 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Bat Call Classification using Transformer Networks
Sep 20, 2023Automatically identifying bat species from their echolocation calls is a difficult but important task for monitoring bats and the ecosystem they live in. Major challenges in automatic bat call identification are high call variability, similarities between species, interfering calls and lack of annotated data. Many currently available models suffer from relatively poor performance on real-life data due to being trained on single call datasets and, moreover, are often too slow for real-time classification. Here, we propose a Transformer architecture for multi-label classification with potential applications in real-time classification scenarios. We train our model on synthetically generated multi-species recordings by merging multiple bats calls into a single recording with multiple simultaneous calls. Our approach achieves a single species accuracy of 88.92% (F1-score of 84.23%) and a multi species macro F1-score of 74.40% on our test set. In comparison to three other tools on the independent and publicly available dataset ChiroVox, our model achieves at least 25.82% better accuracy for single species classification and at least 6.9% better macro F1-score for multi species classification.
Hierarchically Structured Task-Agnostic Continual Learning
Nov 14, 2022One notable weakness of current machine learning algorithms is the poor ability of models to solve new problems without forgetting previously acquired knowledge. The Continual Learning paradigm has emerged as a protocol to systematically investigate settings where the model sequentially observes samples generated by a series of tasks. In this work, we take a task-agnostic view of continual learning and develop a hierarchical information-theoretic optimality principle that facilitates a trade-off between learning and forgetting. We derive this principle from a Bayesian perspective and show its connections to previous approaches to continual learning. Based on this principle, we propose a neural network layer, called the Mixture-of-Variational-Experts layer, that alleviates forgetting by creating a set of information processing paths through the network which is governed by a gating policy. Equipped with a diverse and specialized set of parameters, each path can be regarded as a distinct sub-network that learns to solve tasks. To improve expert allocation, we introduce diversity objectives, which we evaluate in additional ablation studies. Importantly, our approach can operate in a task-agnostic way, i.e., it does not require task-specific knowledge, as is the case with many existing continual learning algorithms. Due to the general formulation based on generic utility functions, we can apply this optimality principle to a large variety of learning problems, including supervised learning, reinforcement learning, and generative modeling. We demonstrate the competitive performance of our method on continual reinforcement learning and variants of the MNIST, CIFAR-10, and CIFAR-100 datasets.
Mixture-of-Variational-Experts for Continual Learning
Oct 25, 2021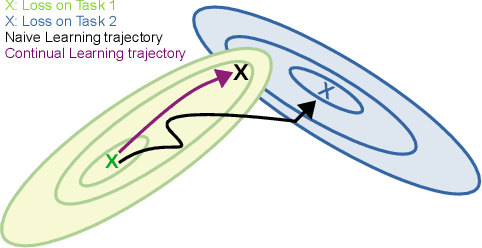
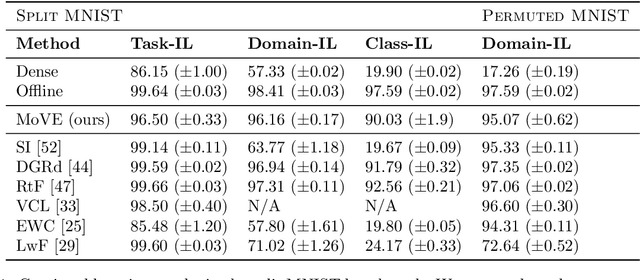
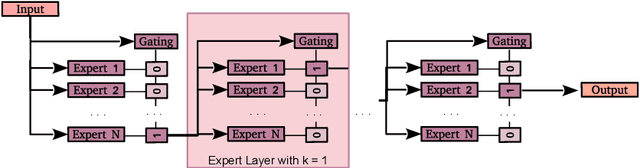
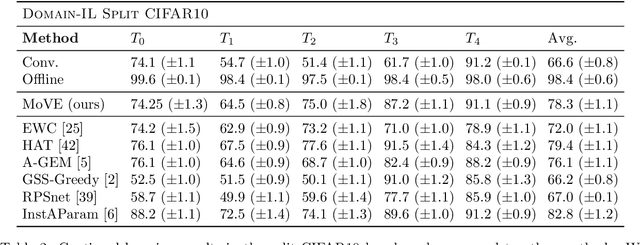
One significant shortcoming of machine learning is the poor ability of models to solve new problems quicker and without forgetting acquired knowledge. To better understand this issue, continual learning has emerged to systematically investigate learning protocols where the model sequentially observes samples generated by a series of tasks. First, we propose an optimality principle that facilitates a trade-off between learning and forgetting. We derive this principle from an information-theoretic formulation of bounded rationality and show its connections to other continual learning methods. Second, based on this principle, we propose a neural network layer for continual learning, called Mixture-of-Variational-Experts (MoVE), that alleviates forgetting while enabling the beneficial transfer of knowledge to new tasks. Our experiments on variants of the MNIST and CIFAR10 datasets demonstrate the competitive performance of MoVE layers when compared to state-of-the-art approaches.
