 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Scientific Figures with Distantly Supervised Neural Networks
May 30, 2018
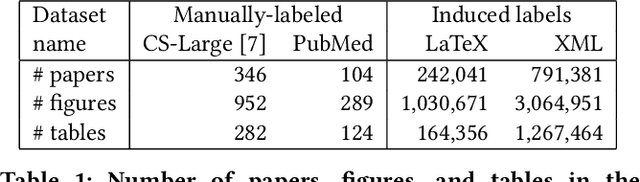
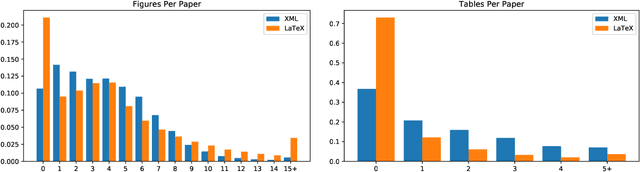
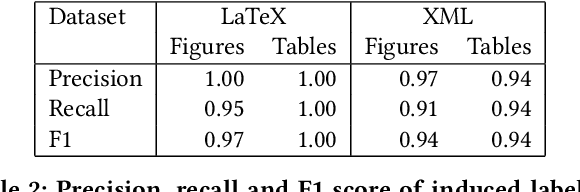
Non-textual components such as charts, diagrams and tables provide key information in many scientific documents, but the lack of large labeled datasets has impeded the development of data-driven methods for scientific figure extraction. In this paper, we induce high-quality training labels for the task of figure extraction in a large number of scientific documents, with no human intervention. To accomplish this we leverage the auxiliary data provided in two large web collections of scientific documents (arXiv and PubMed) to locate figures and their associated captions in the rasterized PDF. We share the resulting dataset of over 5.5 million induced labels---4,000 times larger than the previous largest figure extraction dataset---with an average precision of 96.8%, to enable the development of modern data-driven methods for this task. We use this dataset to train a deep neural network for end-to-end figure detection, yielding a model that can be more easily extended to new domains compared to previous work. The model was successfully deployed in Semantic Scholar, a large-scale academic search engine, and used to extract figures in 13 million scientific documents.
Content-Based Citation Recommendation
Feb 22, 2018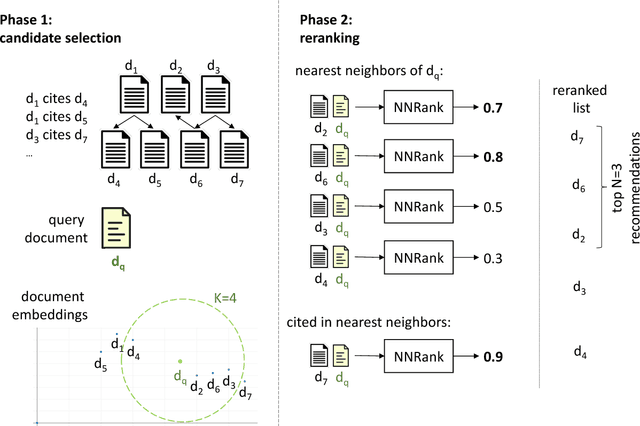
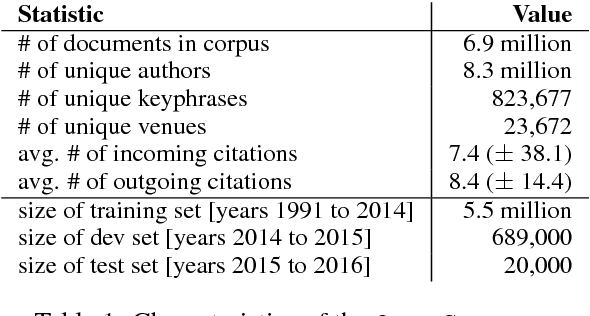
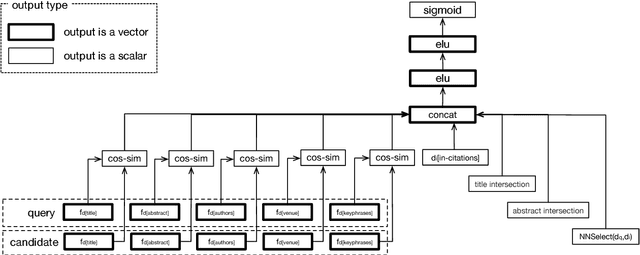
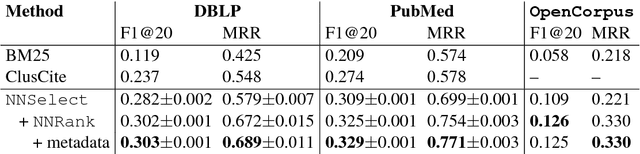
We present a content-based method for recommending citations in an academic paper draft. We embed a given query document into a vector space, then use its nearest neighbors as candidates, and rerank the candidates using a discriminative model trained to distinguish between observed and unobserved citations. Unlike previous work, our method does not require metadata such as author names which can be missing, e.g., during the peer review process. Without using metadata, our method outperforms the best reported results on PubMed and DBLP datasets with relative improvements of over 18% in F1@20 and over 22% in MRR. We show empirically that, although adding metadata improves the performance on standard metrics, it favors self-citations which are less useful in a citation recommendation setup. We release an online portal (http://labs.semanticscholar.org/citeomatic/) for citation recommendation based on our method, and a new dataset OpenCorpus of 7 million research articles to facilitate future research on this task.
