 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Hierarchical Policies for Compositional Transfer in Robotics
Paper and Code
Jun 27, 2019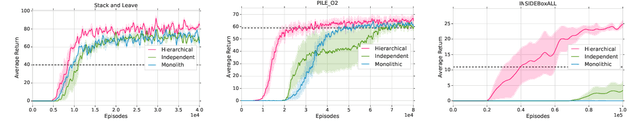
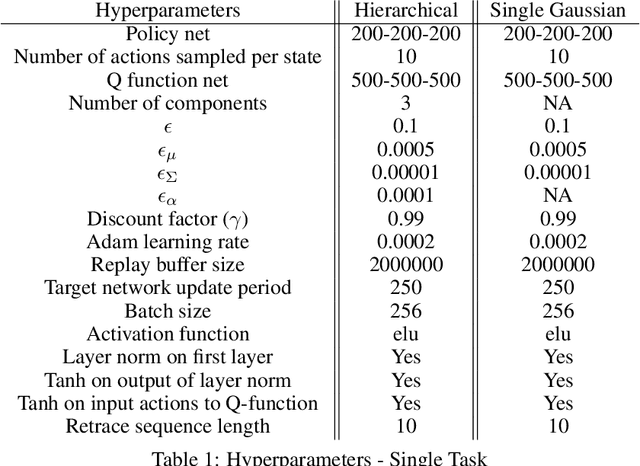

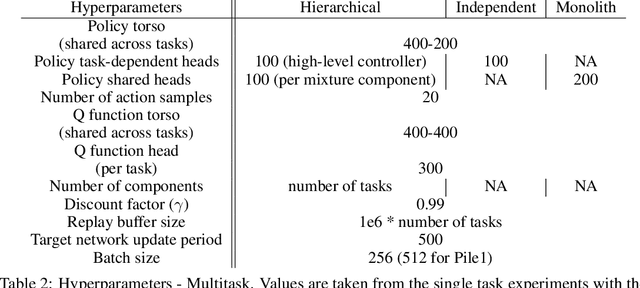
The successful application of flexible, general learning algorithms -- such as deep reinforcement learning -- to real-world robotics applications is often limited by their poor data-efficiency. Domains with more than a single dominant task of interest encourage algorithms that share partial solutions across tasks to limit the required experiment time. We develop and investigate simple hierarchical inductive biases -- in the form of structured policies -- as a mechanism for knowledge transfer across tasks in reinforcement learning (RL). To leverage the power of these structured policies we design an RL algorithm that enables stable and fast learning. We demonstrate the success of our method both in simulated robot environments (using locomotion and manipulation domains) as well as real robot experiments, demonstrating substantially better data-efficiency than competitive baselines.