 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-based Deep Active Learning
Paper and Code
Mar 23, 2020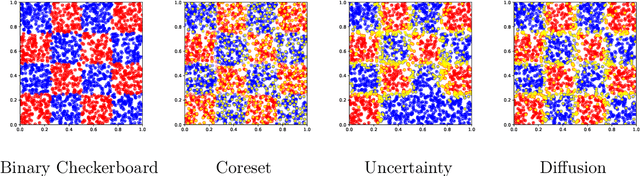
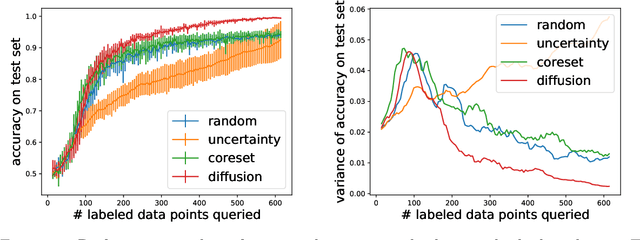
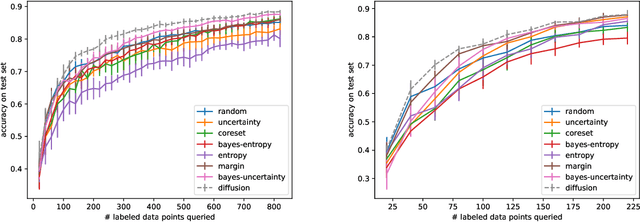
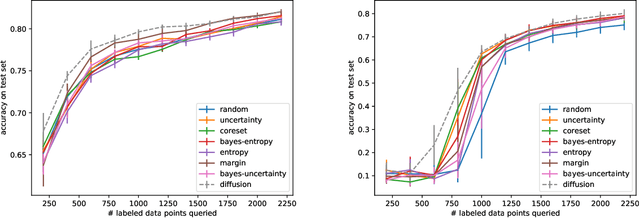
The remarkable performance of deep neural networks depends on the availability of massive labeled data. To alleviate the load of data annotation, active deep learning aims to select a minimal set of training points to be labelled which yields maximal model accuracy. Most existing approaches implement either an `exploration'-type selection criterion, which aims at exploring the joint distribution of data and labels, or a `refinement'-type criterion which aims at localizing the detected decision boundaries. We propose a versatile and efficient criterion that automatically switches from exploration to refinement when the distribution has been sufficiently mapped. Our criterion relies on a process of diffusing the existing label information over a graph constructed from the hidden representation of the data set as provided by the neural network. This graph representation captures the intrinsic geometry of the approximated labeling function. The diffusion-based criterion is shown to be advantageous as it outperforms existing criteria for deep active learning.