 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess-Aware Procurement Lead Time Prediction for Shipyard Delay Mitigation
Jan 27, 2026Accurately predicting procurement lead time (PLT) remains a challenge in engineered-to-order industries such as shipbuilding and plant construction, where delays in a single key component can disrupt project timelines. In shipyards, pipe spools are critical components; installed deep within hull blocks soon after steel erection, any delay in their procurement can halt all downstream tasks. Recognizing their importance, existing studies predict PLT using the static physical attributes of pipe spools. However, procurement is inherently a dynamic, multi-stakeholder business process involving a continuous sequence of internal and external events at the shipyard, factors often overlooked in traditional approaches. To address this issue, this paper proposes a novel framework that combines event logs, dataset records of the procurement events, with static attributes to predict PLT. The temporal attributes of each event are extracted to reflect the continuity and temporal context of the process. Subsequently, a deep sequential neural network combined with a multi-layered perceptron is employed to integrate these static and dynamic features, enabling the model to capture both structural and contextual information in procurement. Comparative experiments are conducted using real-world pipe spool procurement data from a globally renowned South Korean shipbuilding corporation. Three tasks are evaluated, which are production, post-processing, and procurement lead time prediction. The results show a 22.6% to 50.4% improvement in prediction performance in terms of mean absolute error over the best-performing existing approaches across the three tasks. These findings indicate the value of considering procurement process information for more accurate PLT prediction.
Bellman: A Toolbox for Model-Based Reinforcement Learning in TensorFlow
Apr 13, 2021
In the past decade, model-free reinforcement learning (RL) has provided solutions to challenging domains such as robotics. Model-based RL shows the prospect of being more sample-efficient than model-free methods in terms of agent-environment interactions, because the model enables to extrapolate to unseen situations. In the more recent past, model-based methods have shown superior results compared to model-free methods in some challenging domains with non-linear state transitions. At the same time, it has become apparent that RL is not market-ready yet and that many real-world applications are going to require model-based approaches, because model-free methods are too sample-inefficient and show poor performance in early stages of training. The latter is particularly important in industry, e.g. in production systems that directly impact a company's revenue. This demonstrates the necessity for a toolbox to push the boundaries for model-based RL. While there is a plethora of toolboxes for model-free RL, model-based RL has received little attention in terms of toolbox development. Bellman aims to fill this gap and introduces the first thoroughly designed and tested model-based RL toolbox using state-of-the-art software engineering practices. Our modular approach enables to combine a wide range of environment models with generic model-based agent classes that recover state-of-the-art algorithms. We also provide an experiment harness to compare both model-free and model-based agents in a systematic fashion w.r.t. user-defined evaluation metrics (e.g. cumulative reward). This paves the way for new research directions, e.g. investigating uncertainty-aware environment models that are not necessarily neural-network-based, or developing algorithms to solve industrially-motivated benchmarks that share characteristics with real-world problems.
