 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: Saliency-Guided Contrastive Embeddings
Nov 16, 2025Integrating human perceptual priors into the training of neural networks has been shown to raise model generalization, serve as an effective regularizer, and align models with human expertise for applications in high-risk domains. Existing approaches to integrate saliency into model training often rely on internal model mechanisms, which recent research suggests may be unreliable. Our insight is that many challenges associated with saliency-guided training stem from the placement of the guidance approaches solely within the image space. Instead, we move away from the image space, use the model's latent space embeddings to steer human guidance during training, and we propose SAGE (Saliency-Guided Contrastive Embeddings): a loss function that integrates human saliency into network training using contrastive embeddings. We apply salient-preserving and saliency-degrading signal augmentations to the input and capture the changes in embeddings and model logits. We guide the model towards salient features and away from non-salient features using a contrastive triplet loss. Additionally, we perform a sanity check on the logit distributions to ensure that the model outputs match the saliency-based augmentations. We demonstrate a boost in classification performance across both open- and closed-set scenarios against SOTA saliency-based methods, showing SAGE's effectiveness across various backbones, and include experiments to suggest its wide generalization across tasks.
Almost Right: Making First-layer Kernels Nearly Orthogonal Improves Model Generalization
Apr 23, 2025An ongoing research challenge within several domains in computer vision is how to increase model generalization capabilities. Several attempts to improve model generalization performance are heavily inspired by human perceptual intelligence, which is remarkable in both its performance and efficiency to generalize to unknown samples. Many of these methods attempt to force portions of the network to be orthogonal, following some observation within neuroscience related to early vision processes. In this paper, we propose a loss component that regularizes the filtering kernels in the first convolutional layer of a network to make them nearly orthogonal. Deviating from previous works, we give the network flexibility in which pairs of kernels it makes orthogonal, allowing the network to navigate to a better solution space, imposing harsh penalties. Without architectural modifications, we report substantial gains in generalization performance using the proposed loss against previous works (including orthogonalization- and saliency-based regularization methods) across three different architectures (ResNet-50, DenseNet-121, ViT-b-16) and two difficult open-set recognition tasks: presentation attack detection in iris biometrics, and anomaly detection in chest X-ray images.
Grains of Saliency: Optimizing Saliency-based Training of Biometric Attack Detection Models
May 01, 2024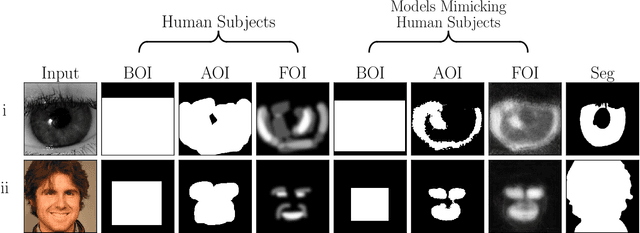
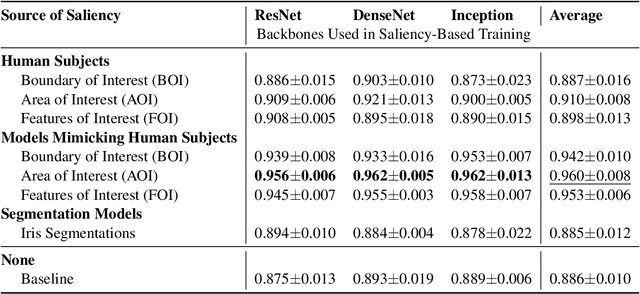
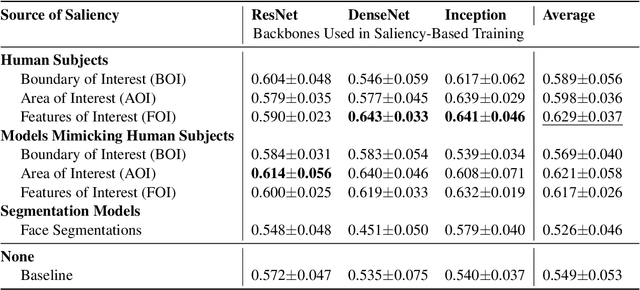
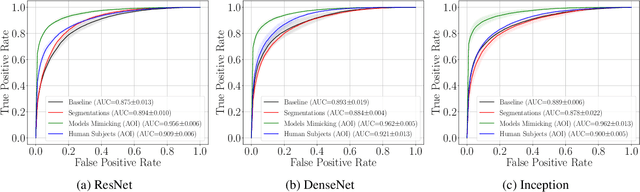
Incorporating human-perceptual intelligence into model training has shown to increase the generalization capability of models in several difficult biometric tasks, such as presentation attack detection (PAD) and detection of synthetic samples. After the initial collection phase, human visual saliency (e.g., eye-tracking data, or handwritten annotations) can be integrated into model training through attention mechanisms, augmented training samples, or through human perception-related components of loss functions. Despite their successes, a vital, but seemingly neglected, aspect of any saliency-based training is the level of salience granularity (e.g., bounding boxes, single saliency maps, or saliency aggregated from multiple subjects) necessary to find a balance between reaping the full benefits of human saliency and the cost of its collection. In this paper, we explore several different levels of salience granularity and demonstrate that increased generalization capabilities of PAD and synthetic face detection can be achieved by using simple yet effective saliency post-processing techniques across several different CNNs.
