 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Mortality: Advancements in Post-Mortem Iris Recognition through Data Collection and Computer-Aided Forensic Examination
Mar 27, 2026Post-mortem iris recognition brings both hope to the forensic community (a short-term but accurate and fast means of verifying identity) as well as concerns to society (its potential illicit use in post-mortem impersonation). These hopes and concerns have grown along with the volume of research in post-mortem iris recognition. Barriers to further progress in post-mortem iris recognition include the difficult nature of data collection, and the resulting small number of approaches designed specifically for comparing iris images of deceased subjects. This paper makes several unique contributions to mitigate these barriers. First, we have collected and we offer a new dataset of NIR (compliant with ISO/IEC 19794-6 where possible) and visible-light iris images collected after demise from 259 subjects, with the largest PMI (post-mortem interval) being 1,674 hours. For one subject, the data has been collected before and after death, the first such case ever published. Second, the collected dataset was combined with publicly-available post-mortem samples to assess the current state of the art in automatic forensic iris recognition with five iris recognition methods and data originating from 338 deceased subjects. These experiments include analyses of how selected demographic factors influence recognition performance. Thirdly, this study implements a model for detecting post-mortem iris images, which can be considered as presentation attacks. Finally, we offer an open-source forensic tool integrating three post-mortem iris recognition methods with explainability elements added to make the comparison process more human-interpretable.
Stablecoin Design with Adversarial-Robust Multi-Agent Systems via Trust-Weighted Signal Aggregation
Jan 18, 2026Algorithmic stablecoins promise decentralized monetary stability by maintaining a target peg through programmatic reserve management. Yet, their reserve controllers remain vulnerable to regime-blind optimization, calibrating risk parameters on fair-weather data while ignoring tail events that precipitate cascading failures. The March 2020 Black Thursday collapse, wherein MakerDAO's collateral auctions yielded $8.3M in losses and a 15% peg deviation, exposed a critical gap: existing models like SAS systematically omit extreme volatility regimes from covariance estimates, producing allocations optimal in expectation but catastrophic under adversarial stress. We present MVF-Composer, a trust-weighted Mean-Variance Frontier reserve controller incorporating a novel Stress Harness for risk-state estimation. Our key insight is deploying multi-agent simulations as adversarial stress-testers: heterogeneous agents (traders, liquidity providers, attackers) execute protocol actions under crisis scenarios, exposing reserve vulnerabilities before they manifest on-chain. We formalize a trust-scoring mechanism T: A -> [0,1] that down-weights signals from agents exhibiting manipulative behavior, ensuring the risk-state estimator remains robust to signal injection and Sybil attacks. Across 1,200 randomized scenarios with injected Black-Swan shocks (10% collateral drawdown, 50% sentiment collapse, coordinated redemption attacks), MVF-Composer reduces peak peg deviation by 57% and mean recovery time by 3.1x relative to SAS baselines. Ablation studies confirm the trust layer accounts for 23% of stability gains under adversarial conditions, achieving 72% adversarial agent detection. Our system runs on commodity hardware, requires no on-chain oracles beyond standard price feeds, and provides a reproducible framework for stress-testing DeFi reserve policies.
