 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Two-Player Stochastic Games with Soft Q-Learning
Paper and Code
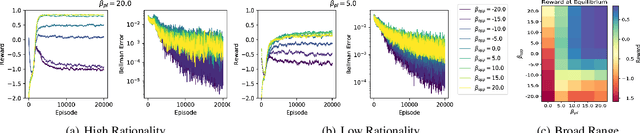
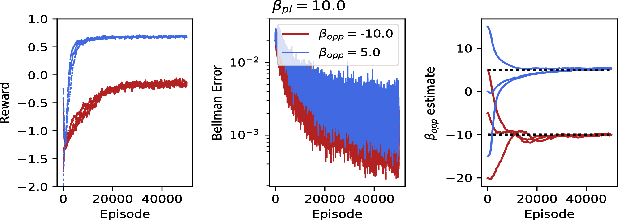
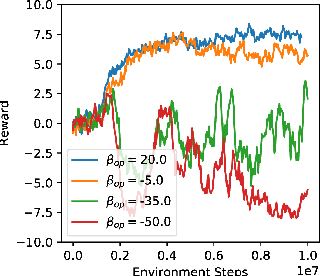

Within the context of video games the notion of perfectly rational agents can be undesirable as it leads to uninteresting situations, where humans face tough adversarial decision makers. Current frameworks for stochastic games and reinforcement learning prohibit tuneable strategies as they seek optimal performance. In this paper, we enable such tuneable behaviour by generalising soft Q-learning to stochastic games, where more than one agent interact strategically. We contribute both theoretically and empirically. On the theory side, we show that games with soft Q-learning exhibit a unique value and generalise team games and zero-sum games far beyond these two extremes to cover a continuous spectrum of gaming behaviour. Experimentally, we show how tuning agents' constraints affect performance and demonstrate, through a neural network architecture, how to reliably balance games with high-dimensional representations.