 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Stabilisation of Deep Reinforcement Learning
Paper and Code
Sep 06, 2018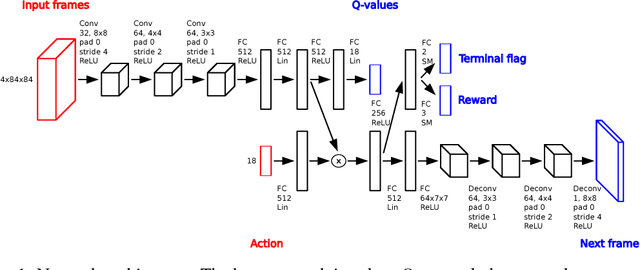
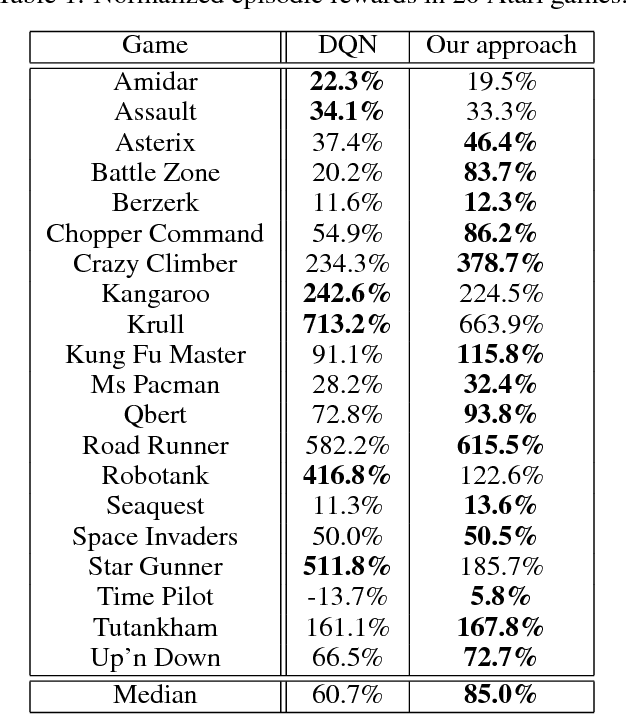
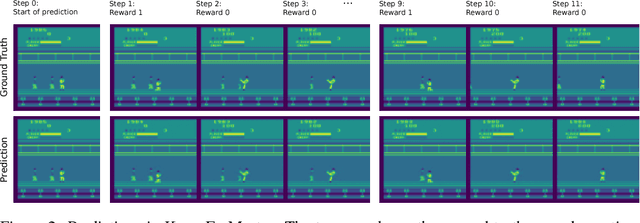
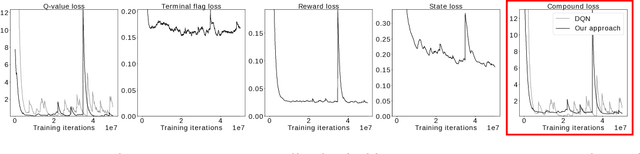
Though successful in high-dimensional domains, deep reinforcement learning exhibits high sample complexity and suffers from stability issues as reported by researchers and practitioners in the field. These problems hinder the application of such algorithms in real-world and safety-critical scenarios. In this paper, we take steps towards stable and efficient reinforcement learning by following a model-based approach that is known to reduce agent-environment interactions. Namely, our method augments deep Q-networks (DQNs) with model predictions for transitions, rewards, and termination flags. Having the model at hand, we then conduct a rigorous theoretical study of our algorithm and show, for the first time, convergence to a stationary point. En route, we provide a counter-example showing that 'vanilla' DQNs can diverge confirming practitioners' and researchers' experiences. Our proof is novel in its own right and can be extended to other forms of deep reinforcement learning. In particular, we believe exploiting the relation between reinforcement (with deep function approximators) and online learning can serve as a recipe for future proofs in the domain. Finally, we validate our theoretical results in 20 games from the Atari benchmark. Our results show that following the proposed model-based learning approach not only ensures convergence but leads to a reduction in sample complexity and superior performance.