 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Inference for Model-Free and Model-Based Reinforcement Learning
Paper and Code
Sep 04, 2022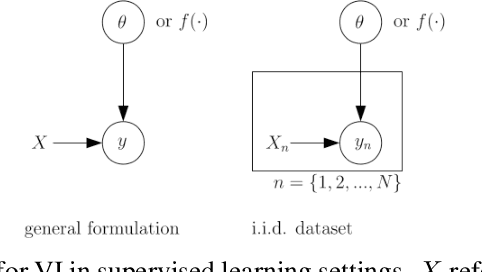

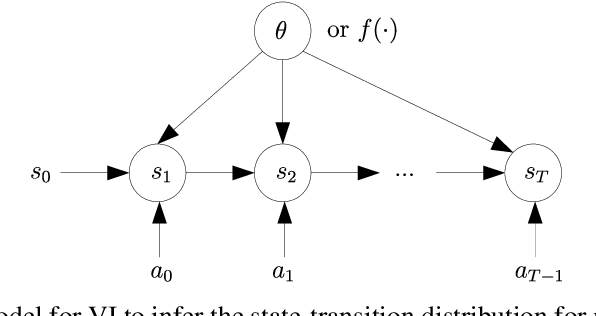
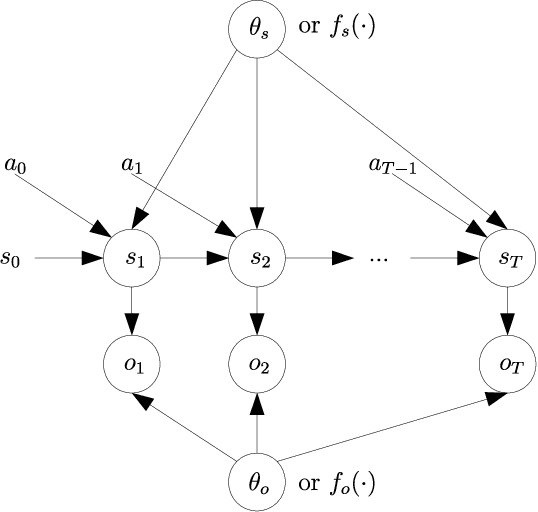
Variational inference (VI) is a specific type of approximate Bayesian inference that approximates an intractable posterior distribution with a tractable one. VI casts the inference problem as an optimization problem, more specifically, the goal is to maximize a lower bound of the logarithm of the marginal likelihood with respect to the parameters of the approximate posterior. Reinforcement learning (RL) on the other hand deals with autonomous agents and how to make them act optimally such as to maximize some notion of expected future cumulative reward. In the non-sequential setting where agents' actions do not have an impact on future states of the environment, RL is covered by contextual bandits and Bayesian optimization. In a proper sequential scenario, however, where agents' actions affect future states, instantaneous rewards need to be carefully traded off against potential long-term rewards. This manuscript shows how the apparently different subjects of VI and RL are linked in two fundamental ways. First, the optimization objective of RL to maximize future cumulative rewards can be recovered via a VI objective under a soft policy constraint in both the non-sequential and the sequential setting. This policy constraint is not just merely artificial but has proven as a useful regularizer in many RL tasks yielding significant improvements in agent performance. And second, in model-based RL where agents aim to learn about the environment they are operating in, the model-learning part can be naturally phrased as an inference problem over the process that governs environment dynamics. We are going to distinguish between two scenarios for the latter: VI when environment states are fully observable by the agent and VI when they are only partially observable through an observation distribution.