Binary Classification: Counterbalancing Class Imbalance by Applying Regression Models in Combination with One-Sided Label Shifts
Nov 30, 2020
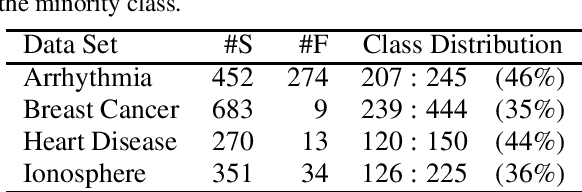
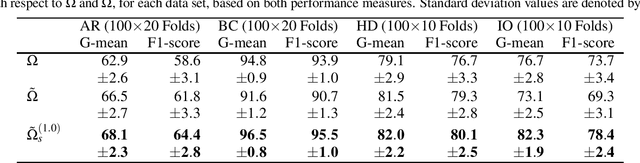
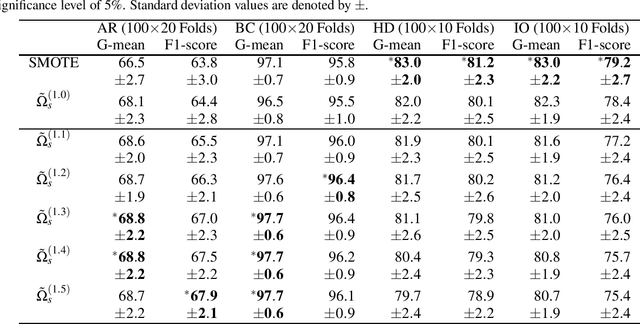
In many real-world pattern recognition scenarios, such as in medical applications, the corresponding classification tasks can be of an imbalanced nature. In the current study, we focus on binary, imbalanced classification tasks, i.e.~binary classification tasks in which one of the two classes is under-represented (minority class) in comparison to the other class (majority class). In the literature, many different approaches have been proposed, such as under- or oversampling, to counter class imbalance. In the current work, we introduce a novel method, which addresses the issues of class imbalance. To this end, we first transfer the binary classification task to an equivalent regression task. Subsequently, we generate a set of negative and positive target labels, such that the corresponding regression task becomes balanced, with respect to the redefined target label set. We evaluate our approach on a number of publicly available data sets in combination with Support Vector Machines. Moreover, we compare our proposed method to one of the most popular oversampling techniques (SMOTE). Based on the detailed discussion of the presented outcomes of our experimental evaluation, we provide promising ideas for future research directions.