Taking Training Seriously: Human Guidance and Management-Based Regulation of Artificial Intelligence
Feb 13, 2024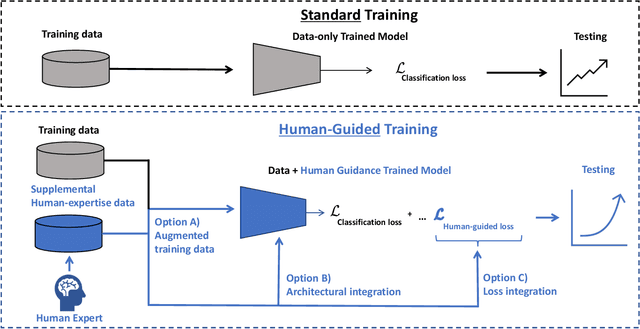
Fervent calls for more robust governance of the harms associated with artificial intelligence (AI) are leading to the adoption around the world of what regulatory scholars have called a management-based approach to regulation. Recent initiatives in the United States and Europe, as well as the adoption of major self-regulatory standards by the International Organization for Standardization, share in common a core management-based paradigm. These management-based initiatives seek to motivate an increase in human oversight of how AI tools are trained and developed. Refinements and systematization of human-guided training techniques will thus be needed to fit within this emerging era of management-based regulatory paradigm. If taken seriously, human-guided training can alleviate some of the technical and ethical pressures on AI, boosting AI performance with human intuition as well as better addressing the needs for fairness and effective explainability. In this paper, we discuss the connection between the emerging management-based regulatory frameworks governing AI and the need for human oversight during training. We broadly cover some of the technical components involved in human-guided training and then argue that the kinds of high-stakes use cases for AI that appear of most concern to regulators should lean more on human-guided training than on data-only training. We hope to foster a discussion between legal scholars and computer scientists involving how to govern a domain of technology that is vast, heterogenous, and dynamic in its applications and risks.
MENTOR: Human Perception-Guided Pretraining for Iris Presentation Detection
Oct 30, 2023



Incorporating human salience into the training of CNNs has boosted performance in difficult tasks such as biometric presentation attack detection. However, collecting human annotations is a laborious task, not to mention the questions of how and where (in the model architecture) to efficiently incorporate this information into model's training once annotations are obtained. In this paper, we introduce MENTOR (huMan pErceptioN-guided preTraining fOr iris pResentation attack detection), which addresses both of these issues through two unique rounds of training. First, we train an autoencoder to learn human saliency maps given an input iris image (both real and fake examples). Once this representation is learned, we utilize the trained autoencoder in two different ways: (a) as a pre-trained backbone for an iris presentation attack detector, and (b) as a human-inspired annotator of salient features on unknown data. We show that MENTOR's benefits are threefold: (a) significant boost in iris PAD performance when using the human perception-trained encoder's weights compared to general-purpose weights (e.g. ImageNet-sourced, or random), (b) capability of generating infinite number of human-like saliency maps for unseen iris PAD samples to be used in any human saliency-guided training paradigm, and (c) increase in efficiency of iris PAD model training. Sources codes and weights are offered along with the paper.
Teaching AI to Teach: Leveraging Limited Human Salience Data Into Unlimited Saliency-Based Training
Jun 08, 2023
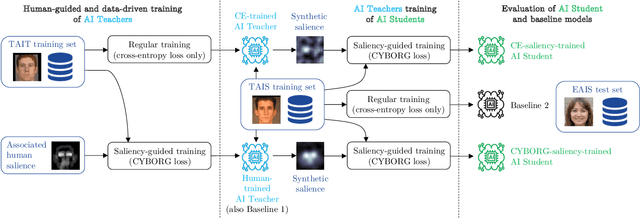

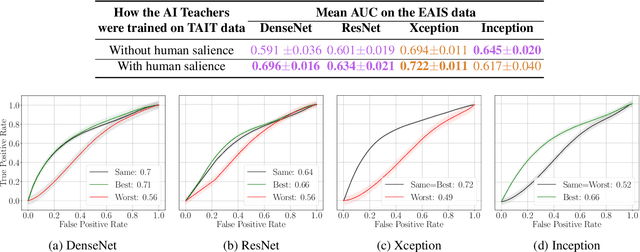
Machine learning models have shown increased accuracy in classification tasks when the training process incorporates human perceptual information. However, a challenge in training human-guided models is the cost associated with collecting image annotations for human salience. Collecting annotation data for all images in a large training set can be prohibitively expensive. In this work, we utilize ''teacher'' models (trained on a small amount of human-annotated data) to annotate additional data by means of teacher models' saliency maps. Then, ''student'' models are trained using the larger amount of annotated training data. This approach makes it possible to supplement a limited number of human-supplied annotations with an arbitrarily large number of model-generated image annotations. We compare the accuracy achieved by our teacher-student training paradigm with (1) training using all available human salience annotations, and (2) using all available training data without human salience annotations. We use synthetic face detection and fake iris detection as example challenging problems, and report results across four model architectures (DenseNet, ResNet, Xception, and Inception), and two saliency estimation methods (CAM and RISE). Results show that our teacher-student training paradigm results in models that significantly exceed the performance of both baselines, demonstrating that our approach can usefully leverage a small amount of human annotations to generate salience maps for an arbitrary amount of additional training data.