Human Saliency-Driven Patch-based Matching for Interpretable Post-mortem Iris Recognition
Aug 03, 2022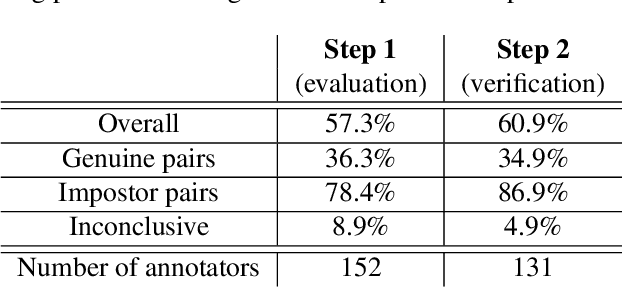
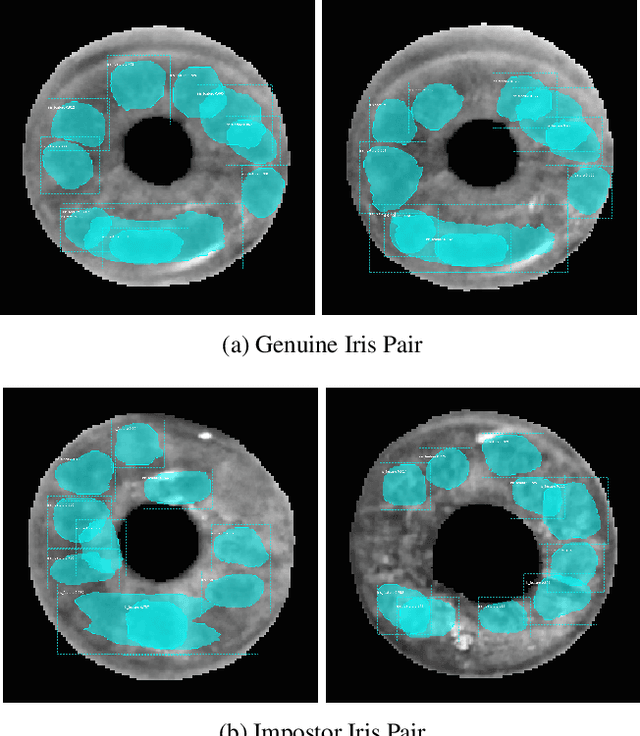
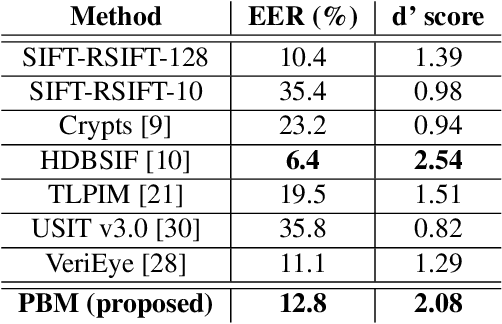
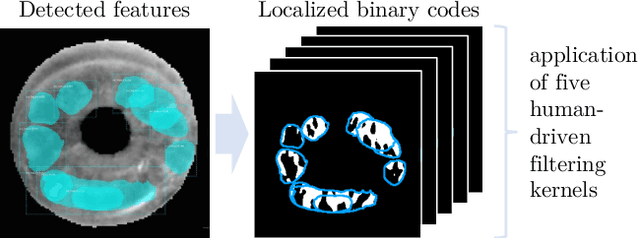
Forensic iris recognition, as opposed to live iris recognition, is an emerging research area that leverages the discriminative power of iris biometrics to aid human examiners in their efforts to identify deceased persons. As a machine learning-based technique in a predominantly human-controlled task, forensic recognition serves as "back-up" to human expertise in the task of post-mortem identification. As such, the machine learning model must be (a) interpretable, and (b) post-mortem-specific, to account for changes in decaying eye tissue. In this work, we propose a method that satisfies both requirements, and that approaches the creation of a post-mortem-specific feature extractor in a novel way employing human perception. We first train a deep learning-based feature detector on post-mortem iris images, using annotations of image regions highlighted by humans as salient for their decision making. In effect, the method learns interpretable features directly from humans, rather than purely data-driven features. Second, regional iris codes (again, with human-driven filtering kernels) are used to pair detected iris patches, which are translated into pairwise, patch-based comparison scores. In this way, our method presents human examiners with human-understandable visual cues in order to justify the identification decision and corresponding confidence score. When tested on a dataset of post-mortem iris images collected from 259 deceased subjects, the proposed method places among the three best iris matchers, demonstrating better results than the commercial (non-human-interpretable) VeriEye approach. We propose a unique post-mortem iris recognition method trained with human saliency to give fully-interpretable comparison outcomes for use in the context of forensic examination, achieving state-of-the-art recognition performance.