Specialization in Hierarchical Learning Systems
Nov 03, 2020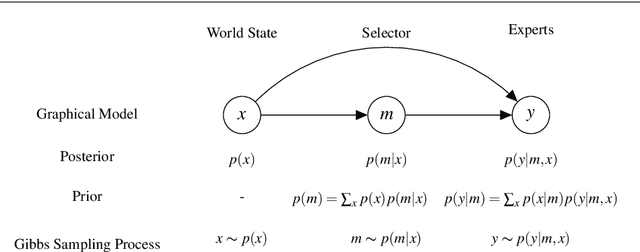
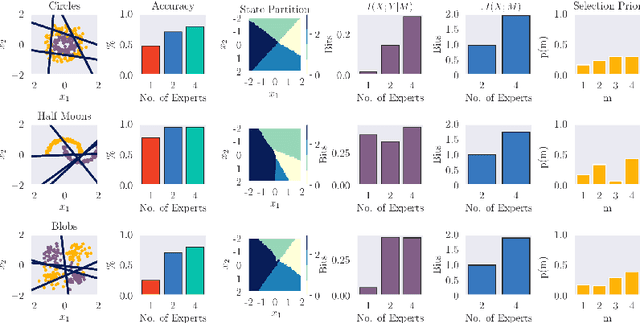
Joining multiple decision-makers together is a powerful way to obtain more sophisticated decision-making systems, but requires to address the questions of division of labor and specialization. We investigate in how far information constraints in hierarchies of experts not only provide a principled method for regularization but also to enforce specialization. In particular, we devise an information-theoretically motivated on-line learning rule that allows partitioning of the problem space into multiple sub-problems that can be solved by the individual experts. We demonstrate two different ways to apply our method: (i) partitioning problems based on individual data samples and (ii) based on sets of data samples representing tasks. Approach (i) equips the system with the ability to solve complex decision-making problems by finding an optimal combination of local expert decision-makers. Approach (ii) leads to decision-makers specialized in solving families of tasks, which equips the system with the ability to solve meta-learning problems. We show the broad applicability of our approach on a range of problems including classification, regression, density estimation, and reinforcement learning problems, both in the standard machine learning setup and in a meta-learning setting.
The Two Kinds of Free Energy and the Bayesian Revolution
Apr 24, 2020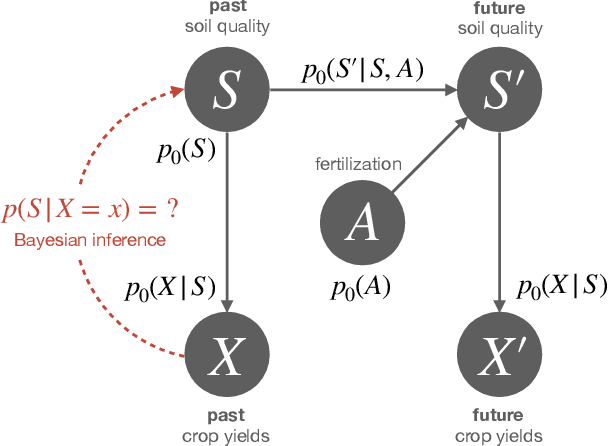
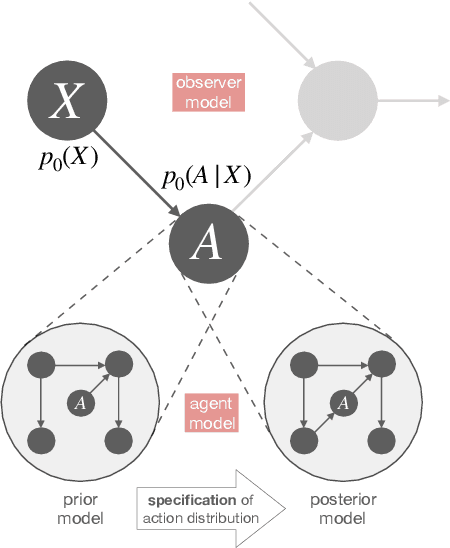
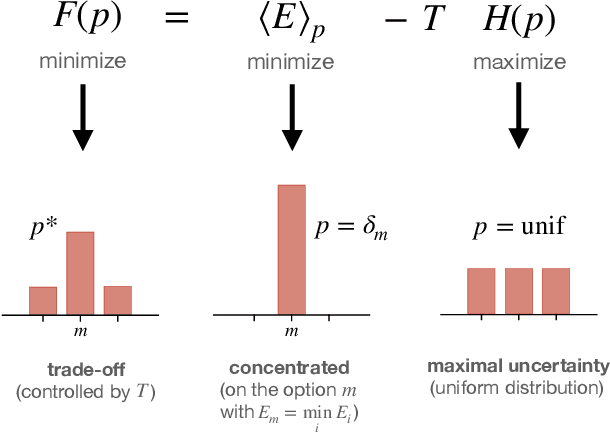
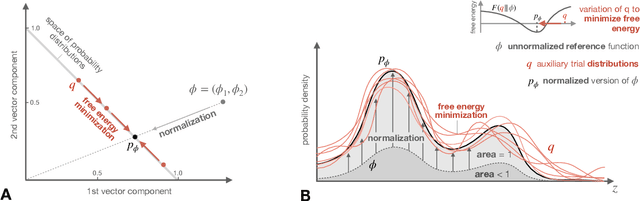
The concept of free energy has its origins in 19th century thermodynamics, but has recently found its way into the behavioral and neural sciences, where it has been promoted for its wide applicability and has even been suggested as a fundamental principle of understanding intelligent behavior and brain function. We argue that there are essentially two different notions of free energy in current models of intelligent agency, that can both be considered as applications of Bayesian inference to the problem of action selection: one that appears when trading off accuracy and uncertainty based on a general maximum entropy principle, and one that formulates action selection in terms of minimizing an error measure that quantifies deviations of beliefs and policies from given reference models. The first approach provides a normative rule for action selection in the face of model uncertainty or when information-processing capabilities are limited. The second approach directly aims to formulate the action selection problem as an inference problem in the context of Bayesian brain theories, also known as Active Inference in the literature. We elucidate the main ideas and discuss critical technical and conceptual issues revolving around these two notions of free energy that both claim to apply at all levels of decision-making, from the high-level deliberation of reasoning down to the low-level information-processing of perception.