End-to-End Neural Ad-hoc Ranking with Kernel Pooling
Jun 20, 2017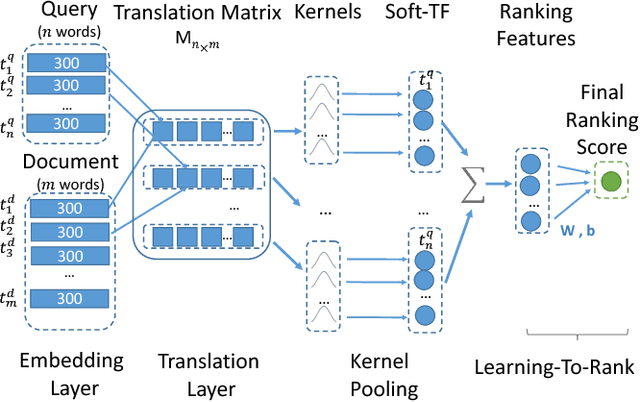


This paper proposes K-NRM, a kernel based neural model for document ranking. Given a query and a set of documents, K-NRM uses a translation matrix that models word-level similarities via word embeddings, a new kernel-pooling technique that uses kernels to extract multi-level soft match features, and a learning-to-rank layer that combines those features into the final ranking score. The whole model is trained end-to-end. The ranking layer learns desired feature patterns from the pairwise ranking loss. The kernels transfer the feature patterns into soft-match targets at each similarity level and enforce them on the translation matrix. The word embeddings are tuned accordingly so that they can produce the desired soft matches. Experiments on a commercial search engine's query log demonstrate the improvements of K-NRM over prior feature-based and neural-based states-of-the-art, and explain the source of K-NRM's advantage: Its kernel-guided embedding encodes a similarity metric tailored for matching query words to document words, and provides effective multi-level soft matches.
Semi-supervised sequence tagging with bidirectional language models
Apr 29, 2017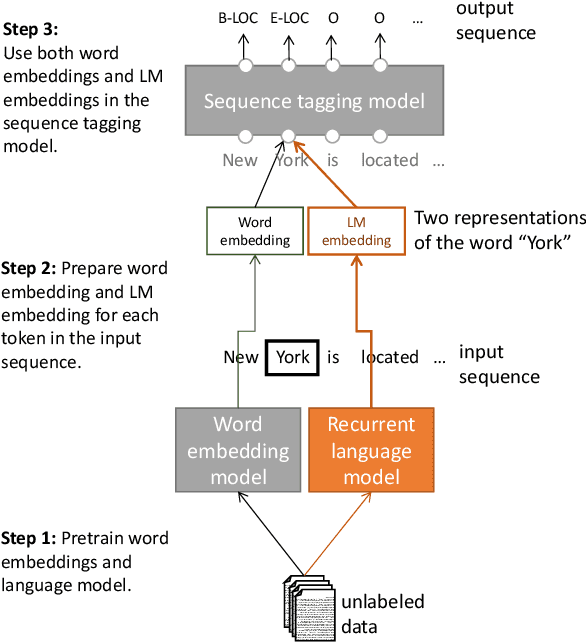
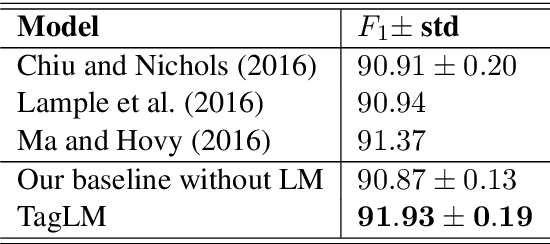


Pre-trained word embeddings learned from unlabeled text have become a standard component of neural network architectures for NLP tasks. However, in most cases, the recurrent network that operates on word-level representations to produce context sensitive representations is trained on relatively little labeled data. In this paper, we demonstrate a general semi-supervised approach for adding pre- trained context embeddings from bidirectional language models to NLP systems and apply it to sequence labeling tasks. We evaluate our model on two standard datasets for named entity recognition (NER) and chunking, and in both cases achieve state of the art results, surpassing previous systems that use other forms of transfer or joint learning with additional labeled data and task specific gazetteers.