Interpretable Deep Learning-Based Forensic Iris Segmentation and Recognition
Dec 20, 2021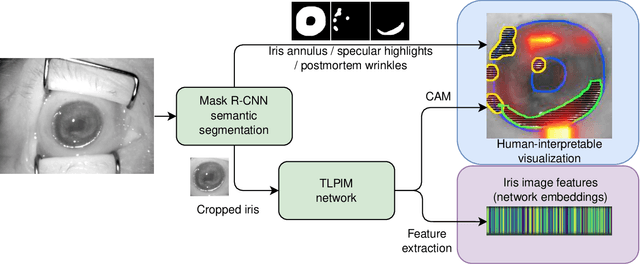

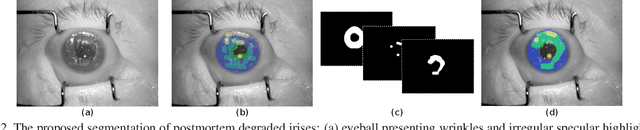
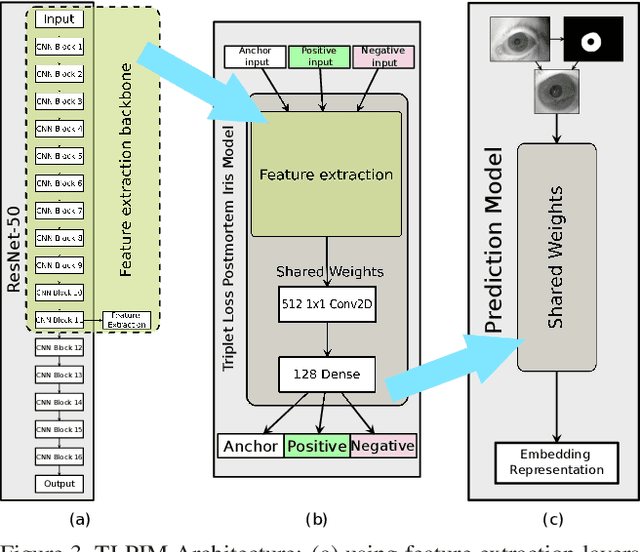
Iris recognition of living individuals is a mature biometric modality that has been adopted globally from governmental ID programs, border crossing, voter registration and de-duplication, to unlocking mobile phones. On the other hand, the possibility of recognizing deceased subjects with their iris patterns has emerged recently. In this paper, we present an end-to-end deep learning-based method for postmortem iris segmentation and recognition with a special visualization technique intended to support forensic human examiners in their efforts. The proposed postmortem iris segmentation approach outperforms the state of the art and in addition to iris annulus, as in case of classical iris segmentation methods - detects abnormal regions caused by eye decomposition processes, such as furrows or irregular specular highlights present on the drying and wrinkling cornea. The method was trained and validated with data acquired from 171 cadavers, kept in mortuary conditions, and tested on subject-disjoint data acquired from 259 deceased subjects. To our knowledge, this is the largest corpus of data used in postmortem iris recognition research to date. The source code of the proposed method are offered with the paper. The test data will be available through the National Archive of Criminal Justice Data (NACJD) archives.
Techniques and Applications for Crawling, Ingesting and Analyzing Blockchain Data
Sep 22, 2019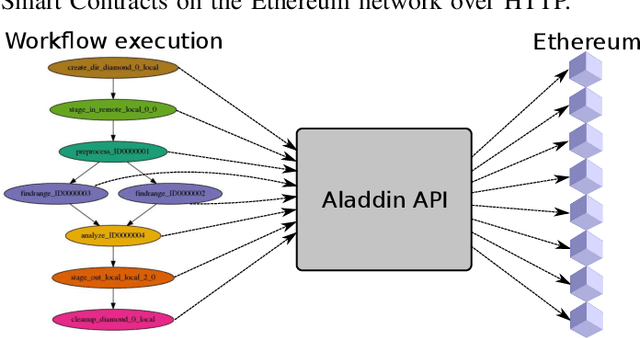
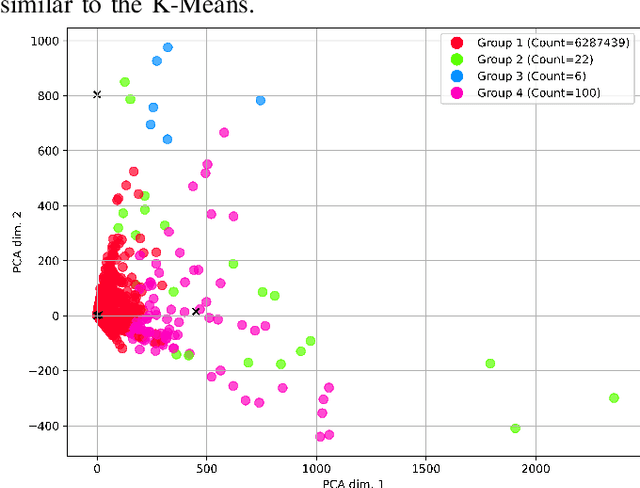
As the public Ethereum network surpasses half a billion transactions and enterprise Blockchain systems becoming highly capable of meeting the demands of global deployments, production Blockchain applications are fast becoming commonplace across a diverse range of business and scientific verticals. In this paper, we reflect on work we have been conducting recently surrounding the ingestion, retrieval and analysis of Blockchain data. We describe the scaling and semantic challenges when extracting Blockchain data in a way that preserves the original metadata of each transaction by cross referencing the Smart Contract interface with the on-chain data. We then discuss a scientific use case in the area of Scientific workflows by describing how we can harvest data from tasks and dependencies in a generic way. We then discuss how crawled public blockchain data can be analyzed using two unsupervised machine learning algorithms, which are designed to identify outlier accounts or smart contracts in the system. We compare and contrast the two machine learning methods and cross correlate with public Websites to illustrate the effectiveness such approaches.