Hierarchical Expert Networks for Meta-Learning
Dec 04, 2019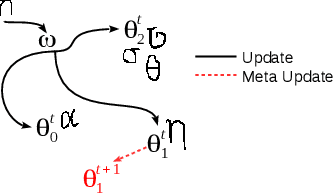


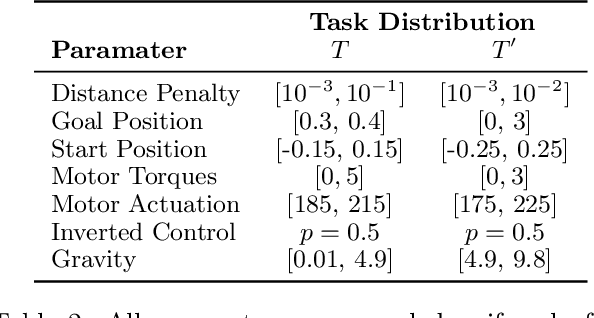
The goal of meta-learning is to train a model on a variety of learning tasks, such that it can adapt to new problems within only a few iterations. Here we propose a principled information-theoretic model that optimally partitions the underlying problem space such that the resulting partitions are processed by specialized expert decision-makers. To drive this specialization we impose the same kind of information processing constraints both on the partitioning and the expert decision-makers. We argue that this specialization leads to efficient adaptation to new tasks. To demonstrate the generality of our approach we evaluate on three meta-learning domains: image classification, regression, and reinforcement learning.
An Information-theoretic On-line Learning Principle for Specialization in Hierarchical Decision-Making Systems
Jul 26, 2019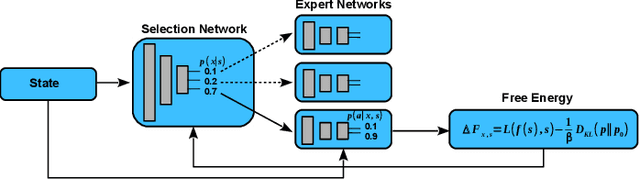
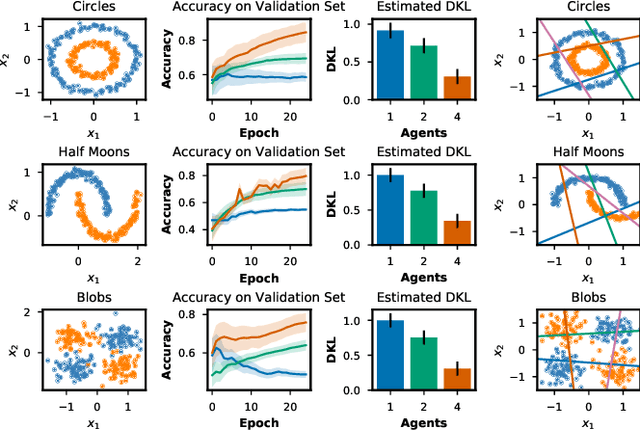
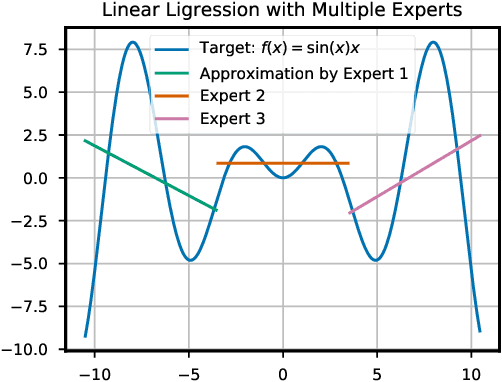
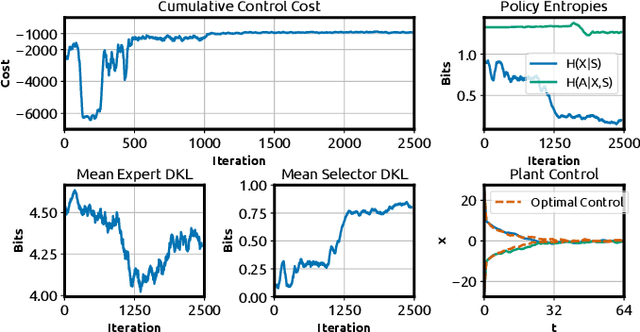
Information-theoretic bounded rationality describes utility-optimizing decision-makers whose limited information-processing capabilities are formalized by information constraints. One of the consequences of bounded rationality is that resource-limited decision-makers can join together to solve decision-making problems that are beyond the capabilities of each individual. Here, we study an information-theoretic principle that drives division of labor and specialization when decision-makers with information constraints are joined together. We devise an on-line learning rule of this principle that learns a partitioning of the problem space such that it can be solved by specialized linear policies. We demonstrate the approach for decision-making problems whose complexity exceeds the capabilities of individual decision-makers, but can be solved by combining the decision-makers optimally. The strength of the model is that it is abstract and principled, yet has direct applications in classification, regression, reinforcement learning and adaptive control.
Bounded rational decision-making from elementary computations that reduce uncertainty
