 2018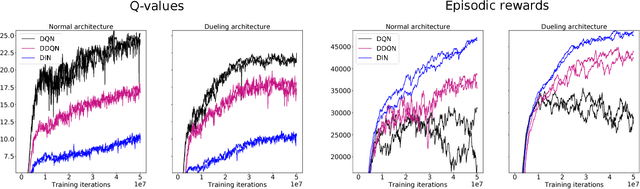
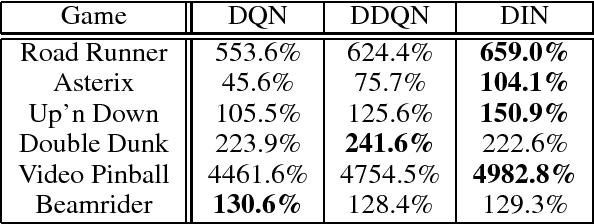
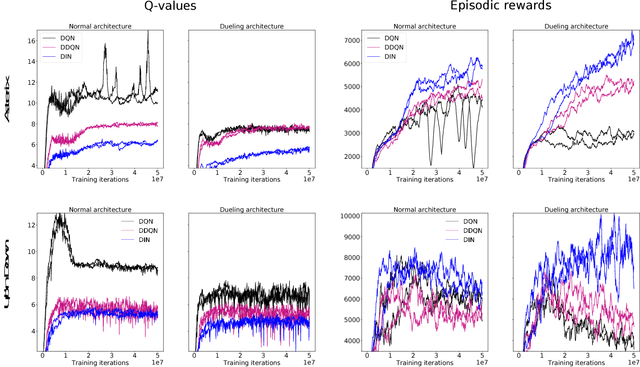
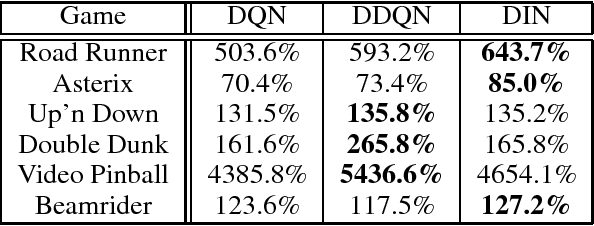
Deep Q-networks (DQNs) suffer from two important challenges hindering their application in real-world scenarios. First, DQNs overestimate Q-values which leads to increased sample complexity, and second, no theoretical convergence guarantees have been established. In this paper, we address both problems by introducing an intrinsic penalty signal arising from a Kullback-Leibler (KL) constraint that encourages reduced Q-value estimates. We then prove, for the first time, convergence to a stationary point under a specific scheduling of the penalisation magnitude. Our proofs operate in the deep reinforcement learning setting that considers convolutional and dense layers for Q-function approximation. Furthermore, we prove divergence of standard DQNs using a counter example that relates to the non-optimal choice of the history-scheduling parameter adopted by `vanilla' DQNs. We believe this can shed the light on some of the difficulties reported by researchers and practitioners in the field.
An information-theoretic on-line update principle for perception-action coupling
Apr 16, 2018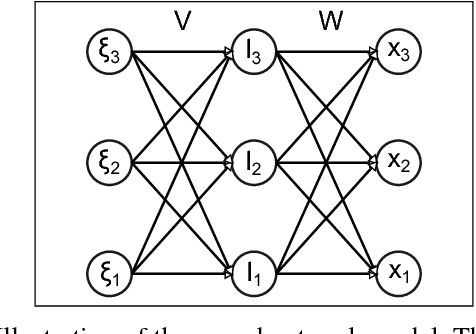


Inspired by findings of sensorimotor coupling in humans and animals, there has recently been a growing interest in the interaction between action and perception in robotic systems [Bogh et al., 2016]. Here we consider perception and action as two serial information channels with limited information-processing capacity. We follow [Genewein et al., 2015] and formulate a constrained optimization problem that maximizes utility under limited information-processing capacity in the two channels. As a solution we obtain an optimal perceptual channel and an optimal action channel that are coupled such that perceptual information is optimized with respect to downstream processing in the action module. The main novelty of this study is that we propose an online optimization procedure to find bounded-optimal perception and action channels in parameterized serial perception-action systems. In particular, we implement the perceptual channel as a multi-layer neural network and the action channel as a multinomial distribution. We illustrate our method in a NAO robot simulator with a simplified cup lifting task.
Balancing Two-Player Stochastic Games with Soft Q-Learning
Feb 09, 2018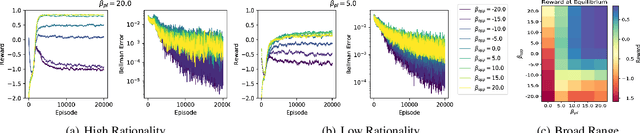
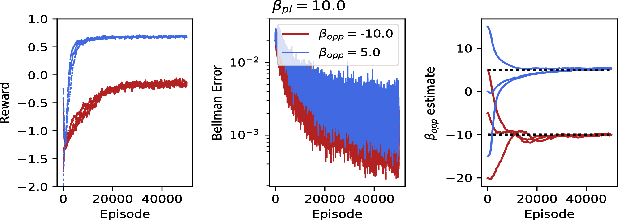
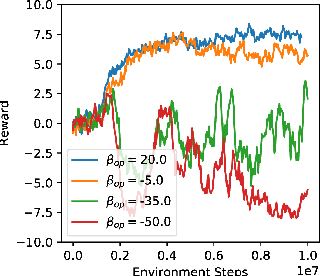

Within the context of video games the notion of perfectly rational agents can be undesirable as it leads to uninteresting situations, where humans face tough adversarial decision makers. Current frameworks for stochastic games and reinforcement learning prohibit tuneable strategies as they seek optimal performance. In this paper, we enable such tuneable behaviour by generalising soft Q-learning to stochastic games, where more than one agent interact strategically. We contribute both theoretically and empirically. On the theory side, we show that games with soft Q-learning exhibit a unique value and generalise team games and zero-sum games far beyond these two extremes to cover a continuous spectrum of gaming behaviour. Experimentally, we show how tuning agents' constraints affect performance and demonstrate, through a neural network architecture, how to reliably balance games with high-dimensional representations.