Ensemble of Multi-View Learning Classifiers for Cross-Domain Iris Presentation Attack Detection
Nov 25, 2018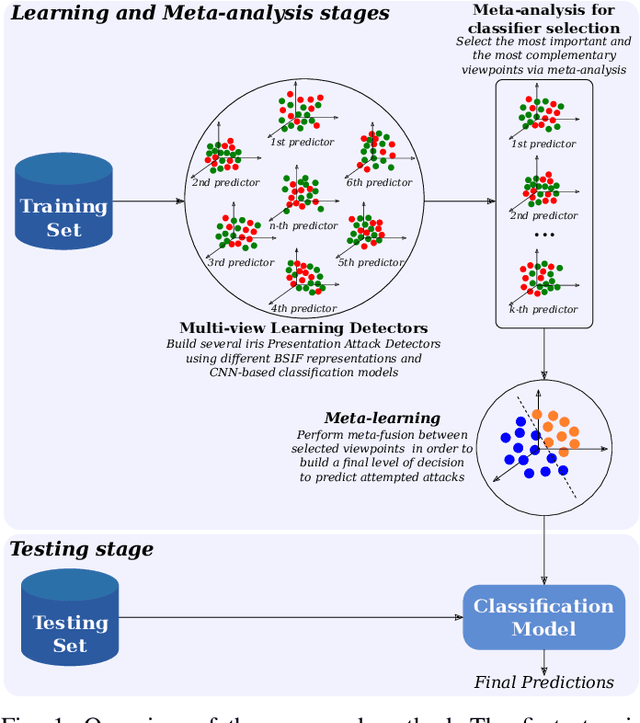
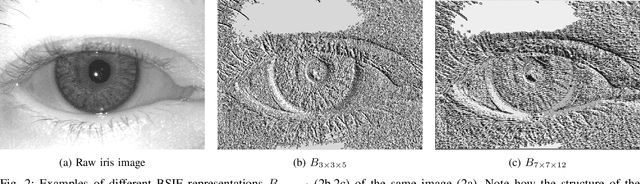
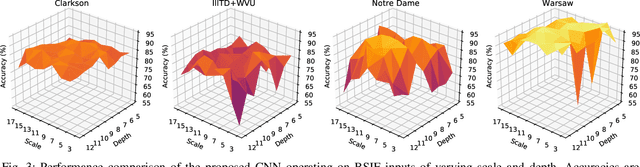
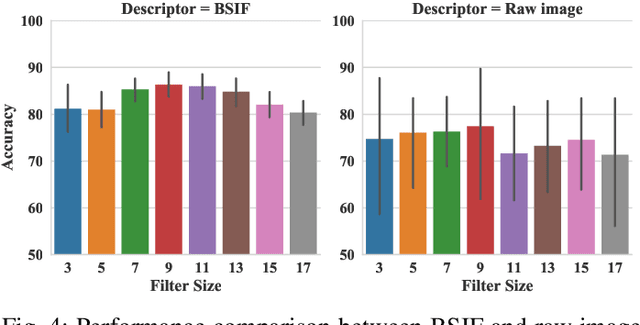
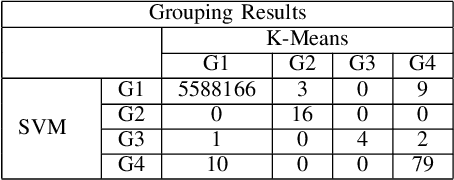
The adoption of large-scale iris recognition systems around the world has brought to light the importance of detecting presentation attack images (textured contact lenses and printouts). This work presents a new approach in iris Presentation Attack Detection (PAD), by exploring combinations of Convolutional Neural Networks (CNNs) and transformed input spaces through binarized statistical image features (BSIF). Our method combines lightweight CNNs to classify multiple BSIF views of the input image. Following explorations on complementary input spaces leading to more discriminative features to detect presentation attacks, we also propose an algorithm to select the best (and most discriminative) predictors for the task at hand.An ensemble of predictors makes use of their expected individual performances to aggregate their results into a final prediction. Results show that this technique improves on the current state of the art in iris PAD, outperforming the winner of LivDet-Iris2017 competition both for intra- and cross-dataset scenarios, and illustrating the very difficult nature of the cross-dataset scenario.