Apr 08, 2019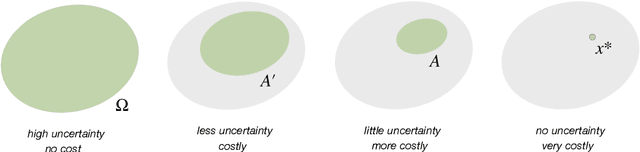
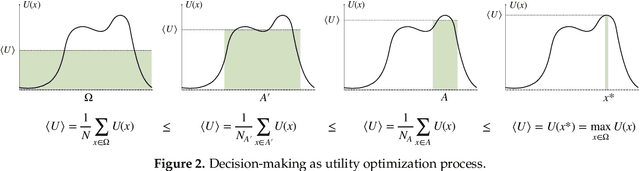

In its most basic form, decision-making can be viewed as a computational process that progressively eliminates alternatives, thereby reducing uncertainty. Such processes are generally costly, meaning that the amount of uncertainty that can be reduced is limited by the amount of available computational resources. Here, we introduce the notion of elementary computation based on a fundamental principle for probability transfers that reduce uncertainty. Elementary computations can be considered as the inverse of Pigou-Dalton transfers applied to probability distributions, closely related to the concepts of majorization, T-transforms, and generalized entropies that induce a preorder on the space of probability distributions. As a consequence we can define resource cost functions that are order-preserving and therefore monotonic with respect to the uncertainty reduction. This leads to a comprehensive notion of decision-making processes with limited resources. Along the way, we prove several new results on majorization theory, as well as on entropy and divergence measures.
Systems of bounded rational agents with information-theoretic constraints
Sep 16, 2018Specialization and hierarchical organization are important features of efficient collaboration in economical, artificial, and biological systems. Here, we investigate the hypothesis that both features can be explained by the fact that each entity of such a system is limited in a certain way. We propose an information-theoretic approach based on a Free Energy principle, in order to computationally analyze systems of bounded rational agents that deal with such limitations optimally. We find that specialization allows to focus on fewer tasks, thus leading to a more efficient execution, but in turn requires coordination in hierarchical structures of specialized experts and coordinating units. Our results suggest that hierarchical architectures of specialized units at lower levels that are coordinated by units at higher levels are optimal, given that each unit's information-processing capability is limited and conforms to constraints on complexity costs.