Policy Optimization Through Approximated Importance Sampling
Oct 09, 2019
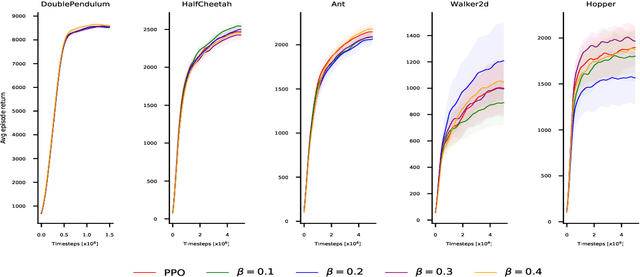
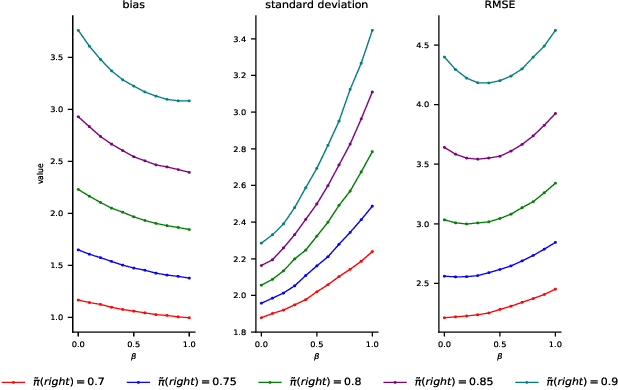
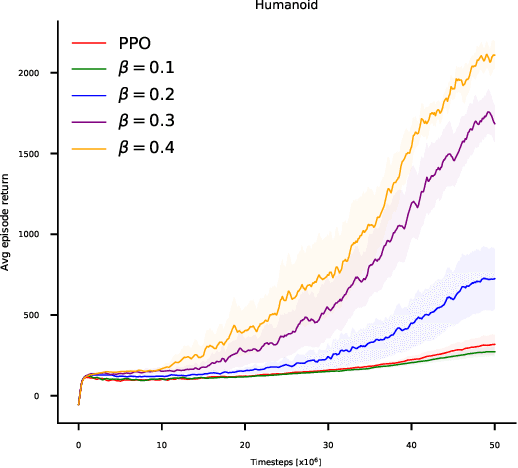
Recent policy optimization approaches (Schulman et al., 2015a, 2017) have achieved substantial empirical successes by constructing new proxy optimization objectives. These proxy objectives allow stable and low variance policy learning, but require small policy updates to ensure that the proxy objective remains an accurate approximation of the target policy value. In this paper we derive an alternative objective that obtains the value of the target policy by applying importance sampling. This objective can be directly estimated from samples, as it takes an expectation over trajectories generated by the current policy. However, the basic importance sampled objective is not suitable for policy optimization, as it incurs unacceptable variance. We therefore introduce an approximation that allows us to directly trade-off the bias of approximation with the variance in policy updates. We show that our approximation unifies the proxy optimization approaches with the importance sampling objective and allows us to interpolate between them. We then provide a theoretical analysis of the method that directly quantifies the error term due to the approximation. Finally, we obtain a practical algorithm by optimizing the introduced objective with proximal policy optimization techniques (Schulman etal., 2017). We empirically demonstrate that the result-ing algorithm yields superior performance on continuous control benchmarks
Learning from Real Users: Rating Dialogue Success with Neural Networks for Reinforcement Learning in Spoken Dialogue Systems
Aug 13, 2015

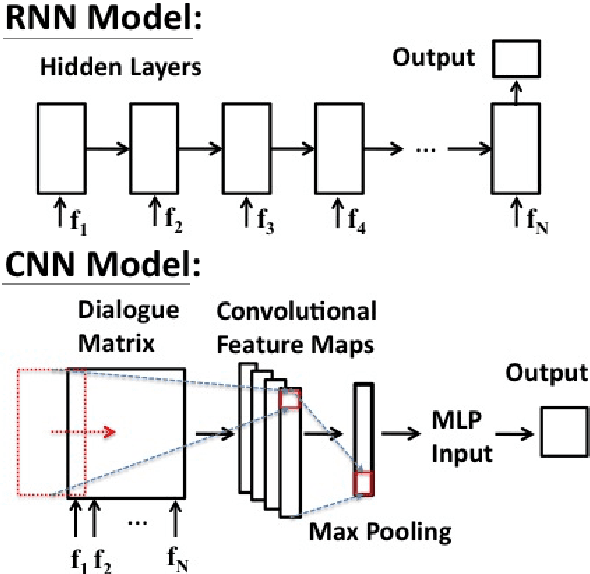
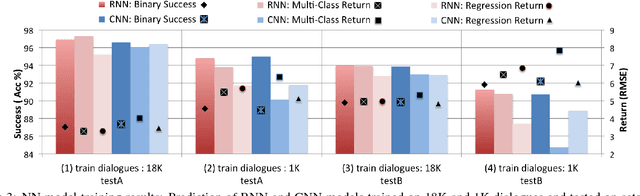
To train a statistical spoken dialogue system (SDS) it is essential that an accurate method for measuring task success is available. To date training has relied on presenting a task to either simulated or paid users and inferring the dialogue's success by observing whether this presented task was achieved or not. Our aim however is to be able to learn from real users acting under their own volition, in which case it is non-trivial to rate the success as any prior knowledge of the task is simply unavailable. User feedback may be utilised but has been found to be inconsistent. Hence, here we present two neural network models that evaluate a sequence of turn-level features to rate the success of a dialogue. Importantly these models make no use of any prior knowledge of the user's task. The models are trained on dialogues generated by a simulated user and the best model is then used to train a policy on-line which is shown to perform at least as well as a baseline system using prior knowledge of the user's task. We note that the models should also be of interest for evaluating SDS and for monitoring a dialogue in rule-based SDS.