Predicting Gender from Iris Texture May Be Harder Than It Seems
Nov 25, 2018
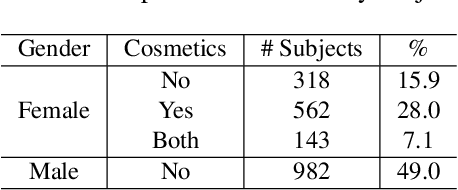
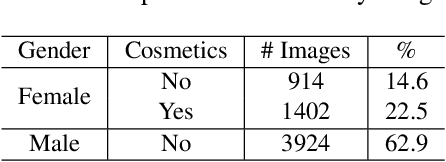
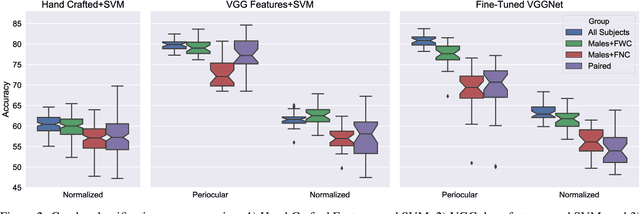
Predicting gender from iris images has been reported by several researchers as an application of machine learning in biometrics. Recent works on this topic have suggested that the preponderance of the gender cues is located in the periocular region rather than in the iris texture itself. This paper focuses on teasing out whether the information for gender prediction is in the texture of the iris stroma, the periocular region, or both. We present a larger dataset for gender from iris, and evaluate gender prediction accuracy using linear SVM and CNN, comparing hand-crafted and deep features. We use probabilistic occlusion masking to gain insight on the problem. Results suggest the discriminative power of the iris texture for gender is weaker than previously thought, and that the gender-related information is primarily in the periocular region.
Found a good match: should I keep searching? - Accuracy and Performance in Iris Matching Using 1-to-First Search
Mar 22, 2018
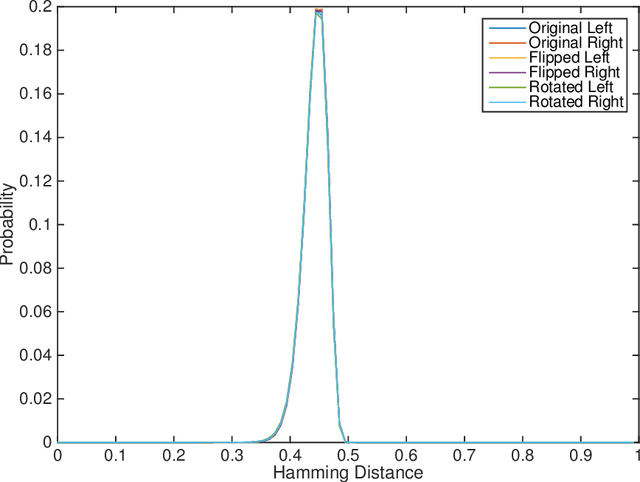
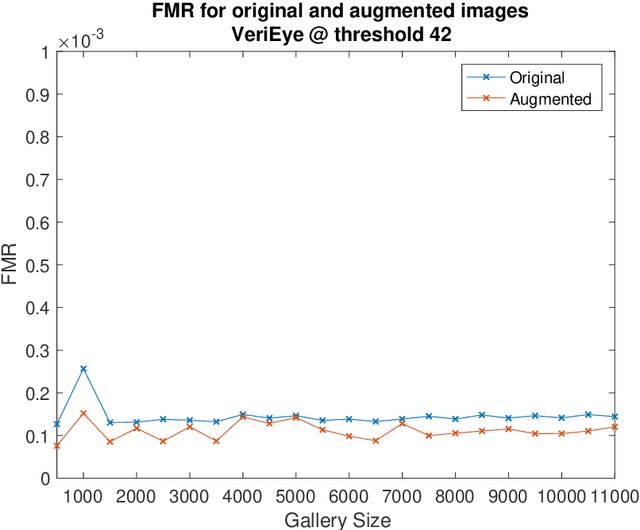
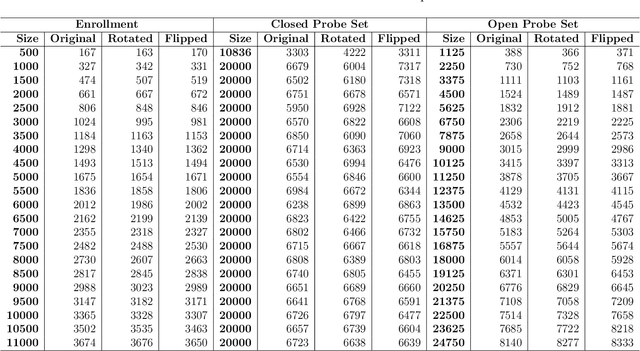
Iris recognition is used in many applications around the world, with enrollment sizes as large as over one billion persons in India's Aadhaar program. Large enrollment sizes can require special optimizations in order to achieve fast database searches. One such optimization that has been used in some operational scenarios is 1:First search. In this approach, instead of scanning the entire database, the search is terminated when the first sufficiently good match is found. This saves time, but ignores potentially better matches that may exist