 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADRD-Bench: A Preliminary LLM Benchmark for Alzheimer's Disease and Related Dementias
Feb 12, 2026Large language models (LLMs) have shown great potential for healthcare applications. However, existing evaluation benchmarks provide minimal coverage of Alzheimer's Disease and Related Dementias (ADRD). To address this gap, we introduce ADRD-Bench, the first ADRD-specific benchmark dataset designed for rigorous evaluation of LLMs. ADRD-Bench has two components: 1) ADRD Unified QA, a synthesis of 1,352 questions consolidated from seven established medical benchmarks, providing a unified assessment of clinical knowledge; and 2) ADRD Caregiving QA, a novel set of 149 questions derived from the Aging Brain Care (ABC) program, a widely used, evidence-based brain health management program. Guided by a program with national expertise in comprehensive ADRD care, this new set was designed to mitigate the lack of practical caregiving context in existing benchmarks. We evaluated 33 state-of-the-art LLMs on the proposed ADRD-Bench. Results showed that the accuracy of open-weight general models ranged from 0.63 to 0.93 (mean: 0.78; std: 0.09). The accuracy of open-weight medical models ranged from 0.48 to 0.93 (mean: 0.82; std: 0.13). The accuracy of closed-source general models ranged from 0.83 to 0.91 (mean: 0.89; std: 0.03). While top-tier models achieved high accuracies (>0.9), case studies revealed that inconsistent reasoning quality and stability limit their reliability, highlighting a critical need for domain-specific improvement to enhance LLMs' knowledge and reasoning grounded in daily caregiving data. The entire dataset is available at https://github.com/IIRL-ND/ADRD-Bench.
Stablecoin Design with Adversarial-Robust Multi-Agent Systems via Trust-Weighted Signal Aggregation
Jan 18, 2026Algorithmic stablecoins promise decentralized monetary stability by maintaining a target peg through programmatic reserve management. Yet, their reserve controllers remain vulnerable to regime-blind optimization, calibrating risk parameters on fair-weather data while ignoring tail events that precipitate cascading failures. The March 2020 Black Thursday collapse, wherein MakerDAO's collateral auctions yielded $8.3M in losses and a 15% peg deviation, exposed a critical gap: existing models like SAS systematically omit extreme volatility regimes from covariance estimates, producing allocations optimal in expectation but catastrophic under adversarial stress. We present MVF-Composer, a trust-weighted Mean-Variance Frontier reserve controller incorporating a novel Stress Harness for risk-state estimation. Our key insight is deploying multi-agent simulations as adversarial stress-testers: heterogeneous agents (traders, liquidity providers, attackers) execute protocol actions under crisis scenarios, exposing reserve vulnerabilities before they manifest on-chain. We formalize a trust-scoring mechanism T: A -> [0,1] that down-weights signals from agents exhibiting manipulative behavior, ensuring the risk-state estimator remains robust to signal injection and Sybil attacks. Across 1,200 randomized scenarios with injected Black-Swan shocks (10% collateral drawdown, 50% sentiment collapse, coordinated redemption attacks), MVF-Composer reduces peak peg deviation by 57% and mean recovery time by 3.1x relative to SAS baselines. Ablation studies confirm the trust layer accounts for 23% of stability gains under adversarial conditions, achieving 72% adversarial agent detection. Our system runs on commodity hardware, requires no on-chain oracles beyond standard price feeds, and provides a reproducible framework for stress-testing DeFi reserve policies.
