 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFound a good match: should I keep searching? - Accuracy and Performance in Iris Matching Using 1-to-First Search
Paper and Code
Mar 22, 2018
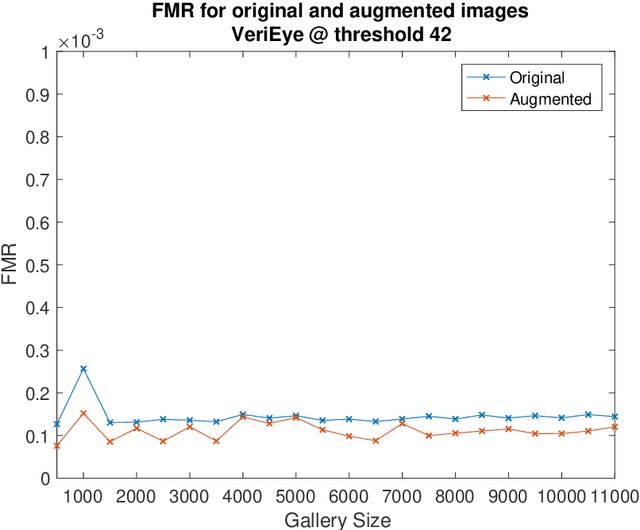
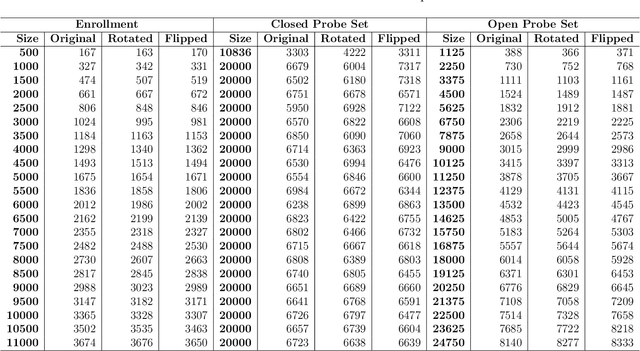
Iris recognition is used in many applications around the world, with enrollment sizes as large as over one billion persons in India's Aadhaar program. Large enrollment sizes can require special optimizations in order to achieve fast database searches. One such optimization that has been used in some operational scenarios is 1:First search. In this approach, instead of scanning the entire database, the search is terminated when the first sufficiently good match is found. This saves time, but ignores potentially better matches that may exist in the unexamined portion of the enrollments. At least one prominent and successful border-crossing program used this approach for nearly a decade, in order to allow users a fast "token-free" search. Our work investigates the search accuracy of 1:First and compares it to the traditional 1:N search. Several different scenarios are considered trying to emulate real environments as best as possible: a range of enrollment sizes, closed- and open-set configurations, two iris matchers, and different permutations of the galleries. Results confirm the expected accuracy degradation using 1:First search, and also allow us to identify acceptable working parameters where significant search time reduction is achieved, while maintaining accuracy similar to 1:N search.