in the unexamined portion of the enrollments. At least one prominent and successful border-crossing program used this approach for nearly a decade, in order to allow users a fast "token-free" search. Our work investigates the search accuracy of 1:First and compares it to the traditional 1:N search. Several different scenarios are considered trying to emulate real environments as best as possible: a range of enrollment sizes, closed- and open-set configurations, two iris matchers, and different permutations of the galleries. Results confirm the expected accuracy degradation using 1:First search, and also allow us to identify acceptable working parameters where significant search time reduction is achieved, while maintaining accuracy similar to 1:N search.
Gender-From-Iris or Gender-From-Mascara?
Feb 04, 2017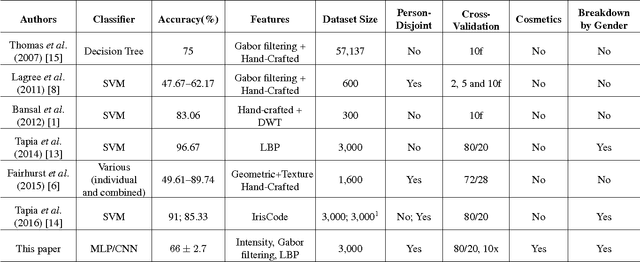
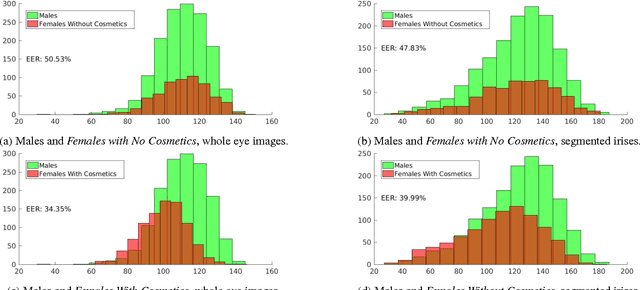
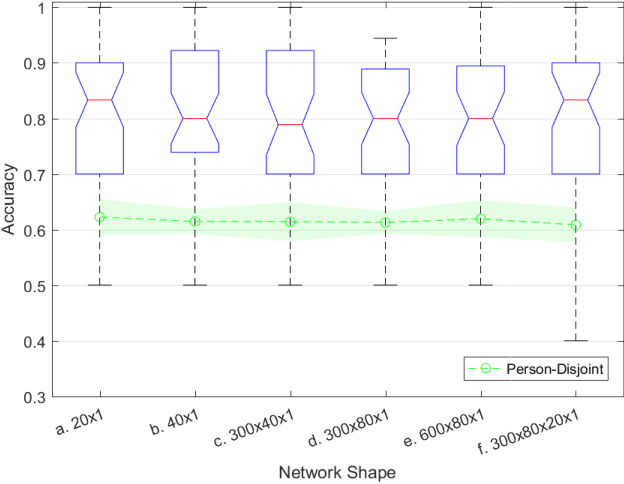
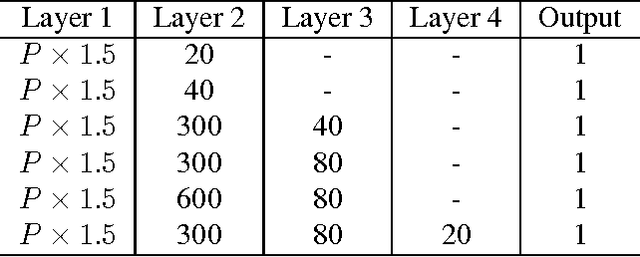
Predicting a person's gender based on the iris texture has been explored by several researchers. This paper considers several dimensions of experimental work on this problem, including person-disjoint train and test, and the effect of cosmetics on eyelash occlusion and imperfect segmentation. We also consider the use of multi-layer perceptron and convolutional neural networks as classifiers, comparing the use of data-driven and hand-crafted features. Our results suggest that the gender-from-iris problem is more difficult than has so far been appreciated. Estimating accuracy using a mean of N person-disjoint train and test partitions, and considering the effect of makeup - a combination of experimental conditions not present in any previous work - we find a much weaker ability to predict gender-from-iris texture than has been suggested in previous work.