Providing Assurance and Scrutability on Shared Data and Machine Learning Models with Verifiable Credentials
May 13, 2021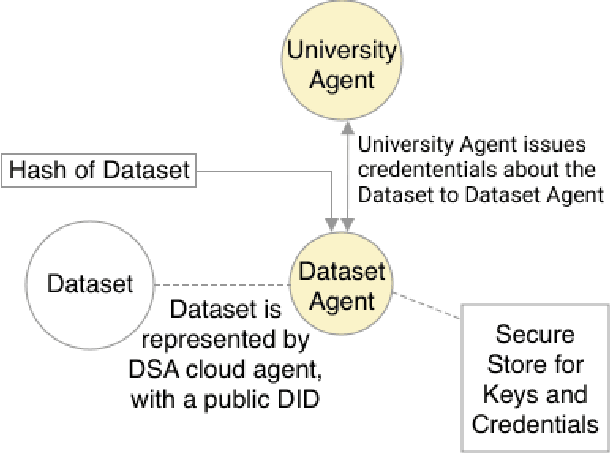
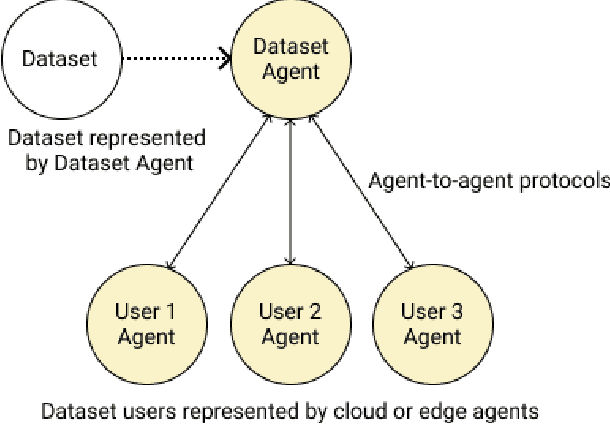
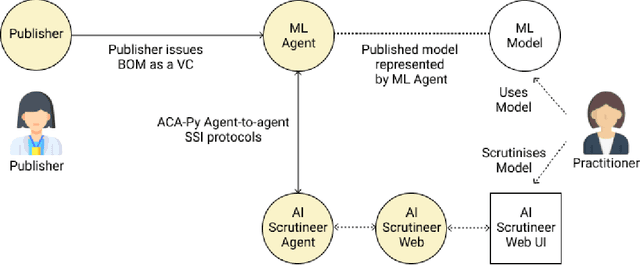
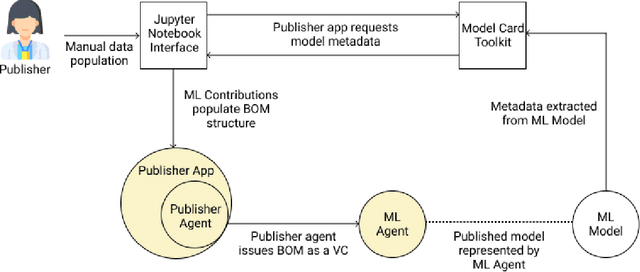
Adopting shared data resources requires scientists to place trust in the originators of the data. When shared data is later used in the development of artificial intelligence (AI) systems or machine learning (ML) models, the trust lineage extends to the users of the system, typically practitioners in fields such as healthcare and finance. Practitioners rely on AI developers to have used relevant, trustworthy data, but may have limited insight and recourse. This paper introduces a software architecture and implementation of a system based on design patterns from the field of self-sovereign identity. Scientists can issue signed credentials attesting to qualities of their data resources. Data contributions to ML models are recorded in a bill of materials (BOM), which is stored with the model as a verifiable credential. The BOM provides a traceable record of the supply chain for an AI system, which facilitates on-going scrutiny of the qualities of the contributing components. The verified BOM, and its linkage to certified data qualities, is used in the AI Scrutineer, a web-based tool designed to offer practitioners insight into ML model constituents and highlight any problems with adopted datasets, should they be found to have biased data or be otherwise discredited.
Techniques and Applications for Crawling, Ingesting and Analyzing Blockchain Data
Sep 22, 2019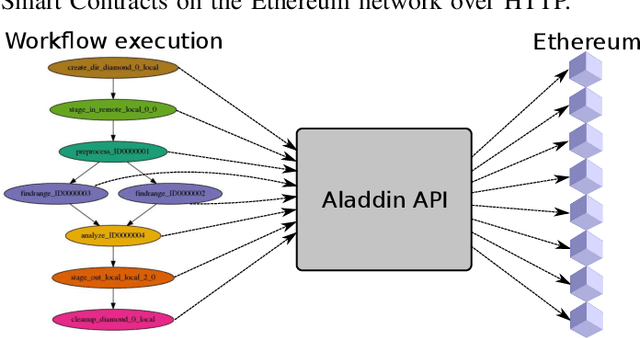
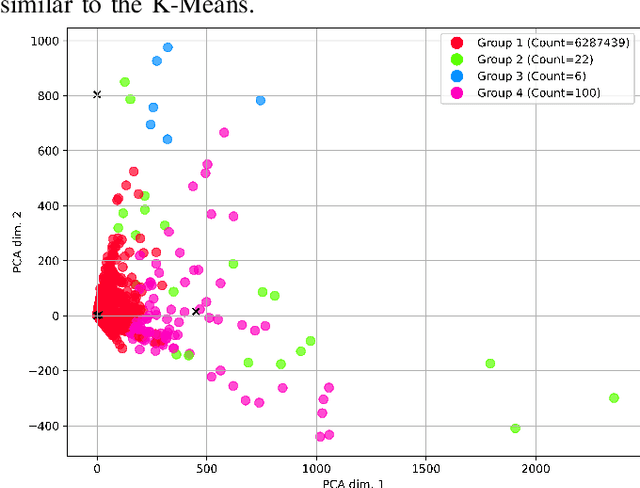
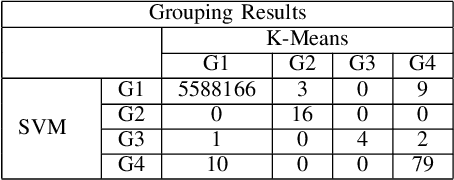
As the public Ethereum network surpasses half a billion transactions and enterprise Blockchain systems becoming highly capable of meeting the demands of global deployments, production Blockchain applications are fast becoming commonplace across a diverse range of business and scientific verticals. In this paper, we reflect on work we have been conducting recently surrounding the ingestion, retrieval and analysis of Blockchain data. We describe the scaling and semantic challenges when extracting Blockchain data in a way that preserves the original metadata of each transaction by cross referencing the Smart Contract interface with the on-chain data. We then discuss a scientific use case in the area of Scientific workflows by describing how we can harvest data from tasks and dependencies in a generic way. We then discuss how crawled public blockchain data can be analyzed using two unsupervised machine learning algorithms, which are designed to identify outlier accounts or smart contracts in the system. We compare and contrast the two machine learning methods and cross correlate with public Websites to illustrate the effectiveness such approaches.