 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechniques and Applications for Crawling, Ingesting and Analyzing Blockchain Data
Paper and Code
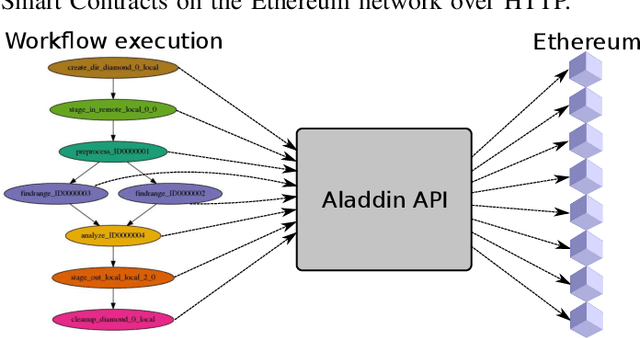
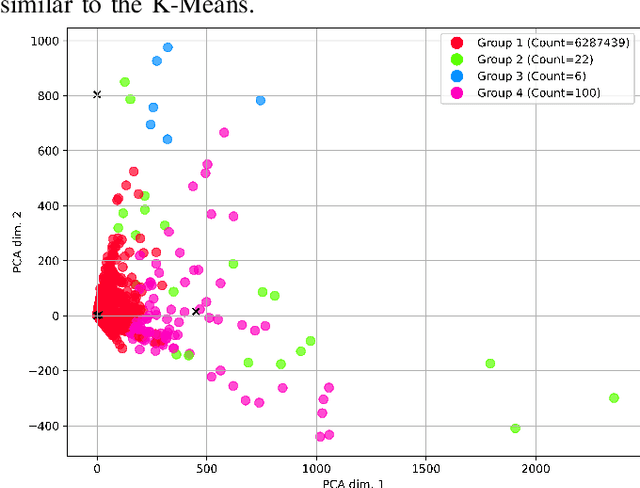
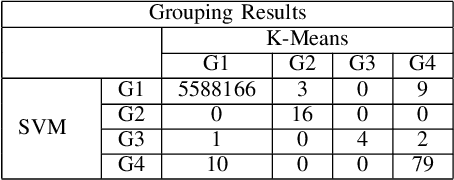
As the public Ethereum network surpasses half a billion transactions and enterprise Blockchain systems becoming highly capable of meeting the demands of global deployments, production Blockchain applications are fast becoming commonplace across a diverse range of business and scientific verticals. In this paper, we reflect on work we have been conducting recently surrounding the ingestion, retrieval and analysis of Blockchain data. We describe the scaling and semantic challenges when extracting Blockchain data in a way that preserves the original metadata of each transaction by cross referencing the Smart Contract interface with the on-chain data. We then discuss a scientific use case in the area of Scientific workflows by describing how we can harvest data from tasks and dependencies in a generic way. We then discuss how crawled public blockchain data can be analyzed using two unsupervised machine learning algorithms, which are designed to identify outlier accounts or smart contracts in the system. We compare and contrast the two machine learning methods and cross correlate with public Websites to illustrate the effectiveness such approaches.