An Analysis of 1-to-First Matching in Iris Recognition
Feb 03, 2017
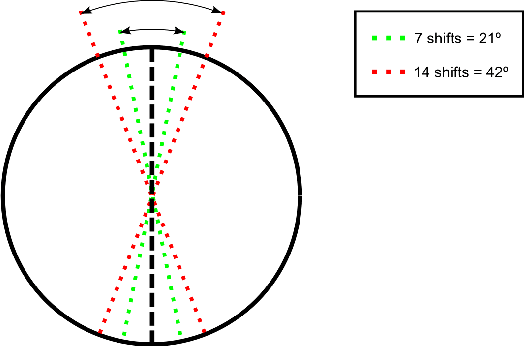
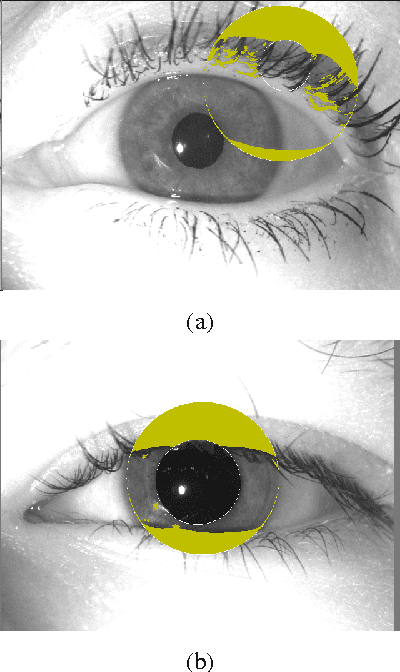
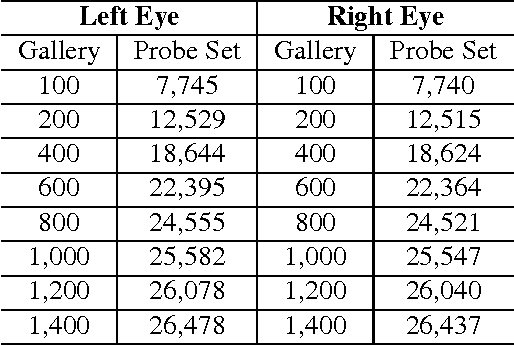
Iris recognition systems are a mature technology that is widely used throughout the world. In identification (as opposed to verification) mode, an iris to be recognized is typically matched against all N enrolled irises. This is the classic "1-to-N search". In order to improve the speed of large-scale identification, a modified "1-to-First" search has been used in some operational systems. A 1-to-First search terminates with the first below-threshold match that is found, whereas a 1-to-N search always finds the best match across all enrollments. We know of no previous studies that evaluate how the accuracy of 1-to-First search differs from that of 1-to-N search. Using a dataset of over 50,000 iris images from 2,800 different irises, we perform experiments to evaluate the relative accuracy of 1-to-First and 1-to-N search. We evaluate how the accuracy difference changes with larger numbers of enrolled irises, and with larger ranges of rotational difference allowed between iris images. We find that False Match error rate for 1-to-First is higher than for 1-to-N, and the the difference grows with larger number of enrolled irises and with larger range of rotation.