Stochastic Language Generation in Dialogue using Recurrent Neural Networks with Convolutional Sentence Reranking
Aug 07, 2015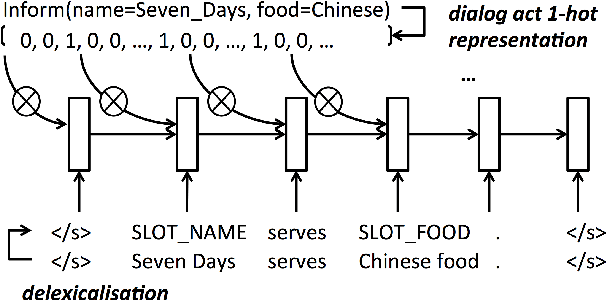

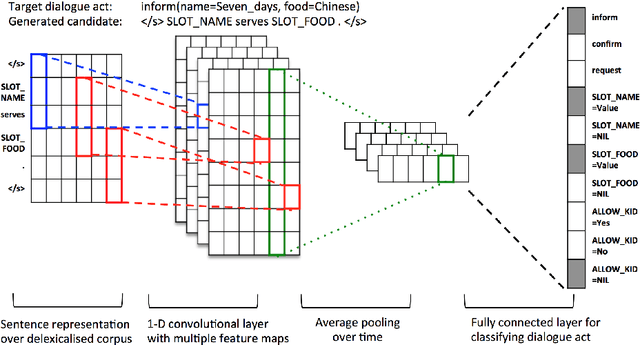
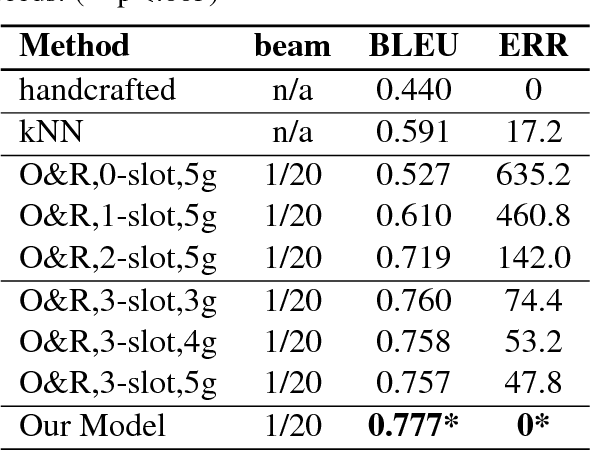
The natural language generation (NLG) component of a spoken dialogue system (SDS) usually needs a substantial amount of handcrafting or a well-labeled dataset to be trained on. These limitations add significantly to development costs and make cross-domain, multi-lingual dialogue systems intractable. Moreover, human languages are context-aware. The most natural response should be directly learned from data rather than depending on predefined syntaxes or rules. This paper presents a statistical language generator based on a joint recurrent and convolutional neural network structure which can be trained on dialogue act-utterance pairs without any semantic alignments or predefined grammar trees. Objective metrics suggest that this new model outperforms previous methods under the same experimental conditions. Results of an evaluation by human judges indicate that it produces not only high quality but linguistically varied utterances which are preferred compared to n-gram and rule-based systems.