 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching AI to Teach: Leveraging Limited Human Salience Data Into Unlimited Saliency-Based Training
Paper and Code
Jun 08, 2023
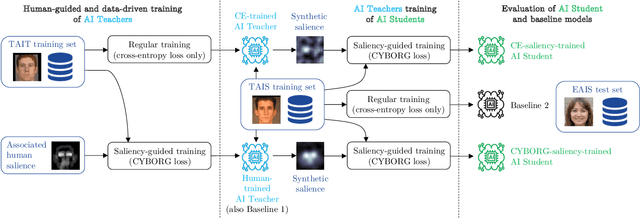

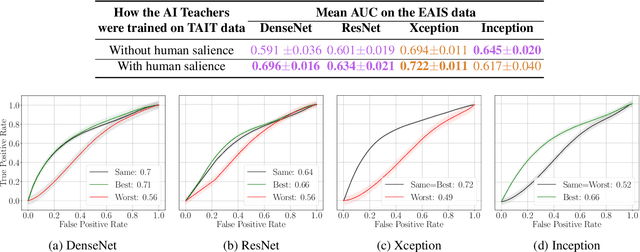
Machine learning models have shown increased accuracy in classification tasks when the training process incorporates human perceptual information. However, a challenge in training human-guided models is the cost associated with collecting image annotations for human salience. Collecting annotation data for all images in a large training set can be prohibitively expensive. In this work, we utilize ''teacher'' models (trained on a small amount of human-annotated data) to annotate additional data by means of teacher models' saliency maps. Then, ''student'' models are trained using the larger amount of annotated training data. This approach makes it possible to supplement a limited number of human-supplied annotations with an arbitrarily large number of model-generated image annotations. We compare the accuracy achieved by our teacher-student training paradigm with (1) training using all available human salience annotations, and (2) using all available training data without human salience annotations. We use synthetic face detection and fake iris detection as example challenging problems, and report results across four model architectures (DenseNet, ResNet, Xception, and Inception), and two saliency estimation methods (CAM and RISE). Results show that our teacher-student training paradigm results in models that significantly exceed the performance of both baselines, demonstrating that our approach can usefully leverage a small amount of human annotations to generate salience maps for an arbitrary amount of additional training data.